 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic is all you need: removing the auxiliary data assumption for membership inference attacks against synthetic data
Paper and Code
Jul 04, 2023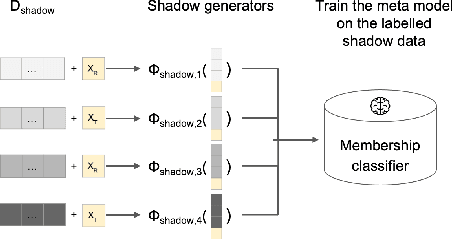
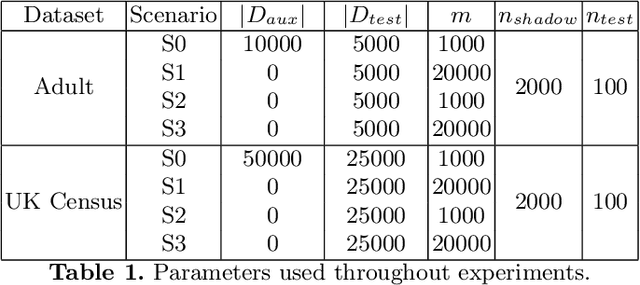
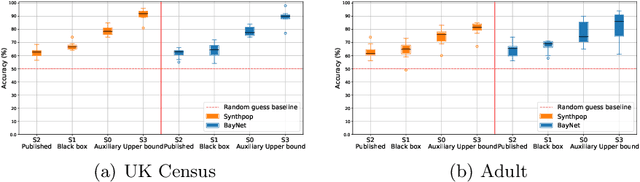
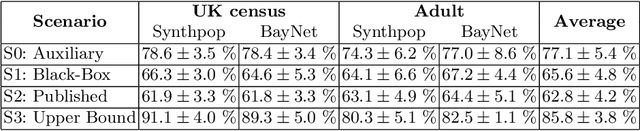
Synthetic data is emerging as the most promising solution to share individual-level data while safeguarding privacy. Membership inference attacks (MIAs), based on shadow modeling, have become the standard to evaluate the privacy of synthetic data. These attacks, however, currently assume the attacker to have access to an auxiliary dataset sampled from a similar distribution as the training dataset. This often is a very strong assumption that would make an attack unlikely to happen in practice. We here show how this assumption can be removed and how MIAs can be performed using only the synthetic data. More specifically, in three different attack scenarios using only synthetic data, our results demonstrate that MIAs are still successful, across two real-world datasets and two synthetic data generators. These results show how the strong hypothesis made when auditing synthetic data releases - access to an auxiliary dataset - can be relaxed to perform an actual attack.