 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Asynchronous Mini-Batch Algorithm for Regularized Stochastic Optimization
Paper and Code
May 18, 2015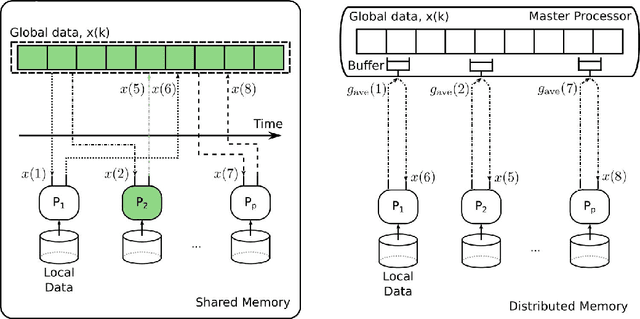
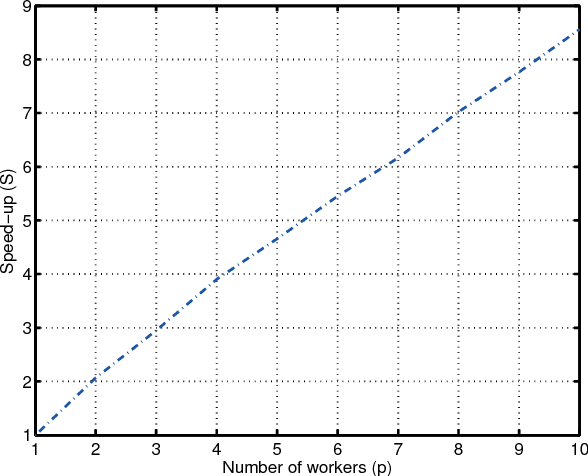
Mini-batch optimization has proven to be a powerful paradigm for large-scale learning. However, the state of the art parallel mini-batch algorithms assume synchronous operation or cyclic update orders. When worker nodes are heterogeneous (due to different computational capabilities or different communication delays), synchronous and cyclic operations are inefficient since they will leave workers idle waiting for the slower nodes to complete their computations. In this paper, we propose an asynchronous mini-batch algorithm for regularized stochastic optimization problems with smooth loss functions that eliminates idle waiting and allows workers to run at their maximal update rates. We show that by suitably choosing the step-size values, the algorithm achieves a rate of the order $O(1/\sqrt{T})$ for general convex regularization functions, and the rate $O(1/T)$ for strongly convex regularization functions, where $T$ is the number of iterations. In both cases, the impact of asynchrony on the convergence rate of our algorithm is asymptotically negligible, and a near-linear speedup in the number of workers can be expected. Theoretical results are confirmed in real implementations on a distributed computing infrastructure.