 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Avoiding Local Minima Using Gradient Descent With Large Learning Rates
Paper and Code
May 30, 2022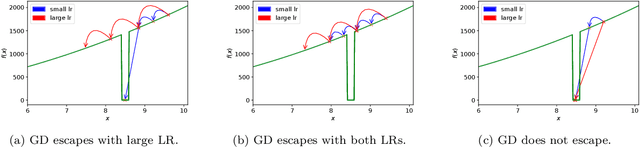
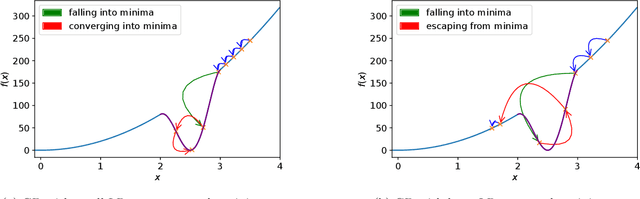
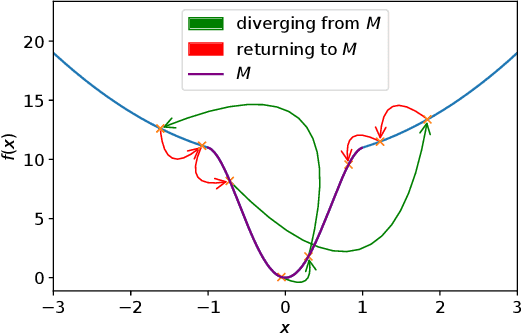
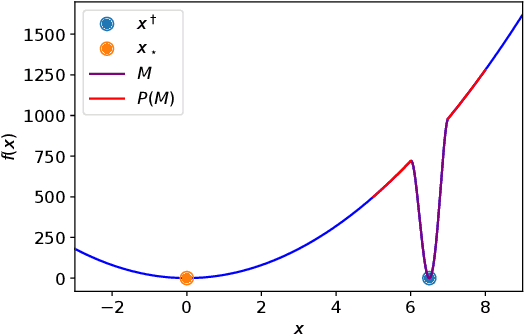
It has been widely observed in training of neural networks that when applying gradient descent (GD), a large step size is essential for obtaining superior models. However, the effect of large step sizes on the success of GD is not well understood theoretically. We argue that a complete understanding of the mechanics leading to GD's success may indeed require considering effects of using a large step size. To support this claim, we prove on a certain class of functions that GD with large step size follows a different trajectory than GD with a small step size, leading to convergence to the global minimum. We also demonstrate the difference in trajectories for small and large learning rates when GD is applied on a neural network, observing effects of an escape from a local minimum with a large step size, which shows this behavior is indeed relevant in practice. Finally, through a novel set of experiments, we show even though stochastic noise is beneficial, it is not enough to explain success of SGD and a large learning rate is essential for obtaining the best performance even in stochastic settings.