 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiCoLoR: Communication-Efficient Optimization with Bidirectional Compression and Local Training
Jan 18, 2026Slow and costly communication is often the main bottleneck in distributed optimization, especially in federated learning where it occurs over wireless networks. We introduce BiCoLoR, a communication-efficient optimization algorithm that combines two widely used and effective strategies: local training, which increases computation between communication rounds, and compression, which encodes high-dimensional vectors into short bitstreams. While these mechanisms have been combined before, compression has typically been applied only to uplink (client-to-server) communication, leaving the downlink (server-to-client) side unaddressed. In practice, however, both directions are costly. We propose BiCoLoR, the first algorithm to combine local training with bidirectional compression using arbitrary unbiased compressors. This joint design achieves accelerated complexity guarantees in both convex and strongly convex heterogeneous settings. Empirically, BiCoLoR outperforms existing algorithms and establishes a new standard in communication efficiency.
Prune at the Clients, Not the Server: Accelerated Sparse Training in Federated Learning
May 31, 2024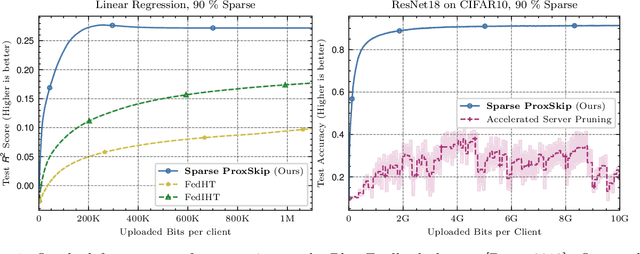
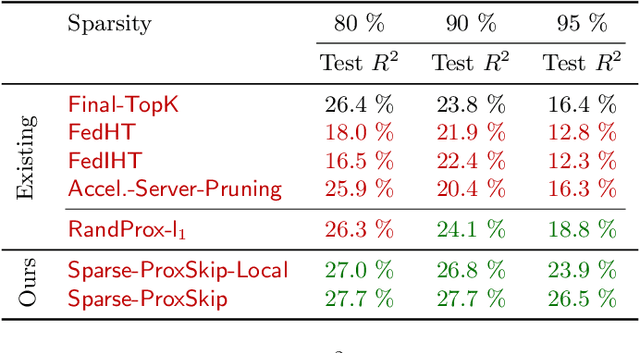
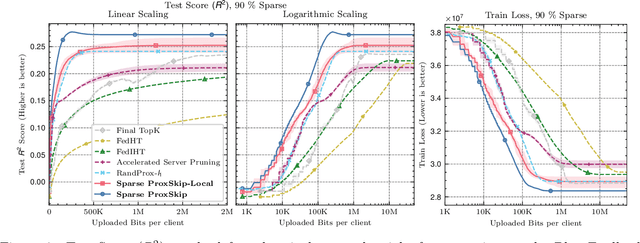
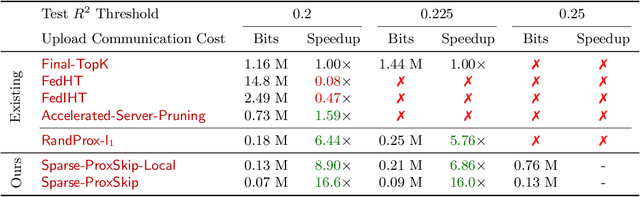
In the recent paradigm of Federated Learning (FL), multiple clients train a shared model while keeping their local data private. Resource constraints of clients and communication costs pose major problems for training large models in FL. On the one hand, addressing the resource limitations of the clients, sparse training has proven to be a powerful tool in the centralized setting. On the other hand, communication costs in FL can be addressed by local training, where each client takes multiple gradient steps on its local data. Recent work has shown that local training can provably achieve the optimal accelerated communication complexity [Mishchenko et al., 2022]. Hence, one would like an accelerated sparse training algorithm. In this work we show that naive integration of sparse training and acceleration at the server fails, and how to fix it by letting the clients perform these tasks appropriately. We introduce Sparse-ProxSkip, our method developed for the nonconvex setting, inspired by RandProx [Condat and Richt\'arik, 2022], which provably combines sparse training and acceleration in the convex setting. We demonstrate the good performance of Sparse-ProxSkip in extensive experiments.
FedComLoc: Communication-Efficient Distributed Training of Sparse and Quantized Models
Mar 14, 2024Federated Learning (FL) has garnered increasing attention due to its unique characteristic of allowing heterogeneous clients to process their private data locally and interact with a central server, while being respectful of privacy. A critical bottleneck in FL is the communication cost. A pivotal strategy to mitigate this burden is \emph{Local Training}, which involves running multiple local stochastic gradient descent iterations between communication phases. Our work is inspired by the innovative \emph{Scaffnew} algorithm, which has considerably advanced the reduction of communication complexity in FL. We introduce FedComLoc (Federated Compressed and Local Training), integrating practical and effective compression into \emph{Scaffnew} to further enhance communication efficiency. Extensive experiments, using the popular TopK compressor and quantization, demonstrate its prowess in substantially reducing communication overheads in heterogeneous settings.
LoCoDL: Communication-Efficient Distributed Learning with Local Training and Compression
Mar 07, 2024In Distributed optimization and Learning, and even more in the modern framework of federated learning, communication, which is slow and costly, is critical. We introduce LoCoDL, a communication-efficient algorithm that leverages the two popular and effective techniques of Local training, which reduces the communication frequency, and Compression, in which short bitstreams are sent instead of full-dimensional vectors of floats. LoCoDL works with a large class of unbiased compressors that includes widely-used sparsification and quantization methods. LoCoDL provably benefits from local training and compression and enjoys a doubly-accelerated communication complexity, with respect to the condition number of the functions and the model dimension, in the general heterogenous regime with strongly convex functions. This is confirmed in practice, with LoCoDL outperforming existing algorithms.
RandCom: Random Communication Skipping Method for Decentralized Stochastic Optimization
Oct 12, 2023Distributed optimization methods with random communication skips are gaining increasing attention due to their proven benefits in accelerating communication complexity. Nevertheless, existing research mainly focuses on centralized communication protocols for strongly convex deterministic settings. In this work, we provide a decentralized optimization method called RandCom, which incorporates probabilistic local updates. We analyze the performance of RandCom in stochastic non-convex, convex, and strongly convex settings and demonstrate its ability to asymptotically reduce communication overhead by the probability of communication. Additionally, we prove that RandCom achieves linear speedup as the number of nodes increases. In stochastic strongly convex settings, we further prove that RandCom can achieve linear speedup with network-independent stepsizes. Moreover, we apply RandCom to federated learning and provide positive results concerning the potential for achieving linear speedup and the suitability of the probabilistic local update approach for non-convex settings.
Near-Linear Time Projection onto the $\ell_{1,\infty}$ Ball; Application to Sparse Autoencoders
Jul 19, 2023Looking for sparsity is nowadays crucial to speed up the training of large-scale neural networks. Projections onto the $\ell_{1,2}$ and $\ell_{1,\infty}$ are among the most efficient techniques to sparsify and reduce the overall cost of neural networks. In this paper, we introduce a new projection algorithm for the $\ell_{1,\infty}$ norm ball. The worst-case time complexity of this algorithm is $\mathcal{O}\big(nm+J\log(nm)\big)$ for a matrix in $\mathbb{R}^{n\times m}$. $J$ is a term that tends to 0 when the sparsity is high, and to $nm$ when the sparsity is low. Its implementation is easy and it is guaranteed to converge to the exact solution in a finite time. Moreover, we propose to incorporate the $\ell_{1,\infty}$ ball projection while training an autoencoder to enforce feature selection and sparsity of the weights. Sparsification appears in the encoder to primarily do feature selection due to our application in biology, where only a very small part ($<2\%$) of the data is relevant. We show that both in the biological case and in the general case of sparsity that our method is the fastest.
Explicit Personalization and Local Training: Double Communication Acceleration in Federated Learning
May 22, 2023



Federated Learning is an evolving machine learning paradigm, in which multiple clients perform computations based on their individual private data, interspersed by communication with a remote server. A common strategy to curtail communication costs is Local Training, which consists in performing multiple local stochastic gradient descent steps between successive communication rounds. However, the conventional approach to local training overlooks the practical necessity for client-specific personalization, a technique to tailor local models to individual needs. We introduce Scafflix, a novel algorithm that efficiently integrates explicit personalization with local training. This innovative approach benefits from these two techniques, thereby achieving doubly accelerated communication, as we demonstrate both in theory and practice.
TAMUNA: Accelerated Federated Learning with Local Training and Partial Participation
Feb 20, 2023In federated learning, a large number of users are involved in a global learning task, in a collaborative way. They alternate local computations and communication with a distant server. Communication, which can be slow and costly, is the main bottleneck in this setting. To accelerate distributed gradient descent, the popular strategy of local training is to communicate less frequently; that is, to perform several iterations of local computations between the communication steps. A recent breakthrough in this field was made by Mishchenko et al. (2022): their Scaffnew algorithm is the first to probably benefit from local training, with accelerated communication complexity. However, it was an open and challenging question to know whether the powerful mechanism behind Scaffnew would be compatible with partial participation, the desirable feature that not all clients need to participate to every round of the training process. We answer this question positively and propose a new algorithm, which handles local training and partial participation, with state-of-the-art communication complexity.
Provably Doubly Accelerated Federated Learning: The First Theoretically Successful Combination of Local Training and Compressed Communication
Oct 27, 2022



In the modern paradigm of federated learning, a large number of users are involved in a global learning task, in a collaborative way. They alternate local computations and two-way communication with a distant orchestrating server. Communication, which can be slow and costly, is the main bottleneck in this setting. To reduce the communication load and therefore accelerate distributed gradient descent, two strategies are popular: 1) communicate less frequently; that is, perform several iterations of local computations between the communication rounds; and 2) communicate compressed information instead of full-dimensional vectors. In this paper, we propose the first algorithm for distributed optimization and federated learning, which harnesses these two strategies jointly and converges linearly to an exact solution, with a doubly accelerated rate: our algorithm benefits from the two acceleration mechanisms provided by local training and compression, namely a better dependency on the condition number of the functions and on the dimension of the model, respectively.
Joint Demosaicing and Fusion of Multiresolution Compressed Acquisitions: Image Formation and Reconstruction Methods
Sep 10, 2022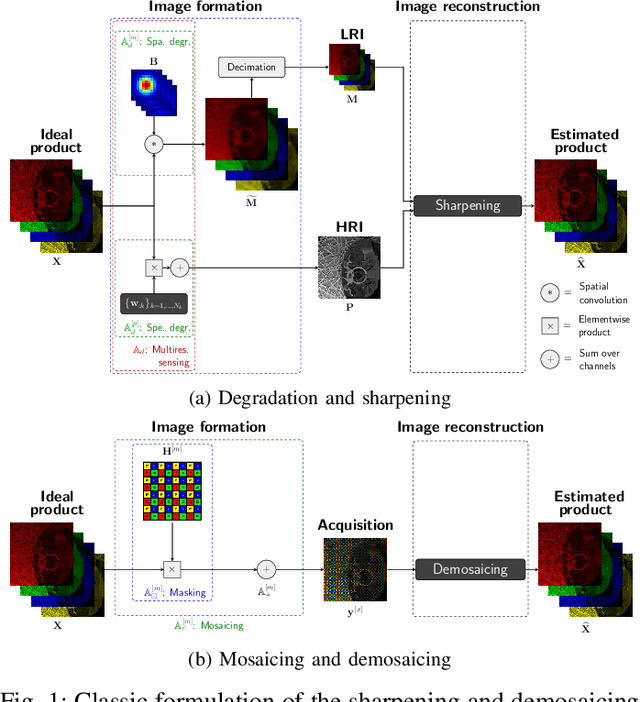
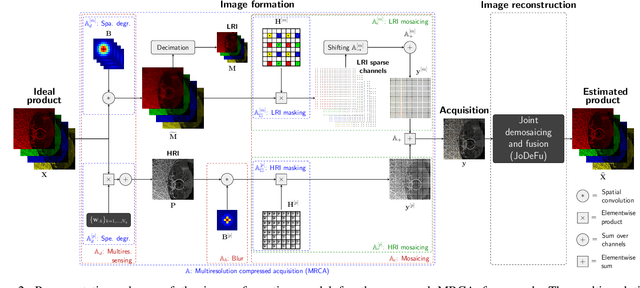
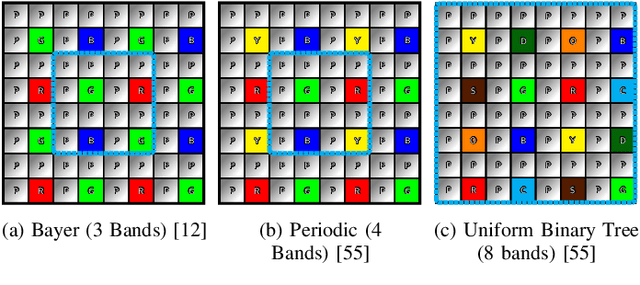
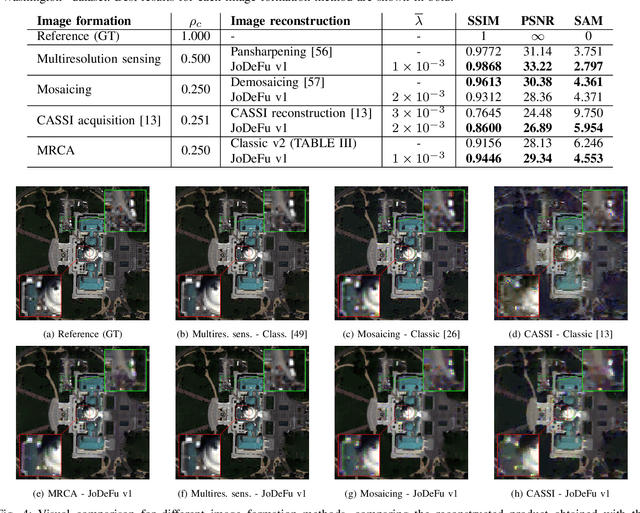
Novel optical imaging devices allow for hybrid acquisition modalities such as compressed acquisitions with locally different spatial and spectral resolutions captured by the same focal plane array. In this work, we propose to model a multiresolution compressed acquisition (MRCA) in a generic framework, which natively includes acquisitions by conventional systems such as those based on spectral/color filter arrays, compressed coded apertures, and multiresolution sensing. We propose a model-based image reconstruction algorithm performing a joint demosaicing and fusion (JoDeFu) of any acquisition modeled in the MRCA framework. The JoDeFu reconstruction algorithm solves an inverse problem with a proximal splitting technique and is able to reconstruct an uncompressed image datacube at the highest available spatial and spectral resolution. An implementation of the code is available at https://github.com/danaroth83/jodefu.