 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaying to Do Better: Games with Payments between Learning Agents
May 31, 2024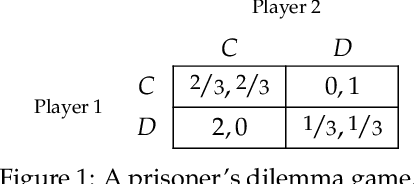
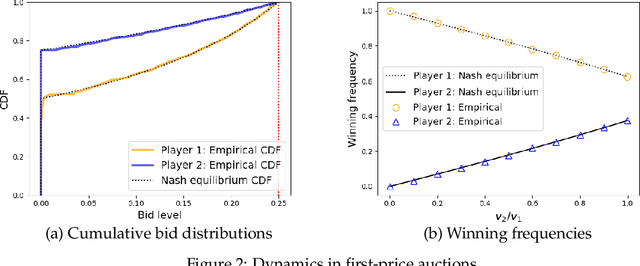
In repeated games, such as auctions, players typically use learning algorithms to choose their actions. The use of such autonomous learning agents has become widespread on online platforms. In this paper, we explore the impact of players incorporating monetary transfers into their agents' algorithms, aiming to incentivize behavior in their favor. Our focus is on understanding when players have incentives to make use of monetary transfers, how these payments affect learning dynamics, and what the implications are for welfare and its distribution among the players. We propose a simple game-theoretic model to capture such scenarios. Our results on general games show that in a broad class of games, players benefit from letting their learning agents make payments to other learners during the game dynamics, and that in many cases, this kind of behavior improves welfare for all players. Our results on first- and second-price auctions show that in equilibria of the ``payment policy game,'' the agents' dynamics can reach strong collusive outcomes with low revenue for the auctioneer. These results highlight a challenge for mechanism design in systems where automated learning agents can benefit from interacting with their peers outside the boundaries of the mechanism.
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
May 10, 2024



Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.