 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Provable Guarantees for Practical Private FL: Beyond Restrictive Assumptions
Dec 25, 2025Federated Learning (FL) enables collaborative training on decentralized data. Differential privacy (DP) is crucial for FL, but current private methods often rely on unrealistic assumptions (e.g., bounded gradients or heterogeneity), hindering practical application. Existing works that relax these assumptions typically neglect practical FL features, including multiple local updates and partial client participation. We introduce Fed-$α$-NormEC, the first differentially private FL framework providing provable convergence and DP guarantees under standard assumptions while fully supporting these practical features. Fed-$α$-NormE integrates local updates (full and incremental gradient steps), separate server and client stepsizes, and, crucially, partial client participation, which is essential for real-world deployment and vital for privacy amplification. Our theoretical guarantees are corroborated by experiments on private deep learning tasks.
Better LMO-based Momentum Methods with Second-Order Information
Dec 15, 2025The use of momentum in stochastic optimization algorithms has shown empirical success across a range of machine learning tasks. Recently, a new class of stochastic momentum algorithms has emerged within the Linear Minimization Oracle (LMO) framework--leading to state-of-the-art methods, such as Muon, Scion, and Gluon, that effectively solve deep neural network training problems. However, traditional stochastic momentum methods offer convergence guarantees no better than the ${O}(1/K^{1/4})$ rate. While several approaches--such as Hessian-Corrected Momentum (HCM)--have aimed to improve this rate, their theoretical results are generally restricted to the Euclidean norm setting. This limitation hinders their applicability in problems, where arbitrary norms are often required. In this paper, we extend the LMO-based framework by integrating HCM, and provide convergence guarantees under relaxed smoothness and arbitrary norm settings. We establish improved convergence rates of ${O}(1/K^{1/3})$ for HCM, which can adapt to the geometry of the problem and achieve a faster rate than traditional momentum. Experimental results on training Multi-Layer Perceptrons (MLPs) and Long Short-Term Memory (LSTM) networks verify our theoretical observations.
Improved Convergence in Parameter-Agnostic Error Feedback through Momentum
Nov 18, 2025Communication compression is essential for scalable distributed training of modern machine learning models, but it often degrades convergence due to the noise it introduces. Error Feedback (EF) mechanisms are widely adopted to mitigate this issue of distributed compression algorithms. Despite their popularity and training efficiency, existing distributed EF algorithms often require prior knowledge of problem parameters (e.g., smoothness constants) to fine-tune stepsizes. This limits their practical applicability especially in large-scale neural network training. In this paper, we study normalized error feedback algorithms that combine EF with normalized updates, various momentum variants, and parameter-agnostic, time-varying stepsizes, thus eliminating the need for problem-dependent tuning. We analyze the convergence of these algorithms for minimizing smooth functions, and establish parameter-agnostic complexity bounds that are close to the best-known bounds with carefully-tuned problem-dependent stepsizes. Specifically, we show that normalized EF21 achieve the convergence rate of near ${O}(1/T^{1/4})$ for Polyak's heavy-ball momentum, ${O}(1/T^{2/7})$ for Iterative Gradient Transport (IGT), and ${O}(1/T^{1/3})$ for STORM and Hessian-corrected momentum. Our results hold with decreasing stepsizes and small mini-batches. Finally, our empirical experiments confirm our theoretical insights.
Smoothed Normalization for Efficient Distributed Private Optimization
Feb 19, 2025Federated learning enables training machine learning models while preserving the privacy of participants. Surprisingly, there is no differentially private distributed method for smooth, non-convex optimization problems. The reason is that standard privacy techniques require bounding the participants' contributions, usually enforced via $\textit{clipping}$ of the updates. Existing literature typically ignores the effect of clipping by assuming the boundedness of gradient norms or analyzes distributed algorithms with clipping but ignores DP constraints. In this work, we study an alternative approach via $\textit{smoothed normalization}$ of the updates motivated by its favorable performance in the single-node setting. By integrating smoothed normalization with an error-feedback mechanism, we design a new distributed algorithm $\alpha$-$\sf NormEC$. We prove that our method achieves a superior convergence rate over prior works. By extending $\alpha$-$\sf NormEC$ to the DP setting, we obtain the first differentially private distributed optimization algorithm with provable convergence guarantees. Finally, our empirical results from neural network training indicate robust convergence of $\alpha$-$\sf NormEC$ across different parameter settings.
Error Feedback under $(L_0,L_1)$-Smoothness: Normalization and Momentum
Oct 22, 2024



We provide the first proof of convergence for normalized error feedback algorithms across a wide range of machine learning problems. Despite their popularity and efficiency in training deep neural networks, traditional analyses of error feedback algorithms rely on the smoothness assumption that does not capture the properties of objective functions in these problems. Rather, these problems have recently been shown to satisfy generalized smoothness assumptions, and the theoretical understanding of error feedback algorithms under these assumptions remains largely unexplored. Moreover, to the best of our knowledge, all existing analyses under generalized smoothness either i) focus on single-node settings or ii) make unrealistically strong assumptions for distributed settings, such as requiring data heterogeneity, and almost surely bounded stochastic gradient noise variance. In this paper, we propose distributed error feedback algorithms that utilize normalization to achieve the $O(1/\sqrt{K})$ convergence rate for nonconvex problems under generalized smoothness. Our analyses apply for distributed settings without data heterogeneity conditions, and enable stepsize tuning that is independent of problem parameters. Additionally, we provide strong convergence guarantees of normalized error feedback algorithms for stochastic settings. Finally, we show that due to their larger allowable stepsizes, our new normalized error feedback algorithms outperform their non-normalized counterparts on various tasks, including the minimization of polynomial functions, logistic regression, and ResNet-20 training.
On the Convergence of Federated Learning Algorithms without Data Similarity
Feb 29, 2024



Data similarity assumptions have traditionally been relied upon to understand the convergence behaviors of federated learning methods. Unfortunately, this approach often demands fine-tuning step sizes based on the level of data similarity. When data similarity is low, these small step sizes result in an unacceptably slow convergence speed for federated methods. In this paper, we present a novel and unified framework for analyzing the convergence of federated learning algorithms without the need for data similarity conditions. Our analysis centers on an inequality that captures the influence of step sizes on algorithmic convergence performance. By applying our theorems to well-known federated algorithms, we derive precise expressions for three widely used step size schedules: fixed, diminishing, and step-decay step sizes, which are independent of data similarity conditions. Finally, we conduct comprehensive evaluations of the performance of these federated learning algorithms, employing the proposed step size strategies to train deep neural network models on benchmark datasets under varying data similarity conditions. Our findings demonstrate significant improvements in convergence speed and overall performance, marking a substantial advancement in federated learning research.
Distributed Momentum Methods Under Biased Gradient Estimations
Feb 29, 2024Distributed stochastic gradient methods are gaining prominence in solving large-scale machine learning problems that involve data distributed across multiple nodes. However, obtaining unbiased stochastic gradients, which have been the focus of most theoretical research, is challenging in many distributed machine learning applications. The gradient estimations easily become biased, for example, when gradients are compressed or clipped, when data is shuffled, and in meta-learning and reinforcement learning. In this work, we establish non-asymptotic convergence bounds on distributed momentum methods under biased gradient estimation on both general non-convex and $\mu$-PL non-convex problems. Our analysis covers general distributed optimization problems, and we work out the implications for special cases where gradient estimates are biased, i.e., in meta-learning and when the gradients are compressed or clipped. Our numerical experiments on training deep neural networks with Top-$K$ sparsification and clipping verify faster convergence performance of momentum methods than traditional biased gradient descent.
Clip21: Error Feedback for Gradient Clipping
May 30, 2023



Motivated by the increasing popularity and importance of large-scale training under differential privacy (DP) constraints, we study distributed gradient methods with gradient clipping, i.e., clipping applied to the gradients computed from local information at the nodes. While gradient clipping is an essential tool for injecting formal DP guarantees into gradient-based methods [1], it also induces bias which causes serious convergence issues specific to the distributed setting. Inspired by recent progress in the error-feedback literature which is focused on taming the bias/error introduced by communication compression operators such as Top-$k$ [2], and mathematical similarities between the clipping operator and contractive compression operators, we design Clip21 -- the first provably effective and practically useful error feedback mechanism for distributed methods with gradient clipping. We prove that our method converges at the same $\mathcal{O}\left(\frac{1}{K}\right)$ rate as distributed gradient descent in the smooth nonconvex regime, which improves the previous best $\mathcal{O}\left(\frac{1}{\sqrt{K}}\right)$ rate which was obtained under significantly stronger assumptions. Our method converges significantly faster in practice than competing methods.
Improving Performance of Private Federated Models in Medical Image Analysis
Apr 11, 2023Federated learning (FL) is a distributed machine learning (ML) approach that allows data to be trained without being centralized. This approach is particularly beneficial for medical applications because it addresses some key challenges associated with medical data, such as privacy, security, and data ownership. On top of that, FL can improve the quality of ML models used in medical applications. Medical data is often diverse and can vary significantly depending on the patient population, making it challenging to develop ML models that are accurate and generalizable. FL allows medical data to be used from multiple sources, which can help to improve the quality and generalizability of ML models. Differential privacy (DP) is a go-to algorithmic tool to make this process secure and private. In this work, we show that the model performance can be further improved by employing local steps, a popular approach to improving the communication efficiency of FL, and tuning the number of communication rounds. Concretely, given the privacy budget, we show an optimal number of local steps and communications rounds. We provide theoretical motivations further corroborated with experimental evaluations on real-world medical imaging tasks.
Communication Efficient Sparsification for Large Scale Machine Learning
Mar 13, 2020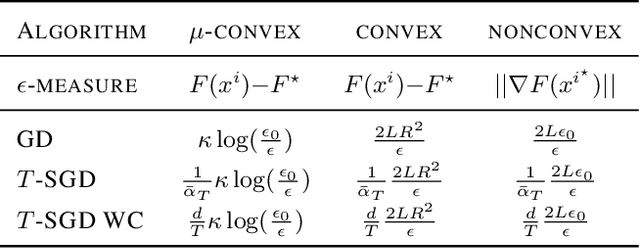
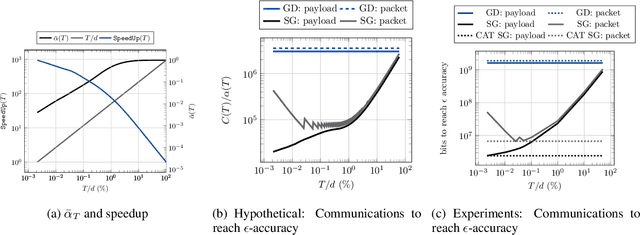
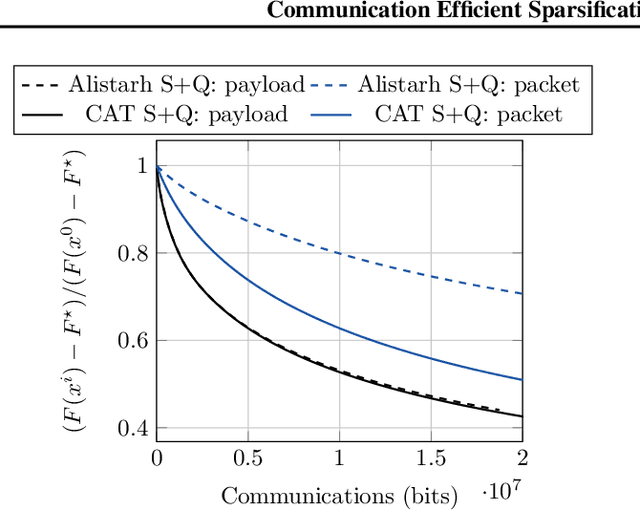
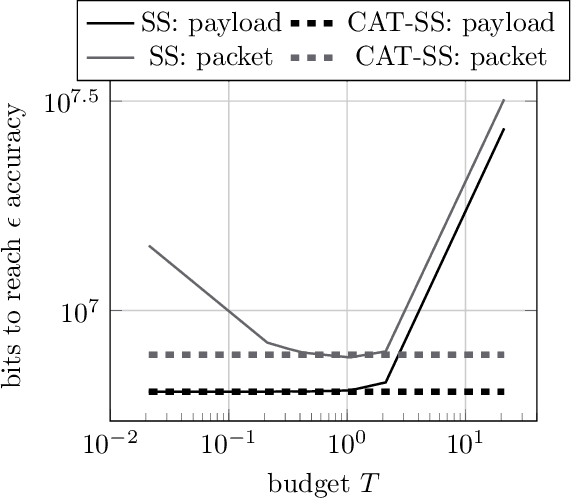
The increasing scale of distributed learning problems necessitates the development of compression techniques for reducing the information exchange between compute nodes. The level of accuracy in existing compression techniques is typically chosen before training, meaning that they are unlikely to adapt well to the problems that they are solving without extensive hyper-parameter tuning. In this paper, we propose dynamic tuning rules that adapt to the communicated gradients at each iteration. In particular, our rules optimize the communication efficiency at each iteration by maximizing the improvement in the objective function that is achieved per communicated bit. Our theoretical results and experiments indicate that the automatic tuning strategies significantly increase communication efficiency on several state-of-the-art compression schemes.