 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing & Finding Good Data Orderings for Fast Convergence of Sequential Gradient Methods
Paper and Code
Feb 03, 2022
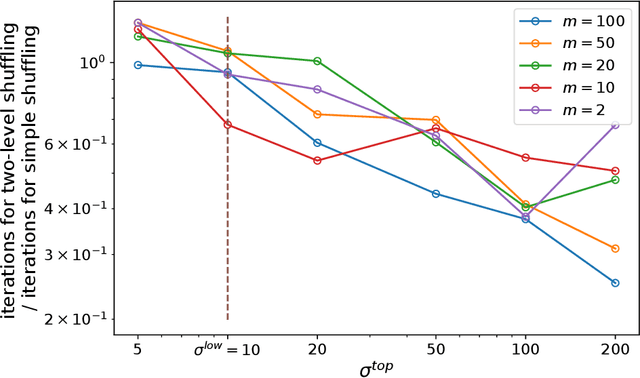
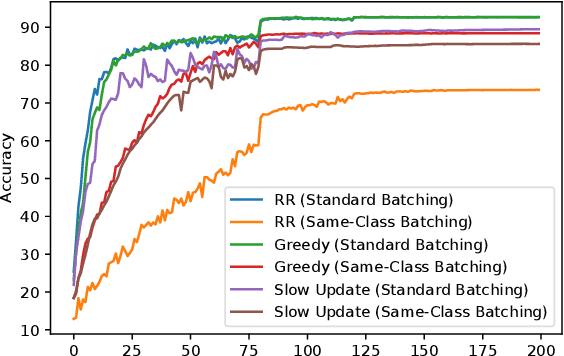
While SGD, which samples from the data with replacement is widely studied in theory, a variant called Random Reshuffling (RR) is more common in practice. RR iterates through random permutations of the dataset and has been shown to converge faster than SGD. When the order is chosen deterministically, a variant called incremental gradient descent (IG), the existing convergence bounds show improvement over SGD but are worse than RR. However, these bounds do not differentiate between a good and a bad ordering and hold for the worst choice of order. Meanwhile, in some cases, choosing the right order when using IG can lead to convergence faster than RR. In this work, we quantify the effect of order on convergence speed, obtaining convergence bounds based on the chosen sequence of permutations while also recovering previous results for RR. In addition, we show benefits of using structured shuffling when various levels of abstractions (e.g. tasks, classes, augmentations, etc.) exists in the dataset in theory and in practice. Finally, relying on our measure, we develop a greedy algorithm for choosing good orders during training, achieving superior performance (by more than 14 percent in accuracy) over RR.