 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Global Token Mixing in Task-Dependent MRI Restoration: Insights from Minimal Gated CNN Baselines
Mar 02, 2026Global token mixing, implemented via self-attention or state-space sequence models, has become a popular model design choice for MRI restoration. However, MRI restoration tasks differ substantially in how their degradations vary over image and k-space domains, and in the degree to which global coupling is already imposed by physics-driven data consistency terms. In this work, we ask the question whether global token mixing is actually beneficial in each individual task across three representative settings: accelerated MRI reconstruction with explicit data consistency, MRI super-resolution with k-space center cropping, and denoising of clinical carotid MRI data with spatially heteroscedastic noise. To reduce confounding factors, we establish a controlled testbed comparing a minimal local gated CNN and its large-field variant, benchmarking them directly against state-of-the-art global models under aligned training and evaluation protocols. For accelerated MRI reconstruction, the minimal unrolled gated-CNN baseline is already highly competitive compared to recent token-mixing approaches in public reconstruction benchmarks, suggesting limited additional benefits when the forward model and data-consistency steps provide strong global constraints. For super-resolution, where low-frequency k-space data are largely preserved by the controlled low-pass degradation, local gated models remain competitive, and a lightweight large-field variant yields only modest improvements. In contrast, for denoising with pronounced spatially heteroscedastic noise, token-mixing models achieve the strongest overall performance, consistent with the need to estimate spatially varying reliability. In conclusion, our results demonstrate that the utility of global token mixing in MRI restoration is task-dependent, and it should be tailored to the underlying imaging physics and degradation structure.
Improving Performance of Private Federated Models in Medical Image Analysis
Apr 11, 2023



Federated learning (FL) is a distributed machine learning (ML) approach that allows data to be trained without being centralized. This approach is particularly beneficial for medical applications because it addresses some key challenges associated with medical data, such as privacy, security, and data ownership. On top of that, FL can improve the quality of ML models used in medical applications. Medical data is often diverse and can vary significantly depending on the patient population, making it challenging to develop ML models that are accurate and generalizable. FL allows medical data to be used from multiple sources, which can help to improve the quality and generalizability of ML models. Differential privacy (DP) is a go-to algorithmic tool to make this process secure and private. In this work, we show that the model performance can be further improved by employing local steps, a popular approach to improving the communication efficiency of FL, and tuning the number of communication rounds. Concretely, given the privacy budget, we show an optimal number of local steps and communications rounds. We provide theoretical motivations further corroborated with experimental evaluations on real-world medical imaging tasks.
Weakly Unsupervised Domain Adaptation for Vestibular Schwannoma Segmentation
Mar 13, 2023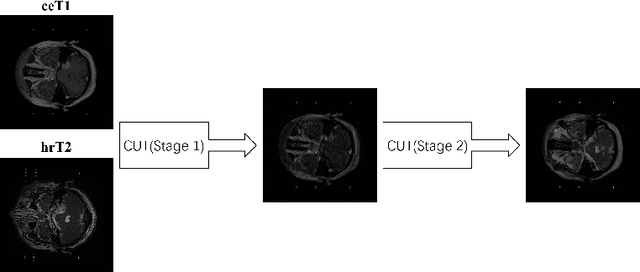



Vestibular schwannoma (VS) is a non-cancerous tumor located next to the ear that can cause hearing loss. Most brain MRI images acquired from patients are contrast-enhanced T1 (ceT1), with a growing interest in high-resolution T2 images (hrT2) to replace ceT1, which involves the use of a contrast agent. As hrT2 images are currently scarce, it is less likely to train robust machine learning models to segment VS or other brain structures. In this work, we propose a weakly supervised machine learning approach that learns from only ceT1 scans and adapts to segment two structures from hrT2 scans: the VS and the cochlea from the crossMoDA dataset. Our model 1) generates fake hrT2 scans from ceT1 images and segmentation masks, 2) is trained using the fake hrT2 scans, 3) predicts the augmented real hrT2 scans, and 4) is retrained again using both the fake and real hrT2. The final result of this model has been computed on an unseen testing dataset provided by the 2022 crossMoDA challenge organizers. The mean dice score and average symmetric surface distance (ASSD) are 0.78 and 0.46, respectively. The predicted segmentation masks achieved a dice score of 0.83 and an ASSD of 0.56 on the VS, and a dice score of 0.74 and an ASSD of 0.35 on the cochleas.