 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Data Mixture for Large Language Models: A Comprehensive Survey and New Perspectives
May 27, 2025Training large language models with data collected from various domains can improve their performance on downstream tasks. However, given a fixed training budget, the sampling proportions of these different domains significantly impact the model's performance. How can we determine the domain weights across different data domains to train the best-performing model within constrained computational resources? In this paper, we provide a comprehensive overview of existing data mixture methods. First, we propose a fine-grained categorization of existing methods, extending beyond the previous offline and online classification. Offline methods are further grouped into heuristic-based, algorithm-based, and function fitting-based methods. For online methods, we categorize them into three groups: online min-max optimization, online mixing law, and other approaches by drawing connections with the optimization frameworks underlying offline methods. Second, we summarize the problem formulations, representative algorithms for each subtype of offline and online methods, and clarify the relationships and distinctions among them. Finally, we discuss the advantages and disadvantages of each method and highlight key challenges in the field of data mixture.
Accelerating Distributed Optimization: A Primal-Dual Perspective on Local Steps
Jul 02, 2024
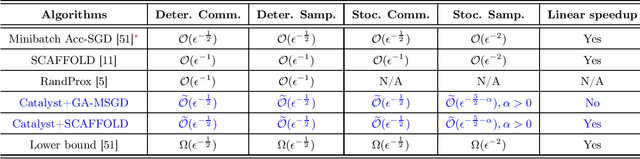
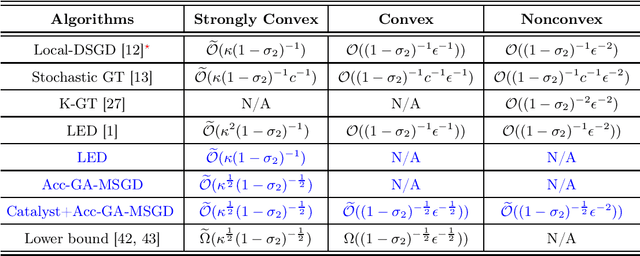
In distributed machine learning, efficient training across multiple agents with different data distributions poses significant challenges. Even with a centralized coordinator, current algorithms that achieve optimal communication complexity typically require either large minibatches or compromise on gradient complexity. In this work, we tackle both centralized and decentralized settings across strongly convex, convex, and nonconvex objectives. We first demonstrate that a basic primal-dual method, (Accelerated) Gradient Ascent Multiple Stochastic Gradient Descent (GA-MSGD), applied to the Lagrangian of distributed optimization inherently incorporates local updates, because the inner loops of running Stochastic Gradient Descent on the primal variable require no inter-agent communication. Notably, for strongly convex objectives, we show (Accelerated) GA-MSGD achieves linear convergence in communication rounds despite the Lagrangian being only linear in the dual variables. This is due to a unique structural property where the dual variable is confined to the span of the coupling matrix, rendering the dual problem strongly concave. When integrated with the Catalyst framework, our approach achieves nearly optimal communication complexity across various settings without the need for minibatches. Moreover, in stochastic decentralized problems, it attains communication complexities comparable to those in deterministic settings, improving over existing algorithms.
Parameter-Agnostic Optimization under Relaxed Smoothness
Nov 06, 2023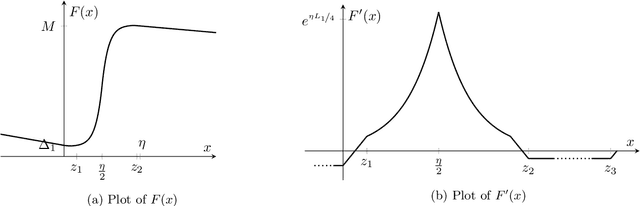
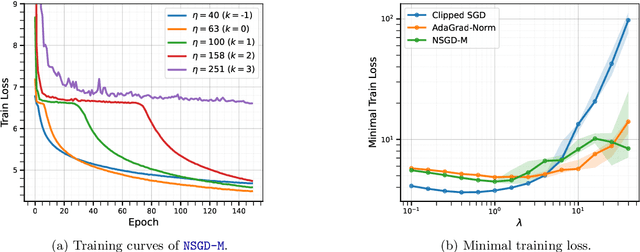
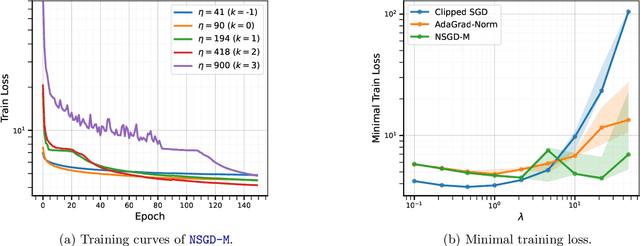
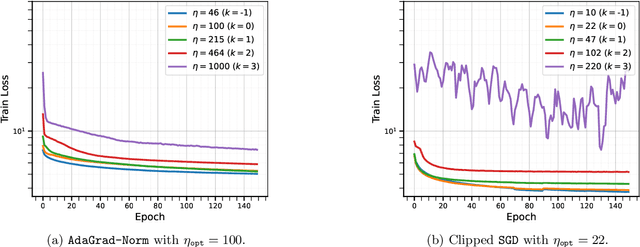
Tuning hyperparameters, such as the stepsize, presents a major challenge of training machine learning models. To address this challenge, numerous adaptive optimization algorithms have been developed that achieve near-optimal complexities, even when stepsizes are independent of problem-specific parameters, provided that the loss function is $L$-smooth. However, as the assumption is relaxed to the more realistic $(L_0, L_1)$-smoothness, all existing convergence results still necessitate tuning of the stepsize. In this study, we demonstrate that Normalized Stochastic Gradient Descent with Momentum (NSGD-M) can achieve a (nearly) rate-optimal complexity without prior knowledge of any problem parameter, though this comes at the cost of introducing an exponential term dependent on $L_1$ in the complexity. We further establish that this exponential term is inevitable to such schemes by introducing a theoretical framework of lower bounds tailored explicitly for parameter-agnostic algorithms. Interestingly, in deterministic settings, the exponential factor can be neutralized by employing Gradient Descent with a Backtracking Line Search. To the best of our knowledge, these findings represent the first parameter-agnostic convergence results under the generalized smoothness condition. Our empirical experiments further confirm our theoretical insights.
Optimal Guarantees for Algorithmic Reproducibility and Gradient Complexity in Convex Optimization
Oct 26, 2023Algorithmic reproducibility measures the deviation in outputs of machine learning algorithms upon minor changes in the training process. Previous work suggests that first-order methods would need to trade-off convergence rate (gradient complexity) for better reproducibility. In this work, we challenge this perception and demonstrate that both optimal reproducibility and near-optimal convergence guarantees can be achieved for smooth convex minimization and smooth convex-concave minimax problems under various error-prone oracle settings. Particularly, given the inexact initialization oracle, our regularization-based algorithms achieve the best of both worlds - optimal reproducibility and near-optimal gradient complexity - for minimization and minimax optimization. With the inexact gradient oracle, the near-optimal guarantees also hold for minimax optimization. Additionally, with the stochastic gradient oracle, we show that stochastic gradient descent ascent is optimal in terms of both reproducibility and gradient complexity. We believe our results contribute to an enhanced understanding of the reproducibility-convergence trade-off in the context of convex optimization.
Two Sides of One Coin: the Limits of Untuned SGD and the Power of Adaptive Methods
May 21, 2023


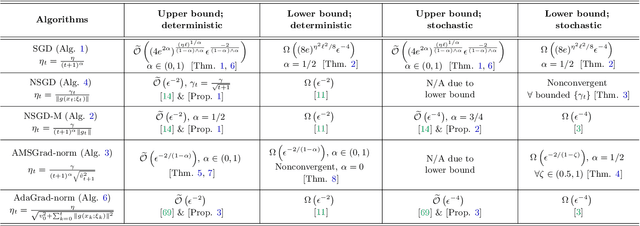
The classical analysis of Stochastic Gradient Descent (SGD) with polynomially decaying stepsize $\eta_t = \eta/\sqrt{t}$ relies on well-tuned $\eta$ depending on problem parameters such as Lipschitz smoothness constant, which is often unknown in practice. In this work, we prove that SGD with arbitrary $\eta > 0$, referred to as untuned SGD, still attains an order-optimal convergence rate $\widetilde{O}(T^{-1/4})$ in terms of gradient norm for minimizing smooth objectives. Unfortunately, it comes at the expense of a catastrophic exponential dependence on the smoothness constant, which we show is unavoidable for this scheme even in the noiseless setting. We then examine three families of adaptive methods $\unicode{x2013}$ Normalized SGD (NSGD), AMSGrad, and AdaGrad $\unicode{x2013}$ unveiling their power in preventing such exponential dependency in the absence of information about the smoothness parameter and boundedness of stochastic gradients. Our results provide theoretical justification for the advantage of adaptive methods over untuned SGD in alleviating the issue with large gradients.
TiAda: A Time-scale Adaptive Algorithm for Nonconvex Minimax Optimization
Oct 31, 2022Adaptive gradient methods have shown their ability to adjust the stepsizes on the fly in a parameter-agnostic manner, and empirically achieve faster convergence for solving minimization problems. When it comes to nonconvex minimax optimization, however, current convergence analyses of gradient descent ascent (GDA) combined with adaptive stepsizes require careful tuning of hyper-parameters and the knowledge of problem-dependent parameters. Such a discrepancy arises from the primal-dual nature of minimax problems and the necessity of delicate time-scale separation between the primal and dual updates in attaining convergence. In this work, we propose a single-loop adaptive GDA algorithm called TiAda for nonconvex minimax optimization that automatically adapts to the time-scale separation. Our algorithm is fully parameter-agnostic and can achieve near-optimal complexities simultaneously in deterministic and stochastic settings of nonconvex-strongly-concave minimax problems. The effectiveness of the proposed method is further justified numerically for a number of machine learning applications.
Nest Your Adaptive Algorithm for Parameter-Agnostic Nonconvex Minimax Optimization
Jun 01, 2022
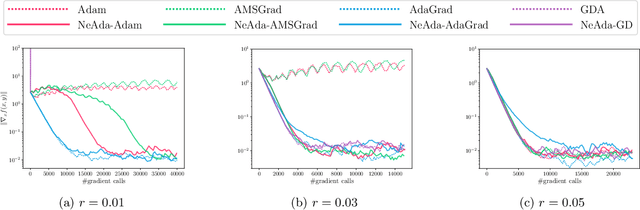
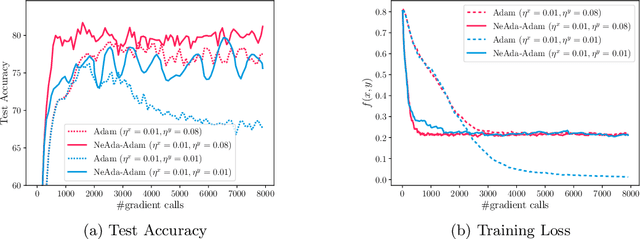
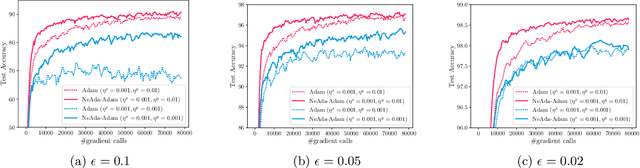
Adaptive algorithms like AdaGrad and AMSGrad are successful in nonconvex optimization owing to their parameter-agnostic ability -- requiring no a priori knowledge about problem-specific parameters nor tuning of learning rates. However, when it comes to nonconvex minimax optimization, direct extensions of such adaptive optimizers without proper time-scale separation may fail to work in practice. We provide such an example proving that the simple combination of Gradient Descent Ascent (GDA) with adaptive stepsizes can diverge if the primal-dual stepsize ratio is not carefully chosen; hence, a fortiori, such adaptive extensions are not parameter-agnostic. To address the issue, we formally introduce a Nested Adaptive framework, NeAda for short, that carries an inner loop for adaptively maximizing the dual variable with controllable stopping criteria and an outer loop for adaptively minimizing the primal variable. Such mechanism can be equipped with off-the-shelf adaptive optimizers and automatically balance the progress in the primal and dual variables. Theoretically, for nonconvex-strongly-concave minimax problems, we show that NeAda can achieve the near-optimal $\tilde{O}(\epsilon^{-2})$ and $\tilde{O}(\epsilon^{-4})$ gradient complexities respectively in the deterministic and stochastic settings, without prior information on the problem's smoothness and strong concavity parameters. To the best of our knowledge, this is the first algorithm that simultaneously achieves near-optimal convergence rates and parameter-agnostic adaptation in the nonconvex minimax setting. Numerically, we further illustrate the robustness of the NeAda family with experiments on simple test functions and a real-world application.
Faster Single-loop Algorithms for Minimax Optimization without Strong Concavity
Dec 10, 2021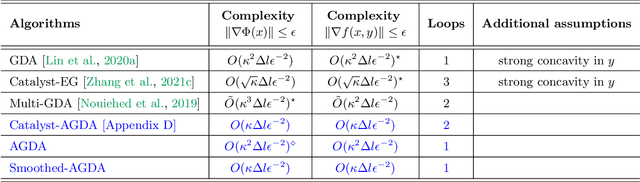
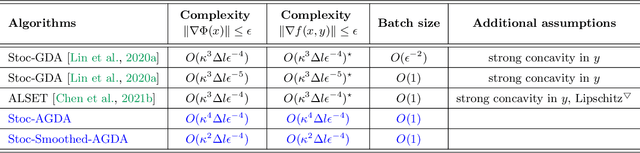

Gradient descent ascent (GDA), the simplest single-loop algorithm for nonconvex minimax optimization, is widely used in practical applications such as generative adversarial networks (GANs) and adversarial training. Albeit its desirable simplicity, recent work shows inferior convergence rates of GDA in theory even assuming strong concavity of the objective on one side. This paper establishes new convergence results for two alternative single-loop algorithms -- alternating GDA and smoothed GDA -- under the mild assumption that the objective satisfies the Polyak-Lojasiewicz (PL) condition about one variable. We prove that, to find an $\epsilon$-stationary point, (i) alternating GDA and its stochastic variant (without mini batch) respectively require $O(\kappa^{2} \epsilon^{-2})$ and $O(\kappa^{4} \epsilon^{-4})$ iterations, while (ii) smoothed GDA and its stochastic variant (without mini batch) respectively require $O(\kappa \epsilon^{-2})$ and $O(\kappa^{2} \epsilon^{-4})$ iterations. The latter greatly improves over the vanilla GDA and gives the hitherto best known complexity results among single-loop algorithms under similar settings. We further showcase the empirical efficiency of these algorithms in training GANs and robust nonlinear regression.
The Complexity of Nonconvex-Strongly-Concave Minimax Optimization
Mar 29, 2021
This paper studies the complexity for finding approximate stationary points of nonconvex-strongly-concave (NC-SC) smooth minimax problems, in both general and averaged smooth finite-sum settings. We establish nontrivial lower complexity bounds of $\Omega(\sqrt{\kappa}\Delta L\epsilon^{-2})$ and $\Omega(n+\sqrt{n\kappa}\Delta L\epsilon^{-2})$ for the two settings, respectively, where $\kappa$ is the condition number, $L$ is the smoothness constant, and $\Delta$ is the initial gap. Our result reveals substantial gaps between these limits and best-known upper bounds in the literature. To close these gaps, we introduce a generic acceleration scheme that deploys existing gradient-based methods to solve a sequence of crafted strongly-convex-strongly-concave subproblems. In the general setting, the complexity of our proposed algorithm nearly matches the lower bound; in particular, it removes an additional poly-logarithmic dependence on accuracy present in previous works. In the averaged smooth finite-sum setting, our proposed algorithm improves over previous algorithms by providing a nearly-tight dependence on the condition number.
Global Convergence and Variance-Reduced Optimization for a Class of Nonconvex-Nonconcave Minimax Problems
Feb 22, 2020

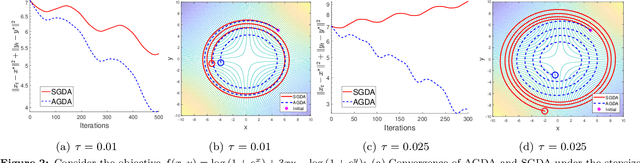

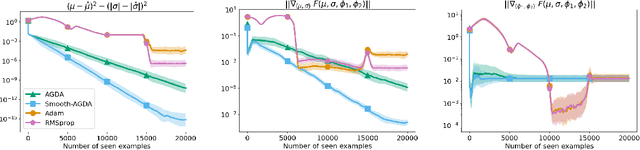
Nonconvex minimax problems appear frequently in emerging machine learning applications, such as generative adversarial networks and adversarial learning. Simple algorithms such as the gradient descent ascent (GDA) are the common practice for solving these nonconvex games and receive lots of empirical success. Yet, it is known that these vanilla GDA algorithms with constant step size can potentially diverge even in the convex setting. In this work, we show that for a subclass of nonconvex-nonconcave objectives satisfying a so-called two-sided Polyak-{\L}ojasiewicz inequality, the alternating gradient descent ascent (AGDA) algorithm converges globally at a linear rate and the stochastic AGDA achieves a sublinear rate. We further develop a variance reduced algorithm that attains a provably faster rate than AGDA when the problem has the finite-sum structure.