 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Efficient Sparsification for Large Scale Machine Learning
Paper and Code
Mar 13, 2020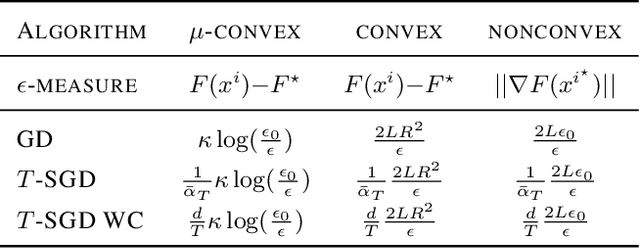
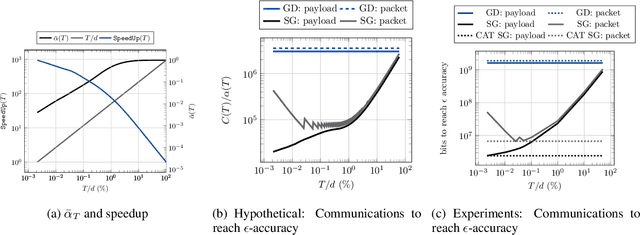
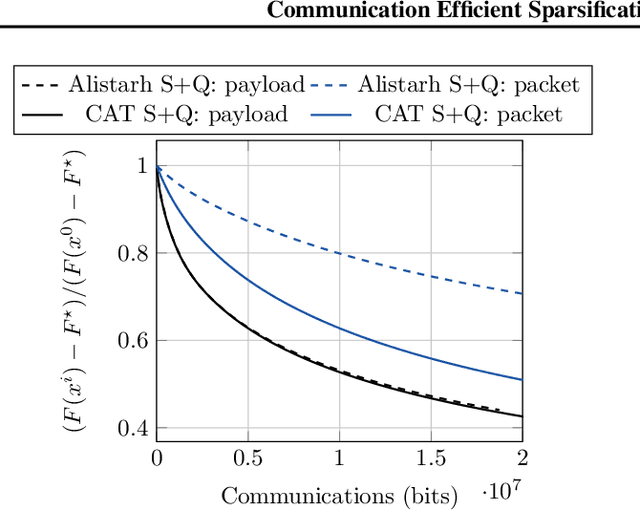
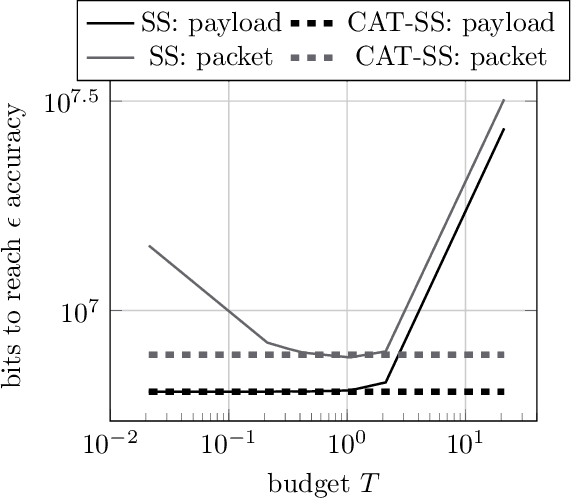
The increasing scale of distributed learning problems necessitates the development of compression techniques for reducing the information exchange between compute nodes. The level of accuracy in existing compression techniques is typically chosen before training, meaning that they are unlikely to adapt well to the problems that they are solving without extensive hyper-parameter tuning. In this paper, we propose dynamic tuning rules that adapt to the communicated gradients at each iteration. In particular, our rules optimize the communication efficiency at each iteration by maximizing the improvement in the objective function that is achieved per communicated bit. Our theoretical results and experiments indicate that the automatic tuning strategies significantly increase communication efficiency on several state-of-the-art compression schemes.