 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDADA: Dual Averaging with Distance Adaptation
Jan 17, 2025We present a novel universal gradient method for solving convex optimization problems. Our algorithm -- Dual Averaging with Distance Adaptation (DADA) -- is based on the classical scheme of dual averaging and dynamically adjusts its coefficients based on observed gradients and the distance between iterates and the starting point, eliminating the need for problem-specific parameters. DADA is a universal algorithm that simultaneously works for a broad spectrum of problem classes, provided the local growth of the objective function around its minimizer can be bounded. Particular examples of such problem classes are nonsmooth Lipschitz functions, Lipschitz-smooth functions, H\"older-smooth functions, functions with high-order Lipschitz derivative, quasi-self-concordant functions, and $(L_0,L_1)$-smooth functions. Crucially, DADA is applicable to both unconstrained and constrained problems, even when the domain is unbounded, without requiring prior knowledge of the number of iterations or desired accuracy.
EControl: Fast Distributed Optimization with Compression and Error Control
Nov 06, 2023



Modern distributed training relies heavily on communication compression to reduce the communication overhead. In this work, we study algorithms employing a popular class of contractive compressors in order to reduce communication overhead. However, the naive implementation often leads to unstable convergence or even exponential divergence due to the compression bias. Error Compensation (EC) is an extremely popular mechanism to mitigate the aforementioned issues during the training of models enhanced by contractive compression operators. Compared to the effectiveness of EC in the data homogeneous regime, the understanding of the practicality and theoretical foundations of EC in the data heterogeneous regime is limited. Existing convergence analyses typically rely on strong assumptions such as bounded gradients, bounded data heterogeneity, or large batch accesses, which are often infeasible in modern machine learning applications. We resolve the majority of current issues by proposing EControl, a novel mechanism that can regulate error compensation by controlling the strength of the feedback signal. We prove fast convergence for EControl in standard strongly convex, general convex, and nonconvex settings without any additional assumptions on the problem or data heterogeneity. We conduct extensive numerical evaluations to illustrate the efficacy of our method and support our theoretical findings.
On Avoiding Local Minima Using Gradient Descent With Large Learning Rates
May 30, 2022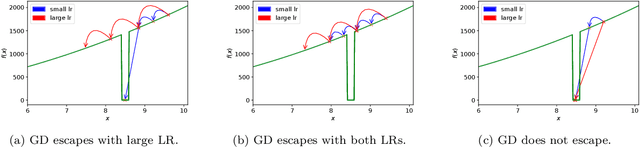
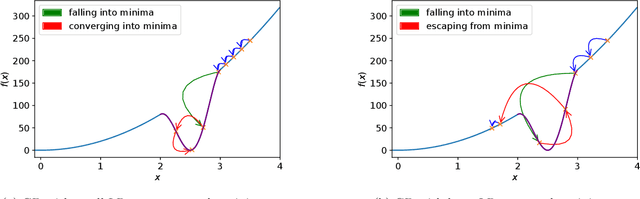
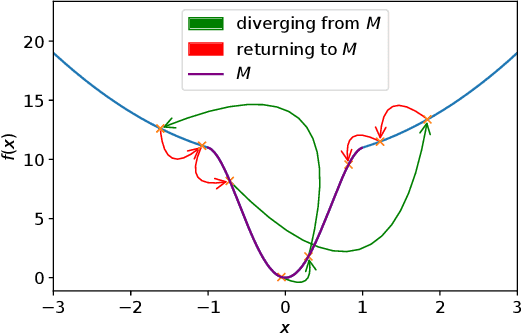
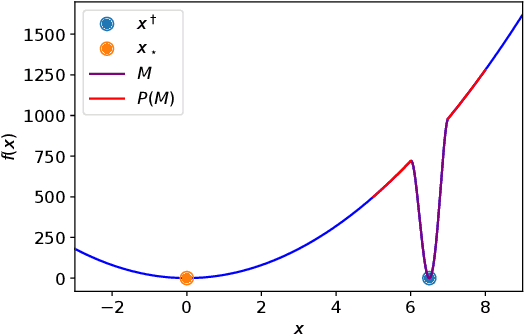
It has been widely observed in training of neural networks that when applying gradient descent (GD), a large step size is essential for obtaining superior models. However, the effect of large step sizes on the success of GD is not well understood theoretically. We argue that a complete understanding of the mechanics leading to GD's success may indeed require considering effects of using a large step size. To support this claim, we prove on a certain class of functions that GD with large step size follows a different trajectory than GD with a small step size, leading to convergence to the global minimum. We also demonstrate the difference in trajectories for small and large learning rates when GD is applied on a neural network, observing effects of an escape from a local minimum with a large step size, which shows this behavior is indeed relevant in practice. Finally, through a novel set of experiments, we show even though stochastic noise is beneficial, it is not enough to explain success of SGD and a large learning rate is essential for obtaining the best performance even in stochastic settings.
ProxSkip: Yes! Local Gradient Steps Provably Lead to Communication Acceleration! Finally!
Feb 18, 2022

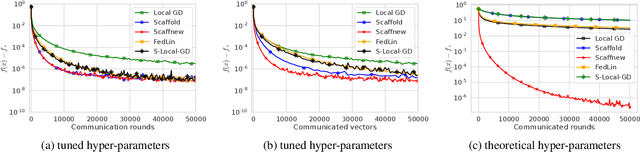

We introduce \algname{ProxSkip} -- a surprisingly simple and provably efficient method for minimizing the sum of a smooth ($f$) and an expensive nonsmooth proximable ($\psi$) function. The canonical approach to solving such problems is via the proximal gradient descent (\algname{ProxGD}) algorithm, which is based on the evaluation of the gradient of $f$ and the prox operator of $\psi$ in each iteration. In this work we are specifically interested in the regime in which the evaluation of prox is costly relative to the evaluation of the gradient, which is the case in many applications. \algname{ProxSkip} allows for the expensive prox operator to be skipped in most iterations: while its iteration complexity is $\cO(\kappa \log \nicefrac{1}{\varepsilon})$, where $\kappa$ is the condition number of $f$, the number of prox evaluations is $\cO(\sqrt{\kappa} \log \nicefrac{1}{\varepsilon})$ only. Our main motivation comes from federated learning, where evaluation of the gradient operator corresponds to taking a local \algname{GD} step independently on all devices, and evaluation of prox corresponds to (expensive) communication in the form of gradient averaging. In this context, \algname{ProxSkip} offers an effective {\em acceleration} of communication complexity. Unlike other local gradient-type methods, such as \algname{FedAvg}, \algname{SCAFFOLD}, \algname{S-Local-GD} and \algname{FedLin}, whose theoretical communication complexity is worse than, or at best matching, that of vanilla \algname{GD} in the heterogeneous data regime, we obtain a provable and large improvement without any heterogeneity-bounding assumptions.
Characterizing & Finding Good Data Orderings for Fast Convergence of Sequential Gradient Methods
Feb 03, 2022
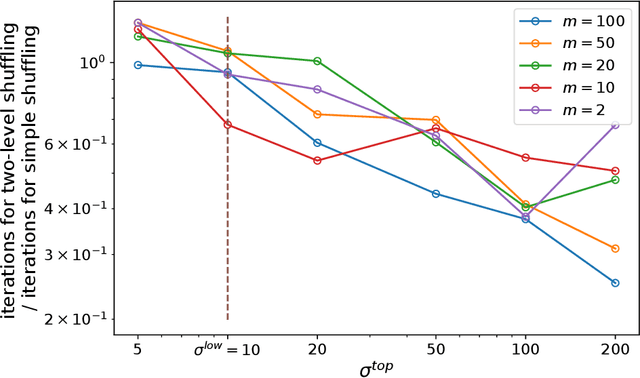
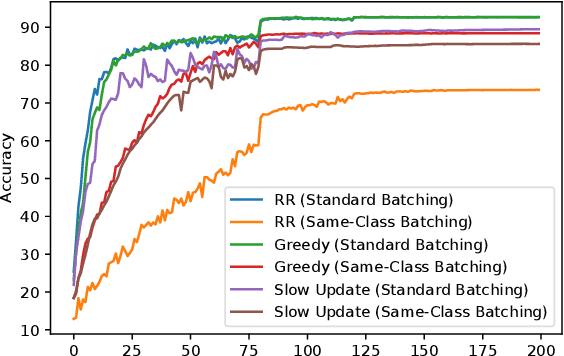
While SGD, which samples from the data with replacement is widely studied in theory, a variant called Random Reshuffling (RR) is more common in practice. RR iterates through random permutations of the dataset and has been shown to converge faster than SGD. When the order is chosen deterministically, a variant called incremental gradient descent (IG), the existing convergence bounds show improvement over SGD but are worse than RR. However, these bounds do not differentiate between a good and a bad ordering and hold for the worst choice of order. Meanwhile, in some cases, choosing the right order when using IG can lead to convergence faster than RR. In this work, we quantify the effect of order on convergence speed, obtaining convergence bounds based on the chosen sequence of permutations while also recovering previous results for RR. In addition, we show benefits of using structured shuffling when various levels of abstractions (e.g. tasks, classes, augmentations, etc.) exists in the dataset in theory and in practice. Finally, relying on our measure, we develop a greedy algorithm for choosing good orders during training, achieving superior performance (by more than 14 percent in accuracy) over RR.
Stochastic continuum armed bandit problem of few linear parameters in high dimensions
May 30, 2017We consider a stochastic continuum armed bandit problem where the arms are indexed by the $\ell_2$ ball $B_{d}(1+\nu)$ of radius $1+\nu$ in $\mathbb{R}^d$. The reward functions $r :B_{d}(1+\nu) \rightarrow \mathbb{R}$ are considered to intrinsically depend on $k \ll d$ unknown linear parameters so that $r(\mathbf{x}) = g(\mathbf{A} \mathbf{x})$ where $\mathbf{A}$ is a full rank $k \times d$ matrix. Assuming the mean reward function to be smooth we make use of results from low-rank matrix recovery literature and derive an efficient randomized algorithm which achieves a regret bound of $O(C(k,d) n^{\frac{1+k}{2+k}} (\log n)^{\frac{1}{2+k}})$ with high probability. Here $C(k,d)$ is at most polynomial in $d$ and $k$ and $n$ is the number of rounds or the sampling budget which is assumed to be known beforehand.