 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Strategic Queuing Systems with Small Buffers
Feb 13, 2025Routers in networking use simple learning algorithms to find the best way to deliver packets to their desired destination. This simple, myopic and distributed decision system makes large queuing systems simple to operate, but at the same time, the system needs more capacity than would be required if all traffic were centrally coordinated. In a recent paper, Gaitonde and Tardos (EC 2020 and JACM 2023) initiate the study of such systems, modeling them as an infinitely repeated game in which routers compete for servers and the system maintains a state (number of packets held by each queue) resulting from outcomes of previous rounds. Queues get to send a packet at each step to one of the servers, and servers attempt to process only one of the arriving packets, modeling routers. However, their model assumes that servers have no buffers at all, so queues have to resend all packets that were not served successfully. They show that, even with hugely increased server capacity relative to what is needed in the centrally-coordinated case, ensuring that the system is stable requires using timestamps and priority for older packets. We consider a system with two important changes, which make the model more realistic: first we add a very small buffer to each server, allowing it to hold on to a single packet to be served later (even if it fails to serve it); and second, we do not require timestamps or priority for older packets. Our main result is to show that when queues are learning, a small constant factor increase in server capacity, compared to what would be needed if centrally coordinating, suffices to keep the system stable, even if servers select randomly among packets arriving simultaneously. This work contributes to the growing literature on the impact of selfish learning in systems with carryover effects between rounds: when outcomes in the present round affect the game in the future.
Learning in Markets with Heterogeneous Agents: Dynamics and Survival of Bayesian vs. No-Regret Learners
Feb 12, 2025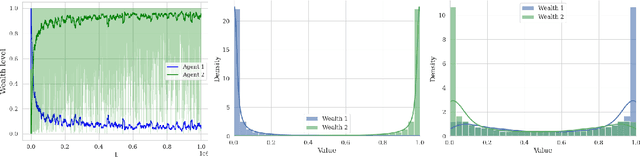
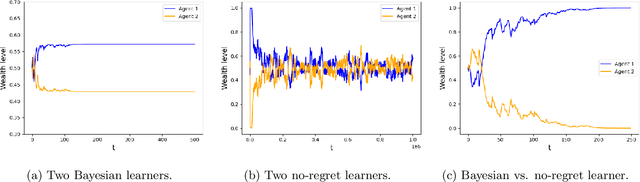
We analyze the performance of heterogeneous learning agents in asset markets with stochastic payoffs. Our agents aim to maximize the expected growth rate of their wealth but have different theories on how to learn this best. We focus on comparing Bayesian and no-regret learners in market dynamics. Bayesian learners with a prior over a finite set of models that assign positive prior probability to the correct model have posterior probabilities that converge exponentially to the correct model. Consequently, they survive even in the presence of agents who invest according to the correct model of the stochastic process. Bayesians with a continuum prior converge to the correct model at a rate of $O((\log T)/T)$. Online learning theory provides no-regret algorithms for maximizing the log of wealth in this setting, achieving a worst-case regret bound of $O(\log T)$ without assuming a steady underlying stochastic process but comparing to the best fixed investment rule. This regret, as we observe, is of the same order of magnitude as that of a Bayesian learner with a continuum prior. However, we show that even such low regret may not be sufficient for survival in asset markets: an agent can have regret as low as $O(\log T)$, but still vanish in market dynamics when competing against agents who invest according to the correct model or even against a perfect Bayesian with a finite prior. On the other hand, we show that Bayesian learning is fragile, while no-regret learning requires less knowledge of the environment and is therefore more robust. Any no-regret learner will drive out of the market an imperfect Bayesian whose finite prior or update rule has even small errors. We formally establish the relationship between notions of survival, vanishing, and market domination studied in economics and the framework of regret minimization, thus bridging these theories.
Learning in Budgeted Auctions with Spacing Objectives
Nov 07, 2024In many repeated auction settings, participants care not only about how frequently they win but also how their winnings are distributed over time. This problem arises in various practical domains where avoiding congested demand is crucial, such as online retail sales and compute services, as well as in advertising campaigns that require sustained visibility over time. We introduce a simple model of this phenomenon, modeling it as a budgeted auction where the value of a win is a concave function of the time since the last win. This implies that for a given number of wins, even spacing over time is optimal. We also extend our model and results to the case when not all wins result in "conversions" (realization of actual gains), and the probability of conversion depends on a context. The goal is to maximize and evenly space conversions rather than just wins. We study the optimal policies for this setting in second-price auctions and offer learning algorithms for the bidders that achieve low regret against the optimal bidding policy in a Bayesian online setting. Our main result is a computationally efficient online learning algorithm that achieves $\tilde O(\sqrt T)$ regret. We achieve this by showing that an infinite-horizon Markov decision process (MDP) with the budget constraint in expectation is essentially equivalent to our problem, even when limiting that MDP to a very small number of states. The algorithm achieves low regret by learning a bidding policy that chooses bids as a function of the context and the system's state, which will be the time elapsed since the last win (or conversion). We show that state-independent strategies incur linear regret even without uncertainty of conversions. We complement this by showing that there are state-independent strategies that, while still having linear regret, achieve a $(1-\frac 1 e)$ approximation to the optimal reward.
Paying to Do Better: Games with Payments between Learning Agents
May 31, 2024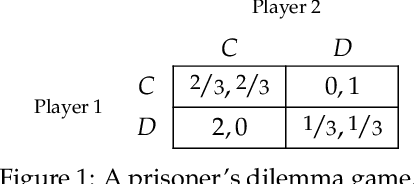
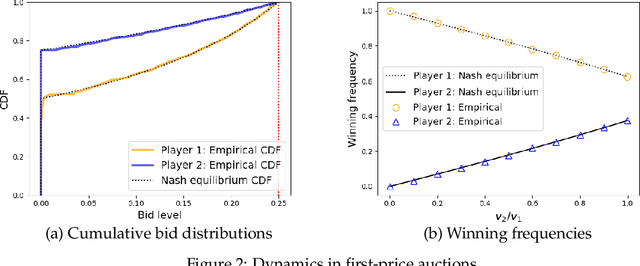
In repeated games, such as auctions, players typically use learning algorithms to choose their actions. The use of such autonomous learning agents has become widespread on online platforms. In this paper, we explore the impact of players incorporating monetary transfers into their agents' algorithms, aiming to incentivize behavior in their favor. Our focus is on understanding when players have incentives to make use of monetary transfers, how these payments affect learning dynamics, and what the implications are for welfare and its distribution among the players. We propose a simple game-theoretic model to capture such scenarios. Our results on general games show that in a broad class of games, players benefit from letting their learning agents make payments to other learners during the game dynamics, and that in many cases, this kind of behavior improves welfare for all players. Our results on first- and second-price auctions show that in equilibria of the ``payment policy game,'' the agents' dynamics can reach strong collusive outcomes with low revenue for the auctioneer. These results highlight a challenge for mechanism design in systems where automated learning agents can benefit from interacting with their peers outside the boundaries of the mechanism.
Contracting with a Learning Agent
Jan 29, 2024Many real-life contractual relations differ completely from the clean, static model at the heart of principal-agent theory. Typically, they involve repeated strategic interactions of the principal and agent, taking place under uncertainty and over time. While appealing in theory, players seldom use complex dynamic strategies in practice, often preferring to circumvent complexity and approach uncertainty through learning. We initiate the study of repeated contracts with a learning agent, focusing on agents who achieve no-regret outcomes. Optimizing against a no-regret agent is a known open problem in general games; we achieve an optimal solution to this problem for a canonical contract setting, in which the agent's choice among multiple actions leads to success/failure. The solution has a surprisingly simple structure: for some $\alpha > 0$, initially offer the agent a linear contract with scalar $\alpha$, then switch to offering a linear contract with scalar $0$. This switch causes the agent to ``free-fall'' through their action space and during this time provides the principal with non-zero reward at zero cost. Despite apparent exploitation of the agent, this dynamic contract can leave \emph{both} players better off compared to the best static contract. Our results generalize beyond success/failure, to arbitrary non-linear contracts which the principal rescales dynamically. Finally, we quantify the dependence of our results on knowledge of the time horizon, and are the first to address this consideration in the study of strategizing against learning agents.
Explainable Reinforcement Learning via Model Transforms
Sep 24, 2022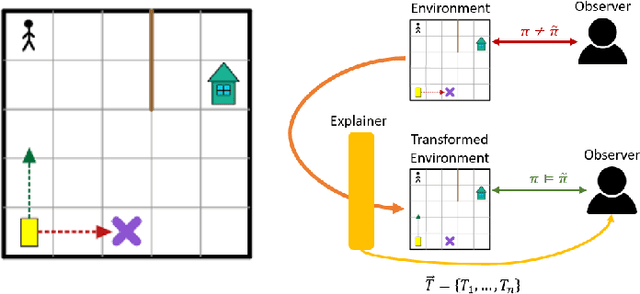
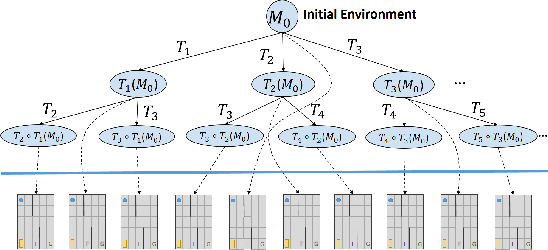
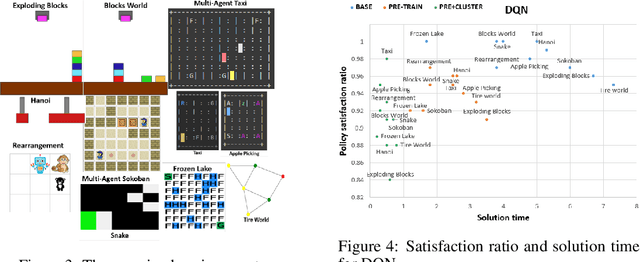
Understanding emerging behaviors of reinforcement learning (RL) agents may be difficult since such agents are often trained in complex environments using highly complex decision making procedures. This has given rise to a variety of approaches to explainability in RL that aim to reconcile discrepancies that may arise between the behavior of an agent and the behavior that is anticipated by an observer. Most recent approaches have relied either on domain knowledge, that may not always be available, on an analysis of the agent's policy, or on an analysis of specific elements of the underlying environment, typically modeled as a Markov Decision Process (MDP). Our key claim is that even if the underlying MDP is not fully known (e.g., the transition probabilities have not been accurately learned) or is not maintained by the agent (i.e., when using model-free methods), it can nevertheless be exploited to automatically generate explanations. For this purpose, we suggest using formal MDP abstractions and transforms, previously used in the literature for expediting the search for optimal policies, to automatically produce explanations. Since such transforms are typically based on a symbolic representation of the environment, they may represent meaningful explanations for gaps between the anticipated and actual agent behavior. We formally define this problem, suggest a class of transforms that can be used for explaining emergent behaviors, and suggest methods that enable efficient search for an explanation. We demonstrate the approach on a set of standard benchmarks.
How and Why to Manipulate Your Own Agent
Dec 14, 2021
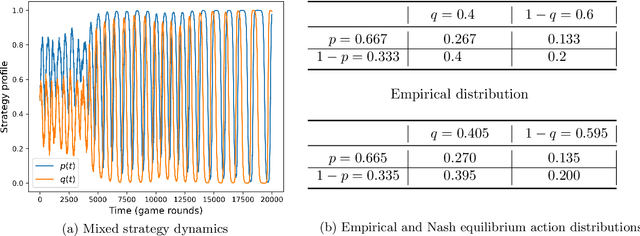

We consider strategic settings where several users engage in a repeated online interaction, assisted by regret-minimizing agents that repeatedly play a "game" on their behalf. We study the dynamics and average outcomes of the repeated game of the agents, and view it as inducing a meta-game between the users. Our main focus is on whether users can benefit in this meta-game from "manipulating" their own agent by mis-reporting their parameters to it. We formally define this "user-agent meta-game" model for general games, discuss its properties under different notions of convergence of the dynamics of the automated agents and analyze the equilibria induced on the users in 2x2 games in which the dynamics converge to a single equilibrium.
Auctions Between Regret-Minimizing Agents
Oct 22, 2021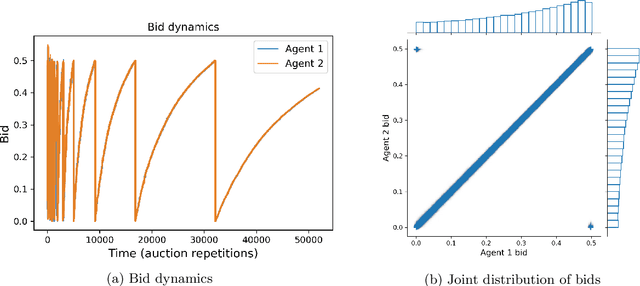

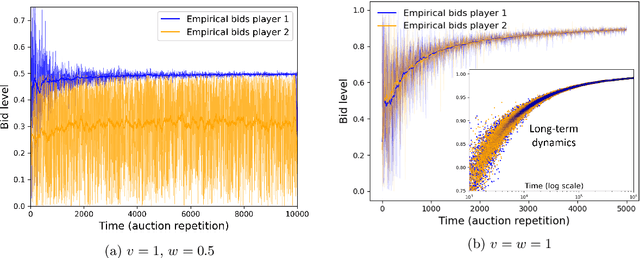

We analyze a scenario in which software agents implemented as regret minimizing algorithms engage in a repeated auction on behalf of their users. We study first price and second price auctions, as well as their generalized versions (e.g., as those used for ad auctions). Using both theoretical analysis and simulations, we show that, surprisingly, in second price auctions the players have incentives to mis-report their true valuations to their own learning agents, while in the first price auction it is a dominant strategy for all players to truthfully report their valuations to their agents.
Neural Networks for Predicting Human Interactions in Repeated Games
Nov 08, 2019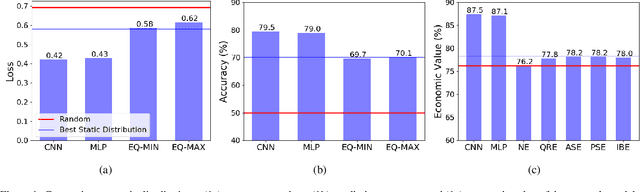
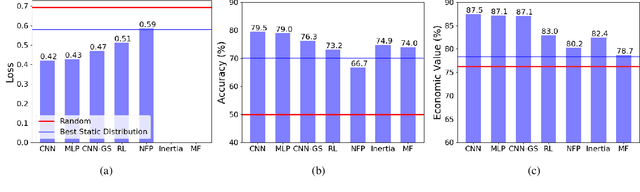
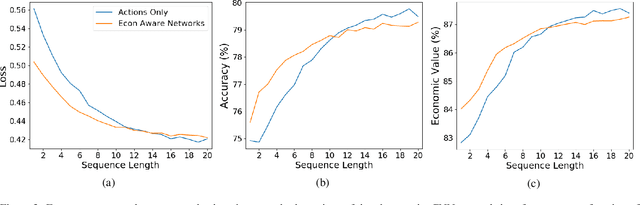
We consider the problem of predicting human players' actions in repeated strategic interactions. Our goal is to predict the dynamic step-by-step behavior of individual players in previously unseen games. We study the ability of neural networks to perform such predictions and the information that they require. We show on a dataset of normal-form games from experiments with human participants that standard neural networks are able to learn functions that provide more accurate predictions of the players' actions than established models from behavioral economics. The networks outperform the other models in terms of prediction accuracy and cross-entropy, and yield higher economic value. We show that if the available input is only of a short sequence of play, economic information about the game is important for predicting behavior of human agents. However, interestingly, we find that when the networks are trained with long enough sequences of history of play, action-based networks do well and additional economic details about the game do not improve their performance, indicating that the sequence of actions encode sufficient information for the success in the prediction task.
Behavior-Based Machine-Learning: A Hybrid Approach for Predicting Human Decision Making
Nov 30, 2016A large body of work in behavioral fields attempts to develop models that describe the way people, as opposed to rational agents, make decisions. A recent Choice Prediction Competition (2015) challenged researchers to suggest a model that captures 14 classic choice biases and can predict human decisions under risk and ambiguity. The competition focused on simple decision problems, in which human subjects were asked to repeatedly choose between two gamble options. In this paper we present our approach for predicting human decision behavior: we suggest to use machine learning algorithms with features that are based on well-established behavioral theories. The basic idea is that these psychological features are essential for the representation of the data and are important for the success of the learning process. We implement a vanilla model in which we train SVM models using behavioral features that rely on the psychological properties underlying the competition baseline model. We show that this basic model captures the 14 choice biases and outperforms all the other learning-based models in the competition. The preliminary results suggest that such hybrid models can significantly improve the prediction of human decision making, and are a promising direction for future research.