 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic continuum armed bandit problem of few linear parameters in high dimensions
May 30, 2017We consider a stochastic continuum armed bandit problem where the arms are indexed by the $\ell_2$ ball $B_{d}(1+\nu)$ of radius $1+\nu$ in $\mathbb{R}^d$. The reward functions $r :B_{d}(1+\nu) \rightarrow \mathbb{R}$ are considered to intrinsically depend on $k \ll d$ unknown linear parameters so that $r(\mathbf{x}) = g(\mathbf{A} \mathbf{x})$ where $\mathbf{A}$ is a full rank $k \times d$ matrix. Assuming the mean reward function to be smooth we make use of results from low-rank matrix recovery literature and derive an efficient randomized algorithm which achieves a regret bound of $O(C(k,d) n^{\frac{1+k}{2+k}} (\log n)^{\frac{1}{2+k}})$ with high probability. Here $C(k,d)$ is at most polynomial in $d$ and $k$ and $n$ is the number of rounds or the sampling budget which is assumed to be known beforehand.
Algorithms for Learning Sparse Additive Models with Interactions in High Dimensions
May 08, 2017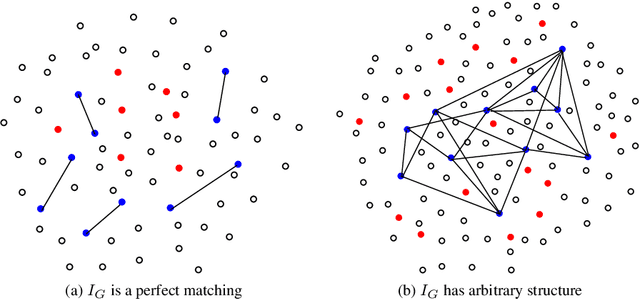
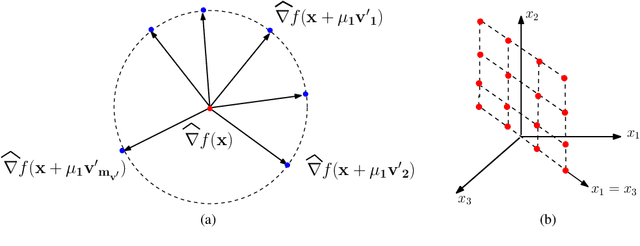
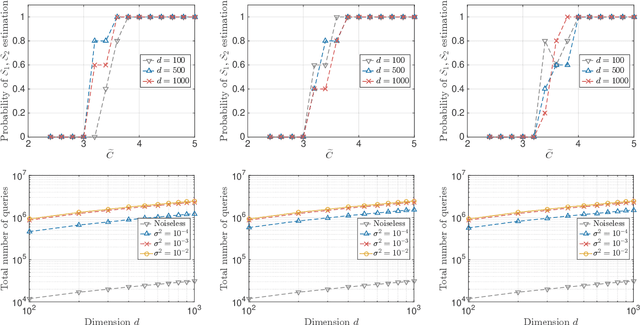
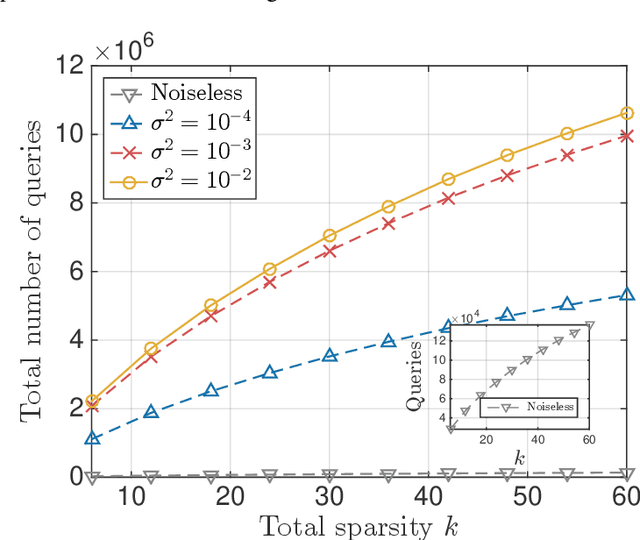
A function $f: \mathbb{R}^d \rightarrow \mathbb{R}$ is a Sparse Additive Model (SPAM), if it is of the form $f(\mathbf{x}) = \sum_{l \in \mathcal{S}}\phi_{l}(x_l)$ where $\mathcal{S} \subset [d]$, $|\mathcal{S}| \ll d$. Assuming $\phi$'s, $\mathcal{S}$ to be unknown, there exists extensive work for estimating $f$ from its samples. In this work, we consider a generalized version of SPAMs, that also allows for the presence of a sparse number of second order interaction terms. For some $\mathcal{S}_1 \subset [d], \mathcal{S}_2 \subset {[d] \choose 2}$, with $|\mathcal{S}_1| \ll d, |\mathcal{S}_2| \ll d^2$, the function $f$ is now assumed to be of the form: $\sum_{p \in \mathcal{S}_1}\phi_{p} (x_p) + \sum_{(l,l^{\prime}) \in \mathcal{S}_2}\phi_{(l,l^{\prime})} (x_l,x_{l^{\prime}})$. Assuming we have the freedom to query $f$ anywhere in its domain, we derive efficient algorithms that provably recover $\mathcal{S}_1,\mathcal{S}_2$ with finite sample bounds. Our analysis covers the noiseless setting where exact samples of $f$ are obtained, and also extends to the noisy setting where the queries are corrupted with noise. For the noisy setting in particular, we consider two noise models namely: i.i.d Gaussian noise and arbitrary but bounded noise. Our main methods for identification of $\mathcal{S}_2$ essentially rely on estimation of sparse Hessian matrices, for which we provide two novel compressed sensing based schemes. Once $\mathcal{S}_1, \mathcal{S}_2$ are known, we show how the individual components $\phi_p$, $\phi_{(l,l^{\prime})}$ can be estimated via additional queries of $f$, with uniform error bounds. Lastly, we provide simulation results on synthetic data that validate our theoretical findings.
Screening Rules for Convex Problems
Sep 23, 2016
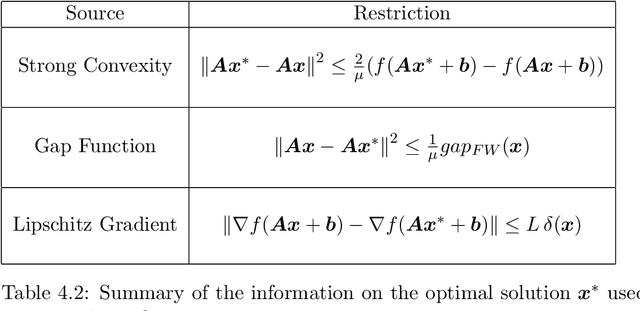


We propose a new framework for deriving screening rules for convex optimization problems. Our approach covers a large class of constrained and penalized optimization formulations, and works in two steps. First, given any approximate point, the structure of the objective function and the duality gap is used to gather information on the optimal solution. In the second step, this information is used to produce screening rules, i.e. safely identifying unimportant weight variables of the optimal solution. Our general framework leads to a large variety of useful existing as well as new screening rules for many applications. For example, we provide new screening rules for general simplex and $L_1$-constrained problems, Elastic Net, squared-loss Support Vector Machines, minimum enclosing ball, as well as structured norm regularized problems, such as group lasso.
Learning Sparse Additive Models with Interactions in High Dimensions
Apr 18, 2016A function $f: \mathbb{R}^d \rightarrow \mathbb{R}$ is referred to as a Sparse Additive Model (SPAM), if it is of the form $f(\mathbf{x}) = \sum_{l \in \mathcal{S}}\phi_{l}(x_l)$, where $\mathcal{S} \subset [d]$, $|\mathcal{S}| \ll d$. Assuming $\phi_l$'s and $\mathcal{S}$ to be unknown, the problem of estimating $f$ from its samples has been studied extensively. In this work, we consider a generalized SPAM, allowing for second order interaction terms. For some $\mathcal{S}_1 \subset [d], \mathcal{S}_2 \subset {[d] \choose 2}$, the function $f$ is assumed to be of the form: $$f(\mathbf{x}) = \sum_{p \in \mathcal{S}_1}\phi_{p} (x_p) + \sum_{(l,l^{\prime}) \in \mathcal{S}_2}\phi_{(l,l^{\prime})} (x_{l},x_{l^{\prime}}).$$ Assuming $\phi_{p},\phi_{(l,l^{\prime})}$, $\mathcal{S}_1$ and, $\mathcal{S}_2$ to be unknown, we provide a randomized algorithm that queries $f$ and exactly recovers $\mathcal{S}_1,\mathcal{S}_2$. Consequently, this also enables us to estimate the underlying $\phi_p, \phi_{(l,l^{\prime})}$. We derive sample complexity bounds for our scheme and also extend our analysis to include the situation where the queries are corrupted with noise -- either stochastic, or arbitrary but bounded. Lastly, we provide simulation results on synthetic data, that validate our theoretical findings.
Continuum armed bandit problem of few variables in high dimensions
Aug 22, 2014We consider the stochastic and adversarial settings of continuum armed bandits where the arms are indexed by [0,1]^d. The reward functions r:[0,1]^d -> R are assumed to intrinsically depend on at most k coordinate variables implying r(x_1,..,x_d) = g(x_{i_1},..,x_{i_k}) for distinct and unknown i_1,..,i_k from {1,..,d} and some locally Holder continuous g:[0,1]^k -> R with exponent 0 < alpha <= 1. Firstly, assuming (i_1,..,i_k) to be fixed across time, we propose a simple modification of the CAB1 algorithm where we construct the discrete set of sampling points to obtain a bound of O(n^((alpha+k)/(2*alpha+k)) (log n)^((alpha)/(2*alpha+k)) C(k,d)) on the regret, with C(k,d) depending at most polynomially in k and sub-logarithmically in d. The construction is based on creating partitions of {1,..,d} into k disjoint subsets and is probabilistic, hence our result holds with high probability. Secondly we extend our results to also handle the more general case where (i_1,...,i_k) can change over time and derive regret bounds for the same.
An Exponential Lower Bound on the Complexity of Regularization Paths
Oct 25, 2012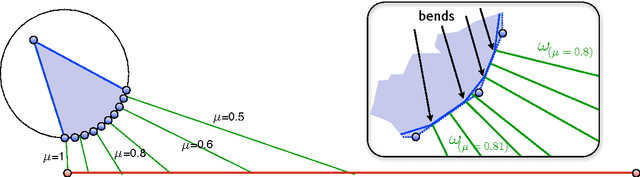


For a variety of regularized optimization problems in machine learning, algorithms computing the entire solution path have been developed recently. Most of these methods are quadratic programs that are parameterized by a single parameter, as for example the Support Vector Machine (SVM). Solution path algorithms do not only compute the solution for one particular value of the regularization parameter but the entire path of solutions, making the selection of an optimal parameter much easier. It has been assumed that these piecewise linear solution paths have only linear complexity, i.e. linearly many bends. We prove that for the support vector machine this complexity can be exponential in the number of training points in the worst case. More strongly, we construct a single instance of n input points in d dimensions for an SVM such that at least \Theta(2^{n/2}) = \Theta(2^d) many distinct subsets of support vectors occur as the regularization parameter changes.
* Journal version, 28 Pages, 5 Figures
A Combinatorial Algorithm to Compute Regularization Paths
Mar 27, 2009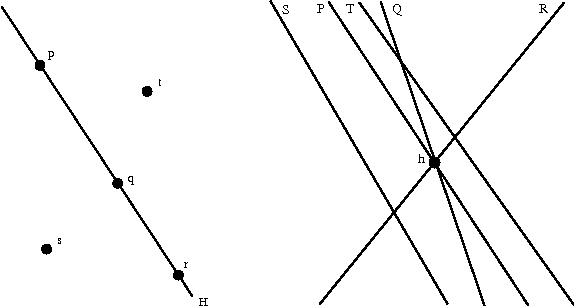
For a wide variety of regularization methods, algorithms computing the entire solution path have been developed recently. Solution path algorithms do not only compute the solution for one particular value of the regularization parameter but the entire path of solutions, making the selection of an optimal parameter much easier. Most of the currently used algorithms are not robust in the sense that they cannot deal with general or degenerate input. Here we present a new robust, generic method for parametric quadratic programming. Our algorithm directly applies to nearly all machine learning applications, where so far every application required its own different algorithm. We illustrate the usefulness of our method by applying it to a very low rank problem which could not be solved by existing path tracking methods, namely to compute part-worth values in choice based conjoint analysis, a popular technique from market research to estimate consumers preferences on a class of parameterized options.