 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in Asynchronous Parallel and Distributed Optimization
Jun 24, 2020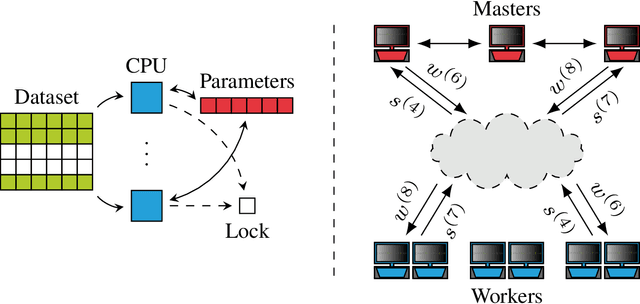
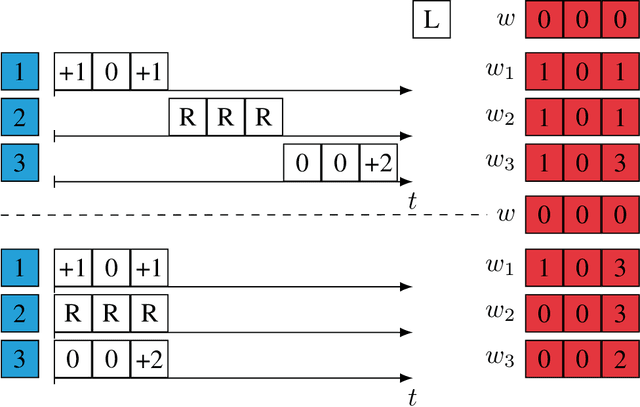
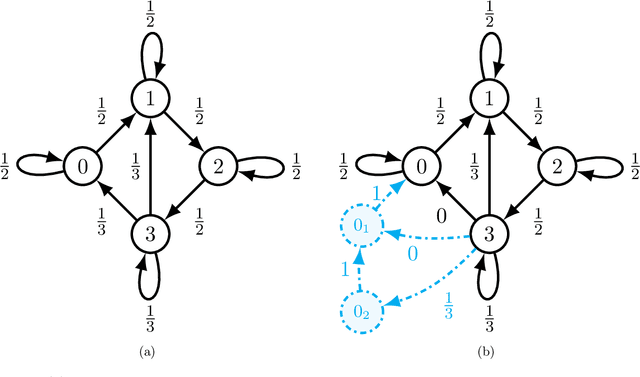
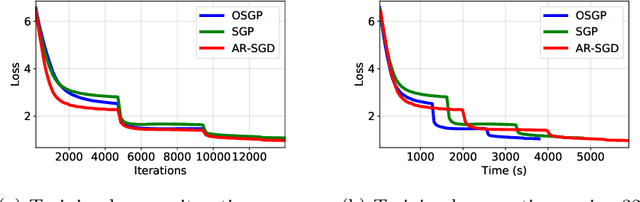
Motivated by large-scale optimization problems arising in the context of machine learning, there have been several advances in the study of asynchronous parallel and distributed optimization methods during the past decade. Asynchronous methods do not require all processors to maintain a consistent view of the optimization variables. Consequently, they generally can make more efficient use of computational resources than synchronous methods, and they are not sensitive to issues like stragglers (i.e., slow nodes) and unreliable communication links. Mathematical modeling of asynchronous methods involves proper accounting of information delays, which makes their analysis challenging. This article reviews recent developments in the design and analysis of asynchronous optimization methods, covering both centralized methods, where all processors update a master copy of the optimization variables, and decentralized methods, where each processor maintains a local copy of the variables. The analysis provides insights as to how the degree of asynchrony impacts convergence rates, especially in stochastic optimization methods.
Communication Efficient Sparsification for Large Scale Machine Learning
Mar 13, 2020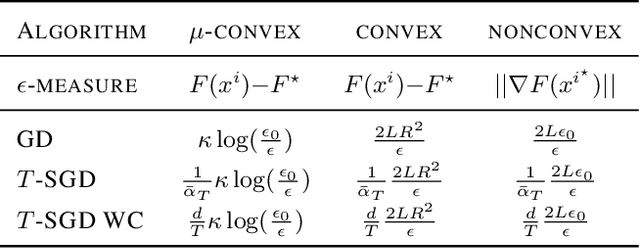
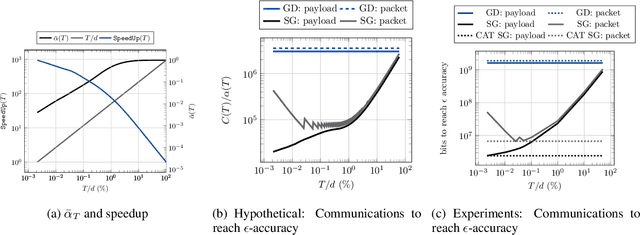
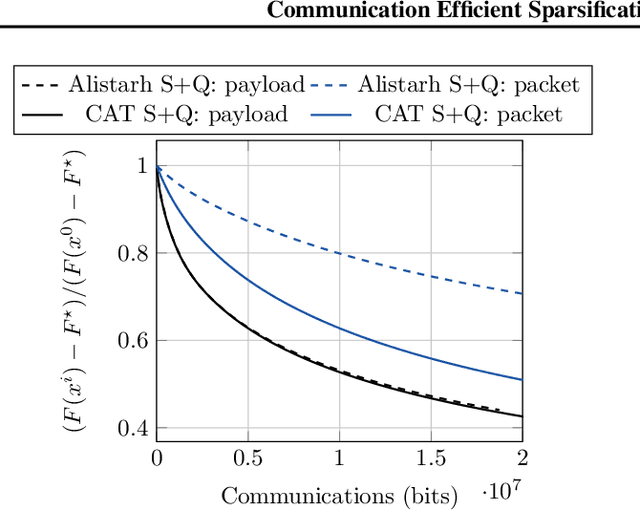
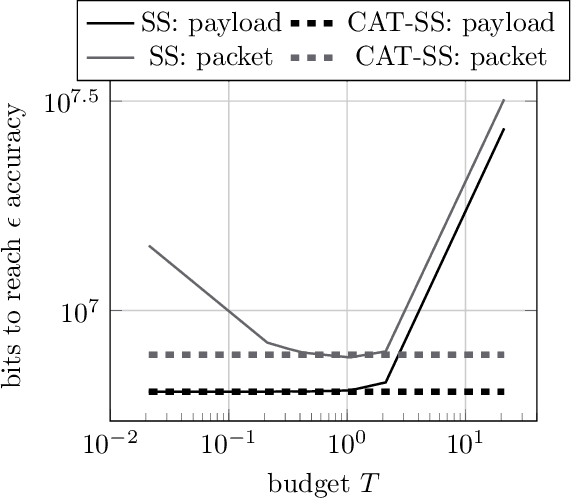
The increasing scale of distributed learning problems necessitates the development of compression techniques for reducing the information exchange between compute nodes. The level of accuracy in existing compression techniques is typically chosen before training, meaning that they are unlikely to adapt well to the problems that they are solving without extensive hyper-parameter tuning. In this paper, we propose dynamic tuning rules that adapt to the communicated gradients at each iteration. In particular, our rules optimize the communication efficiency at each iteration by maximizing the improvement in the objective function that is achieved per communicated bit. Our theoretical results and experiments indicate that the automatic tuning strategies significantly increase communication efficiency on several state-of-the-art compression schemes.
Harnessing the Power of Serverless Runtimes for Large-Scale Optimization
Jan 10, 2019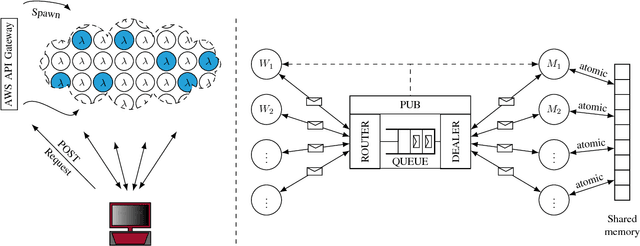
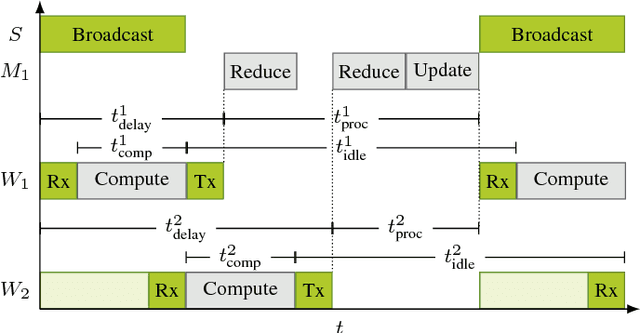
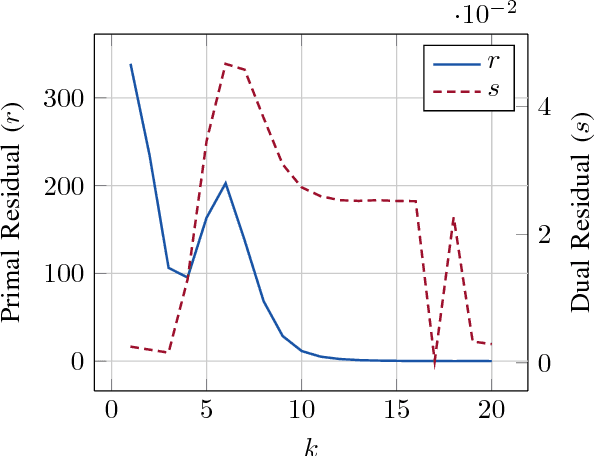
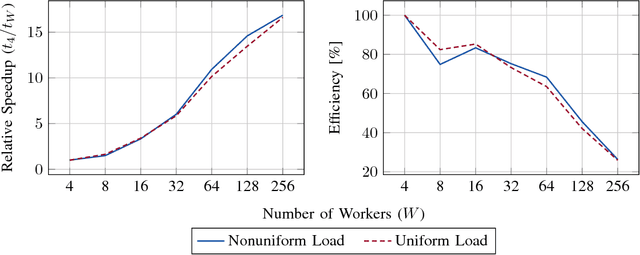
The event-driven and elastic nature of serverless runtimes makes them a very efficient and cost-effective alternative for scaling up computations. So far, they have mostly been used for stateless, data parallel and ephemeral computations. In this work, we propose using serverless runtimes to solve generic, large-scale optimization problems. Specifically, we build a master-worker setup using AWS Lambda as the source of our workers, implement a parallel optimization algorithm to solve a regularized logistic regression problem, and show that relative speedups up to 256 workers and efficiencies above 70% up to 64 workers can be expected. We also identify possible algorithmic and system-level bottlenecks, propose improvements, and discuss the limitations and challenges in realizing these improvements.
POLO: a POLicy-based Optimization library
Oct 08, 2018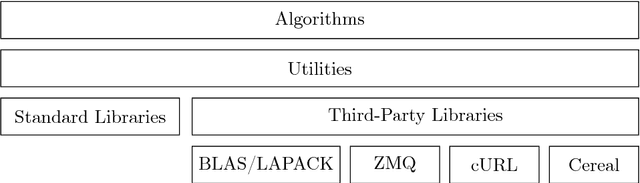
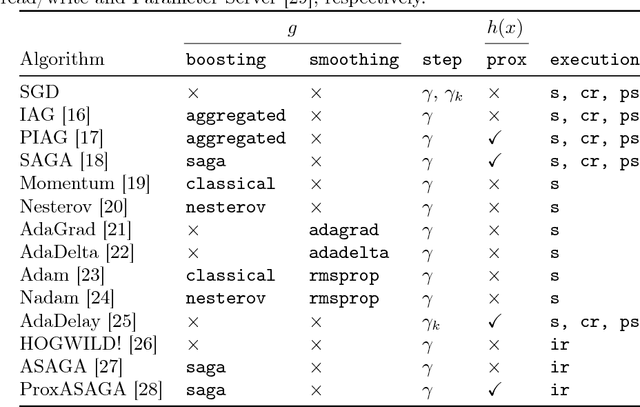
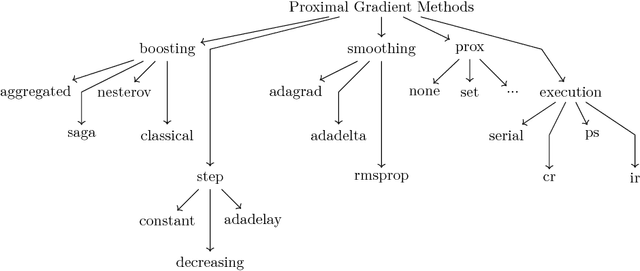
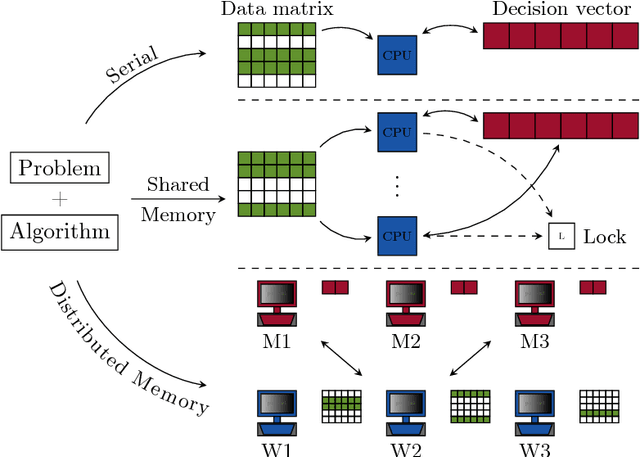
We present POLO --- a C++ library for large-scale parallel optimization research that emphasizes ease-of-use, flexibility and efficiency in algorithm design. It uses multiple inheritance and template programming to decompose algorithms into essential policies and facilitate code reuse. With its clear separation between algorithm and execution policies, it provides researchers with a simple and powerful platform for prototyping ideas, evaluating them on different parallel computing architectures and hardware platforms, and generating compact and efficient production code. A C-API is included for customization and data loading in high-level languages. POLO enables users to move seamlessly from serial to multi-threaded shared-memory and multi-node distributed-memory executors. We demonstrate how POLO allows users to implement state-of-the-art asynchronous parallel optimization algorithms in just a few lines of code and report experiment results from shared and distributed-memory computing architectures. We provide both POLO and POLO.jl, a wrapper around POLO written in the Julia language, at https://github.com/pologrp under the permissive MIT license.
Analysis and Implementation of an Asynchronous Optimization Algorithm for the Parameter Server
Oct 18, 2016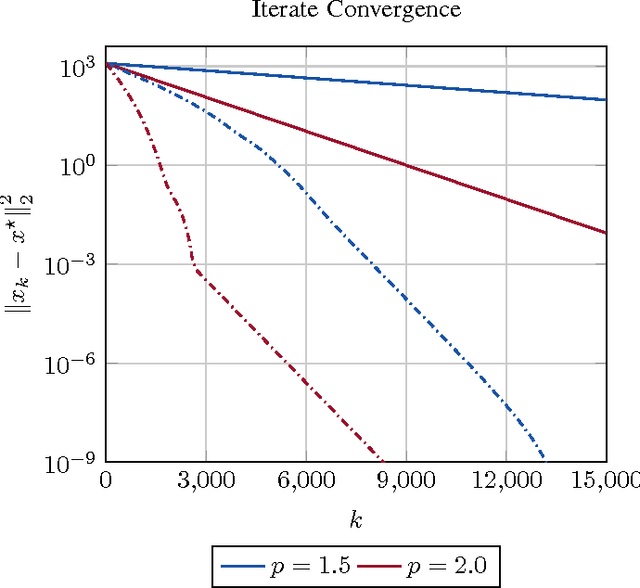

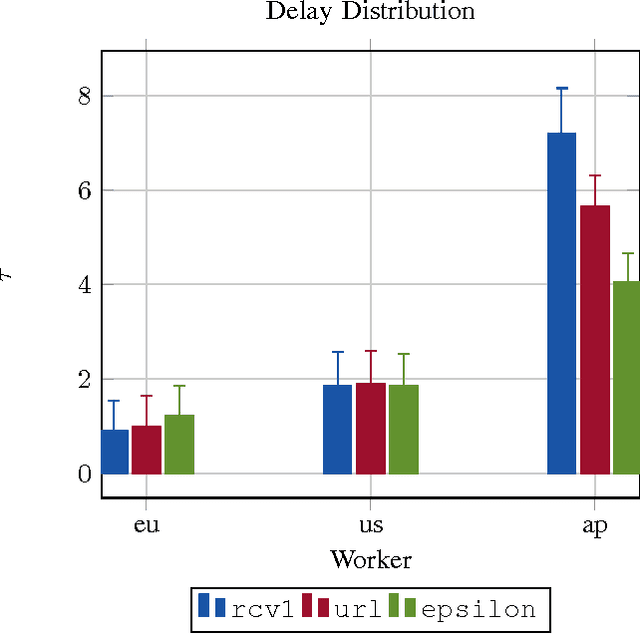
This paper presents an asynchronous incremental aggregated gradient algorithm and its implementation in a parameter server framework for solving regularized optimization problems. The algorithm can handle both general convex (possibly non-smooth) regularizers and general convex constraints. When the empirical data loss is strongly convex, we establish linear convergence rate, give explicit expressions for step-size choices that guarantee convergence to the optimum, and bound the associated convergence factors. The expressions have an explicit dependence on the degree of asynchrony and recover classical results under synchronous operation. Simulations and implementations on commercial compute clouds validate our findings.
An Asynchronous Mini-Batch Algorithm for Regularized Stochastic Optimization
May 18, 2015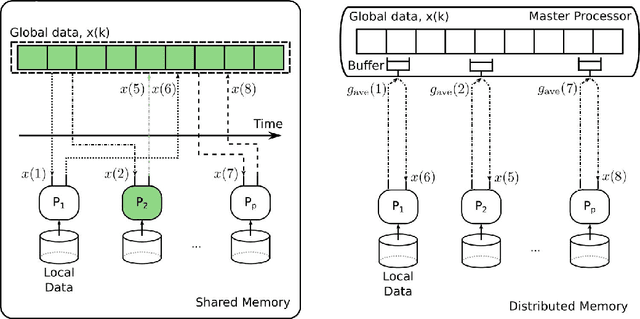
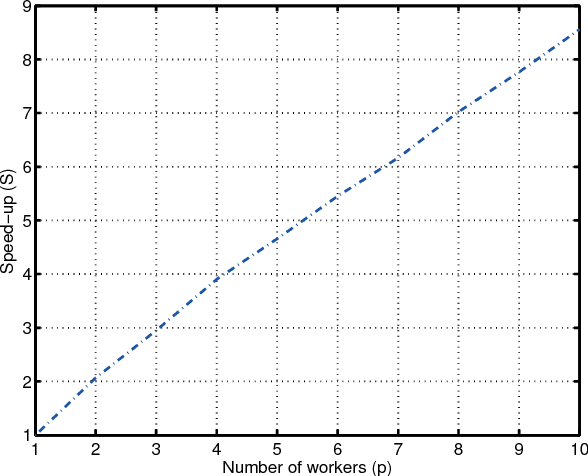
Mini-batch optimization has proven to be a powerful paradigm for large-scale learning. However, the state of the art parallel mini-batch algorithms assume synchronous operation or cyclic update orders. When worker nodes are heterogeneous (due to different computational capabilities or different communication delays), synchronous and cyclic operations are inefficient since they will leave workers idle waiting for the slower nodes to complete their computations. In this paper, we propose an asynchronous mini-batch algorithm for regularized stochastic optimization problems with smooth loss functions that eliminates idle waiting and allows workers to run at their maximal update rates. We show that by suitably choosing the step-size values, the algorithm achieves a rate of the order $O(1/\sqrt{T})$ for general convex regularization functions, and the rate $O(1/T)$ for strongly convex regularization functions, where $T$ is the number of iterations. In both cases, the impact of asynchrony on the convergence rate of our algorithm is asymptotically negligible, and a near-linear speedup in the number of workers can be expected. Theoretical results are confirmed in real implementations on a distributed computing infrastructure.