 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByzantine-Robust and Differentially Private Federated Optimization under Weaker Assumptions
Mar 24, 2026Federated Learning (FL) enables heterogeneous clients to collaboratively train a shared model without centralizing their raw data, offering an inherent level of privacy. However, gradients and model updates can still leak sensitive information, while malicious servers may mount adversarial attacks such as Byzantine manipulation. These vulnerabilities highlight the need to address differential privacy (DP) and Byzantine robustness within a unified framework. Existing approaches, however, often rely on unrealistic assumptions such as bounded gradients, require auxiliary server-side datasets, or fail to provide convergence guarantees. We address these limitations by proposing Byz-Clip21-SGD2M, a new algorithm that integrates robust aggregation with double momentum and carefully designed clipping. We prove high-probability convergence guarantees under standard $L$-smoothness and $σ$-sub-Gaussian gradient noise assumptions, thereby relaxing conditions that dominate prior work. Our analysis recovers state-of-the-art convergence rates in the absence of adversaries and improves utility guarantees under Byzantine and DP settings. Empirical evaluations on CNN and MLP models trained on MNIST further validate the effectiveness of our approach.
On the Role of Batch Size in Stochastic Conditional Gradient Methods
Mar 22, 2026We study the role of batch size in stochastic conditional gradient methods under a $μ$-Kurdyka-Łojasiewicz ($μ$-KL) condition. Focusing on momentum-based stochastic conditional gradient algorithms (e.g., Scion), we derive a new analysis that explicitly captures the interaction between stepsize, batch size, and stochastic noise. Our study reveals a regime-dependent behavior: increasing the batch size initially improves optimization accuracy but, beyond a critical threshold, the benefits saturate and can eventually degrade performance under a fixed token budget. Notably, the theory predicts the magnitude of the optimal stepsize and aligns well with empirical practices observed in large-scale training. Leveraging these insights, we derive principled guidelines for selecting the batch size and stepsize, and propose an adaptive strategy that increases batch size and sequence length during training while preserving convergence guarantees. Experiments on NanoGPT are consistent with the theoretical predictions and illustrate the emergence of the predicted scaling regimes. Overall, our results provide a theoretical framework for understanding batch size scaling in stochastic conditional gradient methods and offer guidance for designing efficient training schedules in large-scale optimization.
Non-Euclidean Gradient Descent Operates at the Edge of Stability
Mar 05, 2026The Edge of Stability (EoS) is a phenomenon where the sharpness (largest eigenvalue) of the Hessian converges to $2/η$ during training with gradient descent (GD) with a step-size $η$. Despite (apparently) violating classical smoothness assumptions, EoS has been widely observed in deep learning, but its theoretical foundations remain incomplete. We provide an interpretation of EoS through the lens of Directional Smoothness Mishkin et al. [2024]. This interpretation naturally extends to non-Euclidean norms, which we use to define generalized sharpness under an arbitrary norm. Our generalized sharpness measure includes previously studied vanilla GD and preconditioned GD as special cases, as well as methods for which EoS has not been studied, such as $\ell_{\infty}$-descent, Block CD, Spectral GD, and Muon without momentum. Through experiments on neural networks, we show that non-Euclidean GD with our generalized sharpness also exhibits progressive sharpening followed by oscillations around or above the threshold $2/η$. Practically, our framework provides a single, geometry-aware spectral measure that works across optimizers.
Adaptive Methods Are Preferable in High Privacy Settings: An SDE Perspective
Mar 03, 2026Differential Privacy (DP) is becoming central to large-scale training as privacy regulations tighten. We revisit how DP noise interacts with adaptivity in optimization through the lens of stochastic differential equations, providing the first SDE-based analysis of private optimizers. Focusing on DP-SGD and DP-SignSGD under per-example clipping, we show a sharp contrast under fixed hyperparameters: DP-SGD converges at a Privacy-Utility Trade-Off of $\mathcal{O}(1/\varepsilon^2)$ with speed independent of $\varepsilon$, while DP-SignSGD converges at a speed linear in $\varepsilon$ with an $\mathcal{O}(1/\varepsilon)$ trade-off, dominating in high-privacy or large batch noise regimes. By contrast, under optimal learning rates, both methods achieve comparable theoretical asymptotic performance; however, the optimal learning rate of DP-SGD scales linearly with $\varepsilon$, while that of DP-SignSGD is essentially $\varepsilon$-independent. This makes adaptive methods far more practical, as their hyperparameters transfer across privacy levels with little or no re-tuning. Empirical results confirm our theory across training and test metrics, and empirically extend from DP-SignSGD to DP-Adam.
Enhancing Optimizer Stability: Momentum Adaptation of The NGN Step-size
Aug 20, 2025Modern optimization algorithms that incorporate momentum and adaptive step-size offer improved performance in numerous challenging deep learning tasks. However, their effectiveness is often highly sensitive to the choice of hyperparameters, especially the step-size. Tuning these parameters is often difficult, resource-intensive, and time-consuming. Therefore, recent efforts have been directed toward enhancing the stability of optimizers across a wide range of hyperparameter choices [Schaipp et al., 2024]. In this paper, we introduce an algorithm that matches the performance of state-of-the-art optimizers while improving stability to the choice of the step-size hyperparameter through a novel adaptation of the NGN step-size method [Orvieto and Xiao, 2024]. Specifically, we propose a momentum-based version (NGN-M) that attains the standard convergence rate of $\mathcal{O}(1/\sqrt{K})$ under less restrictive assumptions, without the need for interpolation condition or assumptions of bounded stochastic gradients or iterates, in contrast to previous approaches. Additionally, we empirically demonstrate that the combination of the NGN step-size with momentum results in enhanced robustness to the choice of the step-size hyperparameter while delivering performance that is comparable to or surpasses other state-of-the-art optimizers.
Safe-EF: Error Feedback for Nonsmooth Constrained Optimization
May 09, 2025Federated learning faces severe communication bottlenecks due to the high dimensionality of model updates. Communication compression with contractive compressors (e.g., Top-K) is often preferable in practice but can degrade performance without proper handling. Error feedback (EF) mitigates such issues but has been largely restricted for smooth, unconstrained problems, limiting its real-world applicability where non-smooth objectives and safety constraints are critical. We advance our understanding of EF in the canonical non-smooth convex setting by establishing new lower complexity bounds for first-order algorithms with contractive compression. Next, we propose Safe-EF, a novel algorithm that matches our lower bound (up to a constant) while enforcing safety constraints essential for practical applications. Extending our approach to the stochastic setting, we bridge the gap between theory and practical implementation. Extensive experiments in a reinforcement learning setup, simulating distributed humanoid robot training, validate the effectiveness of Safe-EF in ensuring safety and reducing communication complexity.
Unbiased and Sign Compression in Distributed Learning: Comparing Noise Resilience via SDEs
Feb 24, 2025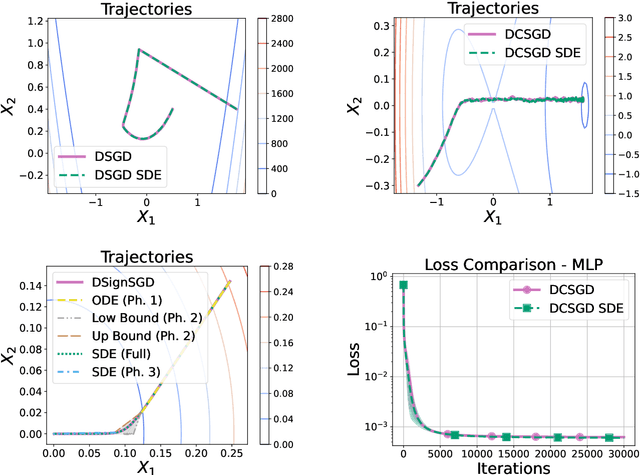
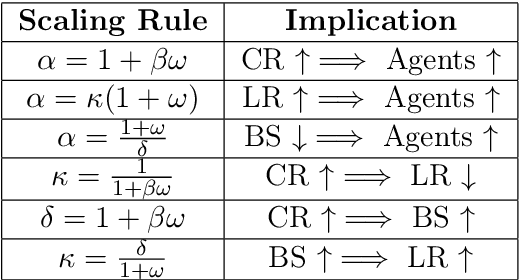
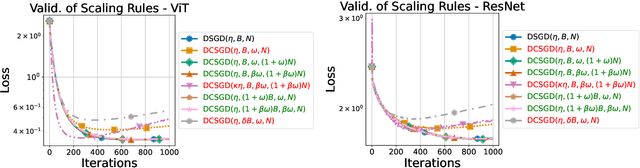
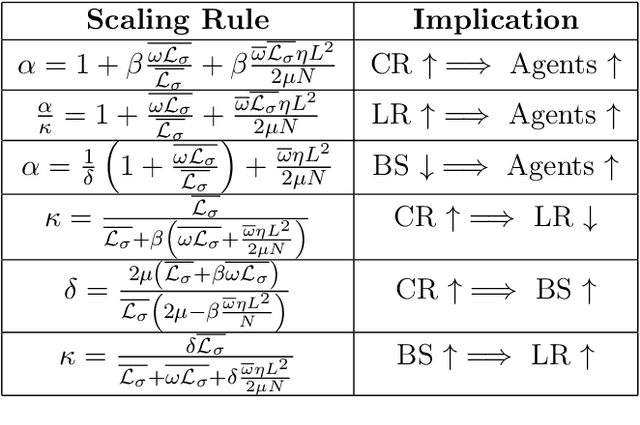
Distributed methods are essential for handling machine learning pipelines comprising large-scale models and datasets. However, their benefits often come at the cost of increased communication overhead between the central server and agents, which can become the main bottleneck, making training costly or even unfeasible in such systems. Compression methods such as quantization and sparsification can alleviate this issue. Still, their robustness to large and heavy-tailed gradient noise, a phenomenon sometimes observed in language modeling, remains poorly understood. This work addresses this gap by analyzing Distributed Compressed SGD (DCSGD) and Distributed SignSGD (DSignSGD) using stochastic differential equations (SDEs). Our results show that DCSGD with unbiased compression is more vulnerable to noise in stochastic gradients, while DSignSGD remains robust, even under large and heavy-tailed noise. Additionally, we propose new scaling rules for hyperparameter tuning to mitigate performance degradation due to compression. These findings are empirically validated across multiple deep learning architectures and datasets, providing practical recommendations for distributed optimization.
Double Momentum and Error Feedback for Clipping with Fast Rates and Differential Privacy
Feb 17, 2025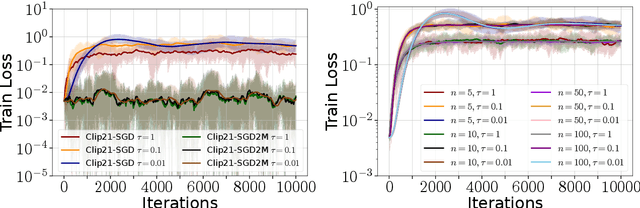
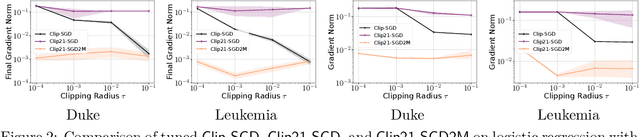


Strong Differential Privacy (DP) and Optimization guarantees are two desirable properties for a method in Federated Learning (FL). However, existing algorithms do not achieve both properties at once: they either have optimal DP guarantees but rely on restrictive assumptions such as bounded gradients/bounded data heterogeneity, or they ensure strong optimization performance but lack DP guarantees. To address this gap in the literature, we propose and analyze a new method called Clip21-SGD2M based on a novel combination of clipping, heavy-ball momentum, and Error Feedback. In particular, for non-convex smooth distributed problems with clients having arbitrarily heterogeneous data, we prove that Clip21-SGD2M has optimal convergence rate and also near optimal (local-)DP neighborhood. Our numerical experiments on non-convex logistic regression and training of neural networks highlight the superiority of Clip21-SGD2M over baselines in terms of the optimization performance for a given DP-budget.
Adaptive Methods through the Lens of SDEs: Theoretical Insights on the Role of Noise
Nov 24, 2024Despite the vast empirical evidence supporting the efficacy of adaptive optimization methods in deep learning, their theoretical understanding is far from complete. This work introduces novel SDEs for commonly used adaptive optimizers: SignSGD, RMSprop(W), and Adam(W). These SDEs offer a quantitatively accurate description of these optimizers and help illuminate an intricate relationship between adaptivity, gradient noise, and curvature. Our novel analysis of SignSGD highlights a noteworthy and precise contrast to SGD in terms of convergence speed, stationary distribution, and robustness to heavy-tail noise. We extend this analysis to AdamW and RMSpropW, for which we observe that the role of noise is much more complex. Crucially, we support our theoretical analysis with experimental evidence by verifying our insights: this includes numerically integrating our SDEs using Euler-Maruyama discretization on various neural network architectures such as MLPs, CNNs, ResNets, and Transformers. Our SDEs accurately track the behavior of the respective optimizers, especially when compared to previous SDEs derived for Adam and RMSprop. We believe our approach can provide valuable insights into best training practices and novel scaling rules.
Loss Landscape Characterization of Neural Networks without Over-Parametrization
Oct 17, 2024
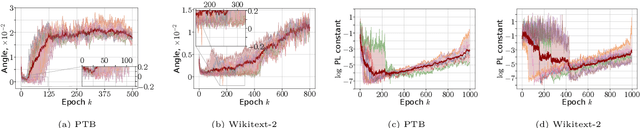

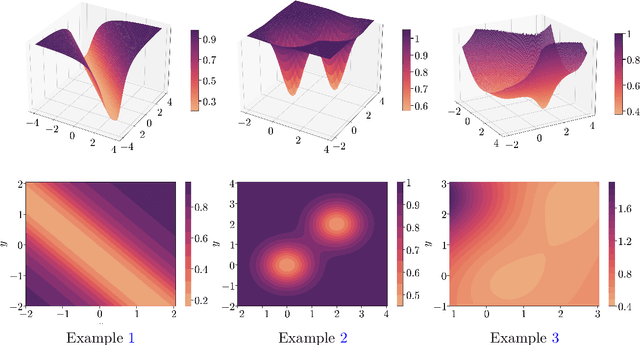
Optimization methods play a crucial role in modern machine learning, powering the remarkable empirical achievements of deep learning models. These successes are even more remarkable given the complex non-convex nature of the loss landscape of these models. Yet, ensuring the convergence of optimization methods requires specific structural conditions on the objective function that are rarely satisfied in practice. One prominent example is the widely recognized Polyak-Lojasiewicz (PL) inequality, which has gained considerable attention in recent years. However, validating such assumptions for deep neural networks entails substantial and often impractical levels of over-parametrization. In order to address this limitation, we propose a novel class of functions that can characterize the loss landscape of modern deep models without requiring extensive over-parametrization and can also include saddle points. Crucially, we prove that gradient-based optimizers possess theoretical guarantees of convergence under this assumption. Finally, we validate the soundness of our new function class through both theoretical analysis and empirical experimentation across a diverse range of deep learning models.