 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOSCAR-SGD: Local SGD with Communication-Computation Overlap and Delay-Corrected Sparse Model Averaging
May 20, 2026Communication is a major bottleneck in distributed learning, especially in large-scale settings and in federated learning environments with slow links. Three standard ways to reduce this cost are communication compression, local training, and communication-computation overlap. Methods that combine these ingredients are used in practice and have been found to be effective for large-scale training, but there is little theory for methods that combine all three. We study a heterogeneous-compute setting in which different workers may take different numbers of local steps, and we propose LOSCAR-SGD, a Local SGD method that communicates only a sparse subset of model coordinates and continues optimizing while communication is in flight. A key ingredient is a delay-corrected merge rule that incorporates delayed synchronized information without discarding the progress made during the overlap phase. We give convergence guarantees for smooth non-convex objectives and show how sparsity, overlap, and worker heterogeneity affect the rate. To the best of our knowledge, this is the first theory for this combination of ingredients. Experiments further show that communication-computation overlap reduces training time and that the delay-corrected merge outperforms naive overwriting.
Ringmaster LMO: Asynchronous Linear Minimization Oracle Momentum Method
May 18, 2026Muon has recently emerged as a strong alternative to AdamW for training neural networks, with encouraging large-scale pretraining results and growing evidence that matrix-structured updates can be faster in practice. Yet Muon, and more generally Linear Minimization Oracle (LMO) based methods, are typically used synchronously. This is problematic in heterogeneous distributed systems, where workers complete gradient computations at different speeds and synchronous training must repeatedly wait for slower workers. In this work, we introduce Ringmaster LMO, an asynchronous LMO-based momentum method for unconstrained stochastic nonconvex optimization. Our method builds on the delay-thresholding idea of Ringmaster ASGD. For SGD-type methods, Ringmaster ASGD achieves optimal time complexity by discarding overly stale gradients. Ringmaster LMO extends this mechanism to general LMO-based updates. We establish convergence guarantees under generalized $(L_0, L_1)$-smoothness and further develop a parameter-agnostic variant with decreasing stepsizes and adaptive delay thresholds. Finally, we translate our iteration guarantees into time complexity bounds under heterogeneous worker computation times. In the classical Euclidean smooth setting, these bounds recover the optimal time complexity of Ringmaster ASGD. Experiments on stochastic quadratic problems and NanoChat language-model pretraining show that the advantages of Ringmaster LMO grow with system heterogeneity and that the method outperforms strong synchronous and asynchronous baselines.
Rescaled Asynchronous SGD: Optimal Distributed Optimization under Data and System Heterogeneity
May 13, 2026Asynchronous stochastic gradient descent (ASGD) is a standard way to exploit heterogeneous compute resources in distributed learning: instead of forcing fast workers to wait for slow ones, the server updates the model whenever a gradient arrives. Vanilla ASGD applies each arriving gradient with the same weight. When local data distributions are heterogeneous, this becomes problematic: faster workers contribute more updates, and we show theoretically that the method is biased toward a frequency-weighted average of the local objectives rather than the desired global objective. Existing remedies typically move away from the simple ASGD template by introducing gathering phases, buffering, or extra memory. We show that this is unnecessary. Keeping the standard ASGD mechanism, we recover the correct objective by rescaling worker-specific stepsizes in proportion to their computation times, so that each worker contributes the same aggregate learning rate over a cycle. In the non-convex setting, under smoothness and bounded heterogeneity assumptions, we prove that the resulting method, Rescaled ASGD, converges to stationary points of the correct global objective in the fixed-computation model. Its time complexity matches the known lower bound in the leading term, while the effects of staleness and data heterogeneity appear only in lower-order terms. Experiments confirm that the method converges to the correct objective and is competitive with state-of-the-art baselines.
BiCoLoR: Communication-Efficient Optimization with Bidirectional Compression and Local Training
Jan 18, 2026Slow and costly communication is often the main bottleneck in distributed optimization, especially in federated learning where it occurs over wireless networks. We introduce BiCoLoR, a communication-efficient optimization algorithm that combines two widely used and effective strategies: local training, which increases computation between communication rounds, and compression, which encodes high-dimensional vectors into short bitstreams. While these mechanisms have been combined before, compression has typically been applied only to uplink (client-to-server) communication, leaving the downlink (server-to-client) side unaddressed. In practice, however, both directions are costly. We propose BiCoLoR, the first algorithm to combine local training with bidirectional compression using arbitrary unbiased compressors. This joint design achieves accelerated complexity guarantees in both convex and strongly convex heterogeneous settings. Empirically, BiCoLoR outperforms existing algorithms and establishes a new standard in communication efficiency.
First Provably Optimal Asynchronous SGD for Homogeneous and Heterogeneous Data
Jan 05, 2026Artificial intelligence has advanced rapidly through large neural networks trained on massive datasets using thousands of GPUs or TPUs. Such training can occupy entire data centers for weeks and requires enormous computational and energy resources. Yet the optimization algorithms behind these runs have not kept pace. Most large scale training still relies on synchronous methods, where workers must wait for the slowest device, wasting compute and amplifying the effects of hardware and network variability. Removing synchronization seems like a simple fix, but asynchrony introduces staleness, meaning updates computed on outdated models. This makes analysis difficult, especially when delays arise from system level randomness rather than algorithmic choices. As a result, the time complexity of asynchronous methods remains poorly understood. This dissertation develops a rigorous framework for asynchronous first order stochastic optimization, focusing on the core challenge of heterogeneous worker speeds. Within this framework, we show that with proper design, asynchronous SGD can achieve optimal time complexity, matching guarantees previously known only for synchronous methods. Our first contribution, Ringmaster ASGD, attains optimal time complexity in the homogeneous data setting by selectively discarding stale updates. The second, Ringleader ASGD, extends optimality to heterogeneous data, common in federated learning, using a structured gradient table mechanism. Finally, ATA improves resource efficiency by learning worker compute time distributions and allocating tasks adaptively, achieving near optimal wall clock time with less computation. Together, these results establish asynchronous optimization as a theoretically sound and practically efficient foundation for distributed learning, showing that coordination without synchronization can be both feasible and optimal.
ATA: Adaptive Task Allocation for Efficient Resource Management in Distributed Machine Learning
Feb 02, 2025Asynchronous methods are fundamental for parallelizing computations in distributed machine learning. They aim to accelerate training by fully utilizing all available resources. However, their greedy approach can lead to inefficiencies using more computation than required, especially when computation times vary across devices. If the computation times were known in advance, training could be fast and resource-efficient by assigning more tasks to faster workers. The challenge lies in achieving this optimal allocation without prior knowledge of the computation time distributions. In this paper, we propose ATA (Adaptive Task Allocation), a method that adapts to heterogeneous and random distributions of worker computation times. Through rigorous theoretical analysis, we show that ATA identifies the optimal task allocation and performs comparably to methods with prior knowledge of computation times. Experimental results further demonstrate that ATA is resource-efficient, significantly reducing costs compared to the greedy approach, which can be arbitrarily expensive depending on the number of workers.
Ringmaster ASGD: The First Asynchronous SGD with Optimal Time Complexity
Jan 27, 2025


Asynchronous Stochastic Gradient Descent (Asynchronous SGD) is a cornerstone method for parallelizing learning in distributed machine learning. However, its performance suffers under arbitrarily heterogeneous computation times across workers, leading to suboptimal time complexity and inefficiency as the number of workers scales. While several Asynchronous SGD variants have been proposed, recent findings by Tyurin & Richt\'arik (NeurIPS 2023) reveal that none achieve optimal time complexity, leaving a significant gap in the literature. In this paper, we propose Ringmaster ASGD, a novel Asynchronous SGD method designed to address these limitations and tame the inherent challenges of Asynchronous SGD. We establish, through rigorous theoretical analysis, that Ringmaster ASGD achieves optimal time complexity under arbitrarily heterogeneous and dynamically fluctuating worker computation times. This makes it the first Asynchronous SGD method to meet the theoretical lower bounds for time complexity in such scenarios.
Differentially Private Random Block Coordinate Descent
Dec 22, 2024
Coordinate Descent (CD) methods have gained significant attention in machine learning due to their effectiveness in solving high-dimensional problems and their ability to decompose complex optimization tasks. However, classical CD methods were neither designed nor analyzed with data privacy in mind, a critical concern when handling sensitive information. This has led to the development of differentially private CD methods, such as DP-CD (Differentially Private Coordinate Descent) proposed by Mangold et al. (ICML 2022), yet a disparity remains between non-private CD and DP-CD methods. In our work, we propose a differentially private random block coordinate descent method that selects multiple coordinates with varying probabilities in each iteration using sketch matrices. Our algorithm generalizes both DP-CD and the classical DP-SGD (Differentially Private Stochastic Gradient Descent), while preserving the same utility guarantees. Furthermore, we demonstrate that better utility can be achieved through importance sampling, as our method takes advantage of the heterogeneity in coordinate-wise smoothness constants, leading to improved convergence rates.
MindFlayer: Efficient Asynchronous Parallel SGD in the Presence of Heterogeneous and Random Worker Compute Times
Oct 05, 2024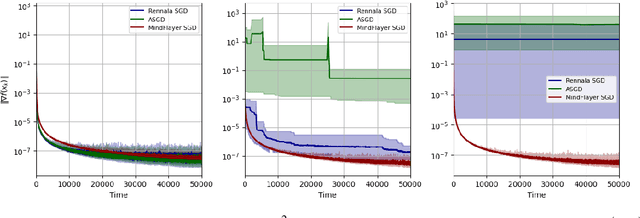

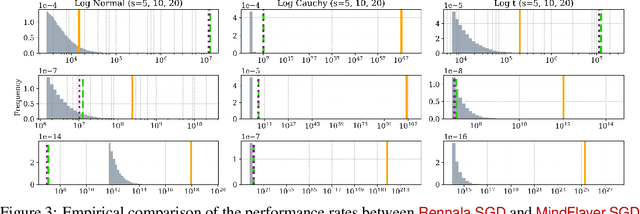

We study the problem of minimizing the expectation of smooth nonconvex functions with the help of several parallel workers whose role is to compute stochastic gradients. In particular, we focus on the challenging situation where the workers' compute times are arbitrarily heterogeneous and random. In the simpler regime characterized by arbitrarily heterogeneous but deterministic compute times, Tyurin and Richt\'arik (NeurIPS 2023) recently designed the first theoretically optimal asynchronous SGD method, called Rennala SGD, in terms of a novel complexity notion called time complexity. The starting point of our work is the observation that Rennala SGD can have arbitrarily bad performance in the presence of random compute times -- a setting it was not designed to handle. To advance our understanding of stochastic optimization in this challenging regime, we propose a new asynchronous SGD method, for which we coin the name MindFlayer SGD. Our theory and empirical results demonstrate the superiority of MindFlayer SGD over existing baselines, including Rennala SGD, in cases when the noise is heavy tailed.
LoCoDL: Communication-Efficient Distributed Learning with Local Training and Compression
Mar 07, 2024In Distributed optimization and Learning, and even more in the modern framework of federated learning, communication, which is slow and costly, is critical. We introduce LoCoDL, a communication-efficient algorithm that leverages the two popular and effective techniques of Local training, which reduces the communication frequency, and Compression, in which short bitstreams are sent instead of full-dimensional vectors of floats. LoCoDL works with a large class of unbiased compressors that includes widely-used sparsification and quantization methods. LoCoDL provably benefits from local training and compression and enjoys a doubly-accelerated communication complexity, with respect to the condition number of the functions and the model dimension, in the general heterogenous regime with strongly convex functions. This is confirmed in practice, with LoCoDL outperforming existing algorithms.