 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Fused Multimodal Deep Learning for Plant Identification
Jun 03, 2024Plant classification is vital for ecological conservation and agricultural productivity, enhancing our understanding of plant growth dynamics and aiding species preservation. The advent of deep learning (DL) techniques has revolutionized this field by enabling autonomous feature extraction, significantly reducing the dependence on manual expertise. However, conventional DL models often rely solely on single data sources, failing to capture the full biological diversity of plant species comprehensively. Recent research has turned to multimodal learning to overcome this limitation by integrating multiple data types, which enriches the representation of plant characteristics. This shift introduces the challenge of determining the optimal point for modality fusion. In this paper, we introduce a pioneering multimodal DL-based approach for plant classification with automatic modality fusion. Utilizing the multimodal fusion architecture search, our method integrates images from multiple plant organs-flowers, leaves, fruits, and stems-into a cohesive model. Our method achieves 83.48% accuracy on 956 classes of the PlantCLEF2015 dataset, surpassing state-of-the-art methods. It outperforms late fusion by 11.07% and is more robust to missing modalities. We validate our model against established benchmarks using standard performance metrics and McNemar's test, further underscoring its superiority.
Distributed Momentum Methods Under Biased Gradient Estimations
Feb 29, 2024

Distributed stochastic gradient methods are gaining prominence in solving large-scale machine learning problems that involve data distributed across multiple nodes. However, obtaining unbiased stochastic gradients, which have been the focus of most theoretical research, is challenging in many distributed machine learning applications. The gradient estimations easily become biased, for example, when gradients are compressed or clipped, when data is shuffled, and in meta-learning and reinforcement learning. In this work, we establish non-asymptotic convergence bounds on distributed momentum methods under biased gradient estimation on both general non-convex and $\mu$-PL non-convex problems. Our analysis covers general distributed optimization problems, and we work out the implications for special cases where gradient estimates are biased, i.e., in meta-learning and when the gradients are compressed or clipped. Our numerical experiments on training deep neural networks with Top-$K$ sparsification and clipping verify faster convergence performance of momentum methods than traditional biased gradient descent.
On the Convergence of Federated Learning Algorithms without Data Similarity
Feb 29, 2024



Data similarity assumptions have traditionally been relied upon to understand the convergence behaviors of federated learning methods. Unfortunately, this approach often demands fine-tuning step sizes based on the level of data similarity. When data similarity is low, these small step sizes result in an unacceptably slow convergence speed for federated methods. In this paper, we present a novel and unified framework for analyzing the convergence of federated learning algorithms without the need for data similarity conditions. Our analysis centers on an inequality that captures the influence of step sizes on algorithmic convergence performance. By applying our theorems to well-known federated algorithms, we derive precise expressions for three widely used step size schedules: fixed, diminishing, and step-decay step sizes, which are independent of data similarity conditions. Finally, we conduct comprehensive evaluations of the performance of these federated learning algorithms, employing the proposed step size strategies to train deep neural network models on benchmark datasets under varying data similarity conditions. Our findings demonstrate significant improvements in convergence speed and overall performance, marking a substantial advancement in federated learning research.
Human-Inspired Framework to Accelerate Reinforcement Learning
Feb 28, 2023While deep reinforcement learning (RL) is becoming an integral part of good decision-making in data science, it is still plagued with sample inefficiency. This can be challenging when applying deep-RL in real-world environments where physical interactions are expensive and can risk system safety. To improve the sample efficiency of RL algorithms, this paper proposes a novel human-inspired framework that facilitates fast exploration and learning for difficult RL tasks. The main idea is to first provide the learning agent with simpler but similar tasks that gradually grow in difficulty and progress toward the main task. The proposed method requires no pre-training phase. Specifically, the learning of simpler tasks is only done for one iteration. The generated knowledge could be used by any transfer learning, including value transfer and policy transfer, to reduce the sample complexity while not adding to the computational complexity. So, it can be applied to any goal, environment, and reinforcement learning algorithm - both value-based methods and policy-based methods and both tabular methods and deep-RL methods. We have evaluated our proposed framework on both a simple Random Walk for illustration purposes and on more challenging optimal control problems with constraint. The experiments show the good performance of our proposed framework in improving the sample efficiency of RL-learning algorithms, especially when the main task is difficult.
Using MM principles to deal with incomplete data in K-means clustering
Dec 23, 2022Among many clustering algorithms, the K-means clustering algorithm is widely used because of its simple algorithm and fast convergence. However, this algorithm suffers from incomplete data, where some samples have missed some of their attributes. To solve this problem, we mainly apply MM principles to restore the symmetry of the data, so that K-means could work well. We give the pseudo-code of the algorithm and use the standard datasets for experimental verification. The source code for the experiments is publicly available in the following link: \url{https://github.com/AliBeikmohammadi/MM-Optimization/blob/main/mini-project/MM%20K-means.ipynb}.
NARS vs. Reinforcement learning: ONA vs. Q-Learning
Dec 23, 2022One of the realistic scenarios is taking a sequence of optimal actions to do a task. Reinforcement learning is the most well-known approach to deal with this kind of task in the machine learning community. Finding a suitable alternative could always be an interesting and out-of-the-box matter. Therefore, in this project, we are looking to investigate the capability of NARS and answer the question of whether NARS has the potential to be a substitute for RL or not. Particularly, we are making a comparison between $Q$-Learning and ONA on some environments developed by an Open AI gym. The source code for the experiments is publicly available in the following link: \url{https://github.com/AliBeikmohammadi/OpenNARS-for-Applications/tree/master/misc/Python}.
SWP-Leaf NET: a novel multistage approach for plant leaf identification based on deep learning
Sep 10, 2020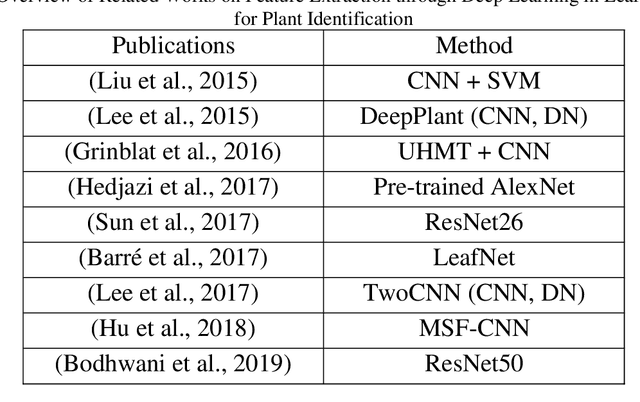
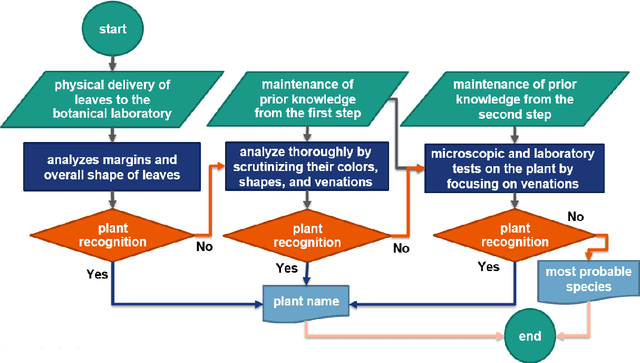
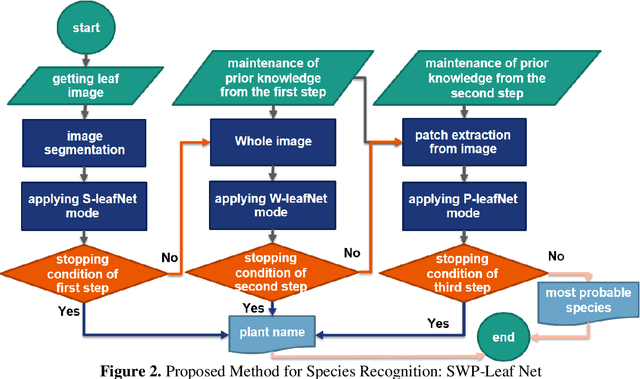

Modern scientific and technological advances are allowing botanists to use computer vision-based approaches for plant identification tasks. These approaches have their own challenges. Leaf classification is a computer-vision task performed for the automated identification of plant species, a serious challenge due to variations in leaf morphology, including its size, texture, shape, and venation. Researchers have recently become more inclined toward deep learning-based methods rather than conventional feature-based methods due to the popularity and successful implementation of deep learning methods in image analysis, object recognition, and speech recognition. In this paper, a botanist's behavior was modeled in leaf identification by proposing a highly-efficient method of maximum behavioral resemblance developed through three deep learning-based models. Different layers of the three models were visualized to ensure that the botanist's behavior was modeled accurately. The first and second models were designed from scratch.Regarding the third model, the pre-trained architecture MobileNetV2 was employed along with the transfer-learning technique. The proposed method was evaluated on two well-known datasets: Flavia and MalayaKew. According to a comparative analysis, the suggested approach was more accurate than hand-crafted feature extraction methods and other deep learning techniques in terms of 99.67% and 99.81% accuracy. Unlike conventional techniques that have their own specific complexities and depend on datasets, the proposed method required no hand-crafted feature extraction, and also increased accuracy and distributability as compared with other deep learning techniques. It was further considerably faster than other methods because it used shallower networks with fewer parameters and did not use all three models recurrently.