 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Solutions to Non-Convex Functional Constrained Problems with Hidden Convexity
Nov 13, 2025Constrained non-convex optimization is fundamentally challenging, as global solutions are generally intractable and constraint qualifications may not hold. However, in many applications, including safe policy optimization in control and reinforcement learning, such problems possess hidden convexity, meaning they can be reformulated as convex programs via a nonlinear invertible transformation. Typically such transformations are implicit or unknown, making the direct link with the convex program impossible. On the other hand, (sub-)gradients with respect to the original variables are often accessible or can be easily estimated, which motivates algorithms that operate directly in the original (non-convex) problem space using standard (sub-)gradient oracles. In this work, we develop the first algorithms to provably solve such non-convex problems to global minima. First, using a modified inexact proximal point method, we establish global last-iterate convergence guarantees with $\widetilde{\mathcal{O}}(\varepsilon^{-3})$ oracle complexity in non-smooth setting. For smooth problems, we propose a new bundle-level type method based on linearly constrained quadratic subproblems, improving the oracle complexity to $\widetilde{\mathcal{O}}(\varepsilon^{-1})$. Surprisingly, despite non-convexity, our methodology does not require any constraint qualifications, can handle hidden convex equality constraints, and achieves complexities matching those for solving unconstrained hidden convex optimization.
Natural Gradient VI: Guarantees for Non-Conjugate Models
Oct 22, 2025Stochastic Natural Gradient Variational Inference (NGVI) is a widely used method for approximating posterior distribution in probabilistic models. Despite its empirical success and foundational role in variational inference, its theoretical underpinnings remain limited, particularly in the case of non-conjugate likelihoods. While NGVI has been shown to be a special instance of Stochastic Mirror Descent, and recent work has provided convergence guarantees using relative smoothness and strong convexity for conjugate models, these results do not extend to the non-conjugate setting, where the variational loss becomes non-convex and harder to analyze. In this work, we focus on mean-field parameterization and advance the theoretical understanding of NGVI in three key directions. First, we derive sufficient conditions under which the variational loss satisfies relative smoothness with respect to a suitable mirror map. Second, leveraging this structure, we propose a modified NGVI algorithm incorporating non-Euclidean projections and prove its global non-asymptotic convergence to a stationary point. Finally, under additional structural assumptions about the likelihood, we uncover hidden convexity properties of the variational loss and establish fast global convergence of NGVI to a global optimum. These results provide new insights into the geometry and convergence behavior of NGVI in challenging inference settings.
Can SGD Handle Heavy-Tailed Noise?
Aug 06, 2025Stochastic Gradient Descent (SGD) is a cornerstone of large-scale optimization, yet its theoretical behavior under heavy-tailed noise -- common in modern machine learning and reinforcement learning -- remains poorly understood. In this work, we rigorously investigate whether vanilla SGD, devoid of any adaptive modifications, can provably succeed under such adverse stochastic conditions. Assuming only that stochastic gradients have bounded $p$-th moments for some $p \in (1, 2]$, we establish sharp convergence guarantees for (projected) SGD across convex, strongly convex, and non-convex problem classes. In particular, we show that SGD achieves minimax optimal sample complexity under minimal assumptions in the convex and strongly convex regimes: $\mathcal{O}(\varepsilon^{-\frac{p}{p-1}})$ and $\mathcal{O}(\varepsilon^{-\frac{p}{2(p-1)}})$, respectively. For non-convex objectives under H\"older smoothness, we prove convergence to a stationary point with rate $\mathcal{O}(\varepsilon^{-\frac{2p}{p-1}})$, and complement this with a matching lower bound specific to SGD with arbitrary polynomial step-size schedules. Finally, we consider non-convex Mini-batch SGD under standard smoothness and bounded central moment assumptions, and show that it also achieves a comparable $\mathcal{O}(\varepsilon^{-\frac{2p}{p-1}})$ sample complexity with a potential improvement in the smoothness constant. These results challenge the prevailing view that heavy-tailed noise renders SGD ineffective, and establish vanilla SGD as a robust and theoretically principled baseline -- even in regimes where the variance is unbounded.
Safe-EF: Error Feedback for Nonsmooth Constrained Optimization
May 09, 2025Federated learning faces severe communication bottlenecks due to the high dimensionality of model updates. Communication compression with contractive compressors (e.g., Top-K) is often preferable in practice but can degrade performance without proper handling. Error feedback (EF) mitigates such issues but has been largely restricted for smooth, unconstrained problems, limiting its real-world applicability where non-smooth objectives and safety constraints are critical. We advance our understanding of EF in the canonical non-smooth convex setting by establishing new lower complexity bounds for first-order algorithms with contractive compression. Next, we propose Safe-EF, a novel algorithm that matches our lower bound (up to a constant) while enforcing safety constraints essential for practical applications. Extending our approach to the stochastic setting, we bridge the gap between theory and practical implementation. Extensive experiments in a reinforcement learning setup, simulating distributed humanoid robot training, validate the effectiveness of Safe-EF in ensuring safety and reducing communication complexity.
From Gradient Clipping to Normalization for Heavy Tailed SGD
Oct 17, 2024Recent empirical evidence indicates that many machine learning applications involve heavy-tailed gradient noise, which challenges the standard assumptions of bounded variance in stochastic optimization. Gradient clipping has emerged as a popular tool to handle this heavy-tailed noise, as it achieves good performance in this setting both theoretically and practically. However, our current theoretical understanding of non-convex gradient clipping has three main shortcomings. First, the theory hinges on large, increasing clipping thresholds, which are in stark contrast to the small constant clipping thresholds employed in practice. Second, clipping thresholds require knowledge of problem-dependent parameters to guarantee convergence. Lastly, even with this knowledge, current sampling complexity upper bounds for the method are sub-optimal in nearly all parameters. To address these issues, we study convergence of Normalized SGD (NSGD). First, we establish a parameter-free sample complexity for NSGD of $\mathcal{O}\left(\varepsilon^{-\frac{2p}{p-1}}\right)$ to find an $\varepsilon$-stationary point. Furthermore, we prove tightness of this result, by providing a matching algorithm-specific lower bound. In the setting where all problem parameters are known, we show this complexity is improved to $\mathcal{O}\left(\varepsilon^{-\frac{3p-2}{p-1}}\right)$, matching the previously known lower bound for all first-order methods in all problem dependent parameters. Finally, we establish high-probability convergence of NSGD with a mild logarithmic dependence on the failure probability. Our work complements the studies of gradient clipping under heavy tailed noise improving the sample complexities of existing algorithms and offering an alternative mechanism to achieve high probability convergence.
Taming Nonconvex Stochastic Mirror Descent with General Bregman Divergence
Feb 27, 2024
This paper revisits the convergence of Stochastic Mirror Descent (SMD) in the contemporary nonconvex optimization setting. Existing results for batch-free nonconvex SMD restrict the choice of the distance generating function (DGF) to be differentiable with Lipschitz continuous gradients, thereby excluding important setups such as Shannon entropy. In this work, we present a new convergence analysis of nonconvex SMD supporting general DGF, that overcomes the above limitations and relies solely on the standard assumptions. Moreover, our convergence is established with respect to the Bregman Forward-Backward envelope, which is a stronger measure than the commonly used squared norm of gradient mapping. We further extend our results to guarantee high probability convergence under sub-Gaussian noise and global convergence under the generalized Bregman Proximal Polyak-{\L}ojasiewicz condition. Additionally, we illustrate the advantages of our improved SMD theory in various nonconvex machine learning tasks by harnessing nonsmooth DGFs. Notably, in the context of nonconvex differentially private (DP) learning, our theory yields a simple algorithm with a (nearly) dimension-independent utility bound. For the problem of training linear neural networks, we develop provably convergent stochastic algorithms.
Learning Zero-Sum Linear Quadratic Games with Improved Sample Complexity
Sep 08, 2023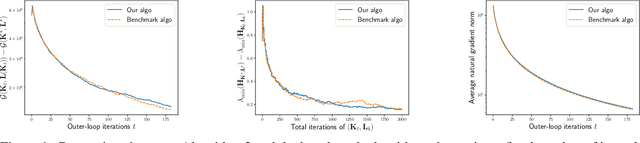
Zero-sum Linear Quadratic (LQ) games are fundamental in optimal control and can be used (i) as a dynamic game formulation for risk-sensitive or robust control, or (ii) as a benchmark setting for multi-agent reinforcement learning with two competing agents in continuous state-control spaces. In contrast to the well-studied single-agent linear quadratic regulator problem, zero-sum LQ games entail solving a challenging nonconvex-nonconcave min-max problem with an objective function that lacks coercivity. Recently, Zhang et al. discovered an implicit regularization property of natural policy gradient methods which is crucial for safety-critical control systems since it preserves the robustness of the controller during learning. Moreover, in the model-free setting where the knowledge of model parameters is not available, Zhang et al. proposed the first polynomial sample complexity algorithm to reach an $\epsilon$-neighborhood of the Nash equilibrium while maintaining the desirable implicit regularization property. In this work, we propose a simpler nested Zeroth-Order (ZO) algorithm improving sample complexity by several orders of magnitude. Our main result guarantees a $\widetilde{\mathcal{O}}(\epsilon^{-3})$ sample complexity under the same assumptions using a single-point ZO estimator. Furthermore, when the estimator is replaced by a two-point estimator, our method enjoys a better $\widetilde{\mathcal{O}}(\epsilon^{-2})$ sample complexity. Our key improvements rely on a more sample-efficient nested algorithm design and finer control of the ZO natural gradient estimation error.
Reinforcement Learning with General Utilities: Simpler Variance Reduction and Large State-Action Space
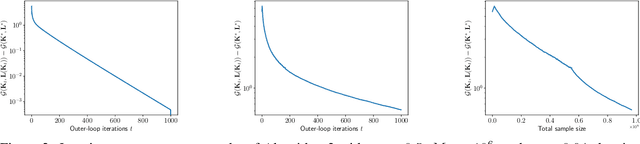
Jun 02, 2023
We consider the reinforcement learning (RL) problem with general utilities which consists in maximizing a function of the state-action occupancy measure. Beyond the standard cumulative reward RL setting, this problem includes as particular cases constrained RL, pure exploration and learning from demonstrations among others. For this problem, we propose a simpler single-loop parameter-free normalized policy gradient algorithm. Implementing a recursive momentum variance reduction mechanism, our algorithm achieves $\tilde{\mathcal{O}}(\epsilon^{-3})$ and $\tilde{\mathcal{O}}(\epsilon^{-2})$ sample complexities for $\epsilon$-first-order stationarity and $\epsilon$-global optimality respectively, under adequate assumptions. We further address the setting of large finite state action spaces via linear function approximation of the occupancy measure and show a $\tilde{\mathcal{O}}(\epsilon^{-4})$ sample complexity for a simple policy gradient method with a linear regression subroutine.
* 48 pages, 2 figures, ICML 2023, this paper was initially submitted in January 26th 2023
Momentum Provably Improves Error Feedback!
May 24, 2023



Due to the high communication overhead when training machine learning models in a distributed environment, modern algorithms invariably rely on lossy communication compression. However, when untreated, the errors caused by compression propagate, and can lead to severely unstable behavior, including exponential divergence. Almost a decade ago, Seide et al [2014] proposed an error feedback (EF) mechanism, which we refer to as EF14, as an immensely effective heuristic for mitigating this issue. However, despite steady algorithmic and theoretical advances in the EF field in the last decade, our understanding is far from complete. In this work we address one of the most pressing issues. In particular, in the canonical nonconvex setting, all known variants of EF rely on very large batch sizes to converge, which can be prohibitive in practice. We propose a surprisingly simple fix which removes this issue both theoretically, and in practice: the application of Polyak's momentum to the latest incarnation of EF due to Richt\'{a}rik et al. [2021] known as EF21. Our algorithm, for which we coin the name EF21-SGDM, improves the communication and sample complexities of previous error feedback algorithms under standard smoothness and bounded variance assumptions, and does not require any further strong assumptions such as bounded gradient dissimilarity. Moreover, we propose a double momentum version of our method that improves the complexities even further. Our proof seems to be novel even when compression is removed from the method, and as such, our proof technique is of independent interest in the study of nonconvex stochastic optimization enriched with Polyak's momentum.
Two Sides of One Coin: the Limits of Untuned SGD and the Power of Adaptive Methods
May 21, 2023


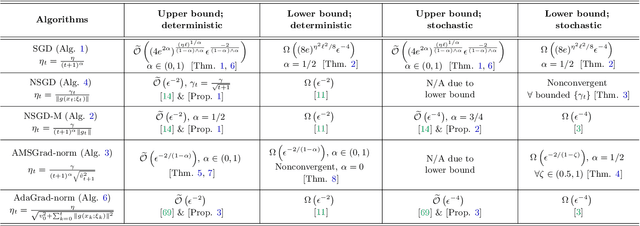
The classical analysis of Stochastic Gradient Descent (SGD) with polynomially decaying stepsize $\eta_t = \eta/\sqrt{t}$ relies on well-tuned $\eta$ depending on problem parameters such as Lipschitz smoothness constant, which is often unknown in practice. In this work, we prove that SGD with arbitrary $\eta > 0$, referred to as untuned SGD, still attains an order-optimal convergence rate $\widetilde{O}(T^{-1/4})$ in terms of gradient norm for minimizing smooth objectives. Unfortunately, it comes at the expense of a catastrophic exponential dependence on the smoothness constant, which we show is unavoidable for this scheme even in the noiseless setting. We then examine three families of adaptive methods $\unicode{x2013}$ Normalized SGD (NSGD), AMSGrad, and AdaGrad $\unicode{x2013}$ unveiling their power in preventing such exponential dependency in the absence of information about the smoothness parameter and boundedness of stochastic gradients. Our results provide theoretical justification for the advantage of adaptive methods over untuned SGD in alleviating the issue with large gradients.