 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Budgeted Auctions with Spacing Objectives
Nov 07, 2024In many repeated auction settings, participants care not only about how frequently they win but also how their winnings are distributed over time. This problem arises in various practical domains where avoiding congested demand is crucial, such as online retail sales and compute services, as well as in advertising campaigns that require sustained visibility over time. We introduce a simple model of this phenomenon, modeling it as a budgeted auction where the value of a win is a concave function of the time since the last win. This implies that for a given number of wins, even spacing over time is optimal. We also extend our model and results to the case when not all wins result in "conversions" (realization of actual gains), and the probability of conversion depends on a context. The goal is to maximize and evenly space conversions rather than just wins. We study the optimal policies for this setting in second-price auctions and offer learning algorithms for the bidders that achieve low regret against the optimal bidding policy in a Bayesian online setting. Our main result is a computationally efficient online learning algorithm that achieves $\tilde O(\sqrt T)$ regret. We achieve this by showing that an infinite-horizon Markov decision process (MDP) with the budget constraint in expectation is essentially equivalent to our problem, even when limiting that MDP to a very small number of states. The algorithm achieves low regret by learning a bidding policy that chooses bids as a function of the context and the system's state, which will be the time elapsed since the last win (or conversion). We show that state-independent strategies incur linear regret even without uncertainty of conversions. We complement this by showing that there are state-independent strategies that, while still having linear regret, achieve a $(1-\frac 1 e)$ approximation to the optimal reward.
Paying to Do Better: Games with Payments between Learning Agents
May 31, 2024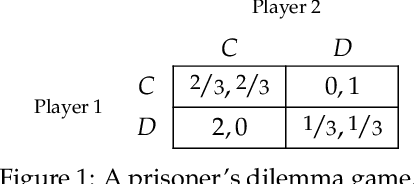
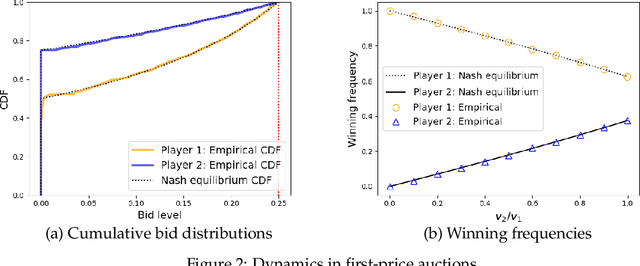
In repeated games, such as auctions, players typically use learning algorithms to choose their actions. The use of such autonomous learning agents has become widespread on online platforms. In this paper, we explore the impact of players incorporating monetary transfers into their agents' algorithms, aiming to incentivize behavior in their favor. Our focus is on understanding when players have incentives to make use of monetary transfers, how these payments affect learning dynamics, and what the implications are for welfare and its distribution among the players. We propose a simple game-theoretic model to capture such scenarios. Our results on general games show that in a broad class of games, players benefit from letting their learning agents make payments to other learners during the game dynamics, and that in many cases, this kind of behavior improves welfare for all players. Our results on first- and second-price auctions show that in equilibria of the ``payment policy game,'' the agents' dynamics can reach strong collusive outcomes with low revenue for the auctioneer. These results highlight a challenge for mechanism design in systems where automated learning agents can benefit from interacting with their peers outside the boundaries of the mechanism.
Approximately Stationary Bandits with Knapsacks
Feb 28, 2023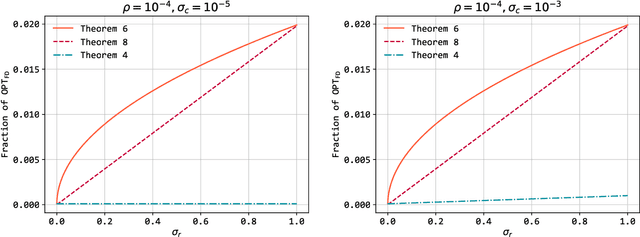

Bandits with Knapsacks (BwK), the generalization of the Multi-Armed Bandits under budget constraints, has received a lot of attention in recent years. It has numerous applications, including dynamic pricing, repeated auctions, etc. Previous work has focused on one of the two extremes: Stochastic BwK where the rewards and consumptions of the resources each round are sampled from an i.i.d. distribution, and Adversarial BwK where these values are picked by an adversary. Achievable guarantees in the two cases exhibit a massive gap: No-regret learning is achievable in Stochastic BwK, but in Adversarial BwK, only competitive ratio style guarantees are achievable, where the competitive ratio depends on the budget. What makes this gap so vast is that in Adversarial BwK the guarantees get worse in the typical case when the budget is more binding. While ``best-of-both-worlds'' type algorithms are known (algorithms that provide the best achievable guarantee in both extreme cases), their guarantees degrade to the adversarial case as soon as the environment is not fully stochastic. Our work aims to bridge this gap, offering guarantees for a workload that is not exactly stochastic but is also not worst-case. We define a condition, Approximately Stationary BwK, that parameterizes how close to stochastic or adversarial an instance is. Based on these parameters, we explore what is the best competitive ratio attainable in BwK. We explore two algorithms that are oblivious to the values of the parameters but guarantee competitive ratios that smoothly transition between the best possible guarantees in the two extreme cases, depending on the values of the parameters. Our guarantees offer great improvement over the adversarial guarantee, especially when the available budget is small. We also prove bounds on the achievable guarantee, showing that our results are approximately tight when the budget is small.