 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Adaptive Optimizers for Honest Private Hyperparameter Selection
Nov 09, 2021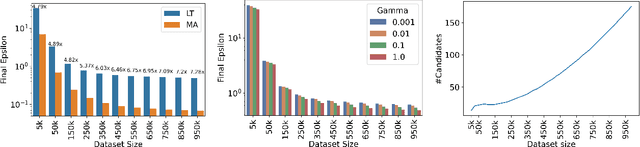


Hyperparameter optimization is a ubiquitous challenge in machine learning, and the performance of a trained model depends crucially upon their effective selection. While a rich set of tools exist for this purpose, there are currently no practical hyperparameter selection methods under the constraint of differential privacy (DP). We study honest hyperparameter selection for differentially private machine learning, in which the process of hyperparameter tuning is accounted for in the overall privacy budget. To this end, we i) show that standard composition tools outperform more advanced techniques in many settings, ii) empirically and theoretically demonstrate an intrinsic connection between the learning rate and clipping norm hyperparameters, iii) show that adaptive optimizers like DPAdam enjoy a significant advantage in the process of honest hyperparameter tuning, and iv) draw upon novel limiting behaviour of Adam in the DP setting to design a new and more efficient optimizer.
Oblivious Sampling Algorithms for Private Data Analysis
Sep 28, 2020


We study secure and privacy-preserving data analysis based on queries executed on samples from a dataset. Trusted execution environments (TEEs) can be used to protect the content of the data during query computation, while supporting differential-private (DP) queries in TEEs provides record privacy when query output is revealed. Support for sample-based queries is attractive due to \emph{privacy amplification} since not all dataset is used to answer a query but only a small subset. However, extracting data samples with TEEs while proving strong DP guarantees is not trivial as secrecy of sample indices has to be preserved. To this end, we design efficient secure variants of common sampling algorithms. Experimentally we show that accuracy of models trained with shuffling and sampling is the same for differentially private models for MNIST and CIFAR-10, while sampling provides stronger privacy guarantees than shuffling.