 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapley-Guided Neural Repair Approach via Derivative-Free Optimization
Apr 01, 2026DNNs are susceptible to defects like backdoors, adversarial attacks, and unfairness, undermining their reliability. Existing approaches mainly involve retraining, optimization, constraint-solving, or search algorithms. However, most methods rely on gradient calculations, restricting applicability to specific activation functions (e.g., ReLU), or use search algorithms with uninterpretable localization and repair. Furthermore, they often lack generalizability across multiple properties. We propose SHARPEN, integrating interpretable fault localization with a derivative-free optimization strategy. First, SHARPEN introduces a Deep SHAP-based localization strategy quantifying each layer's and neuron's marginal contribution to erroneous outputs. Specifically, a hierarchical coarse-to-fine approach reranks layers by aggregated impact, then locates faulty neurons/filters by analyzing activation divergences between property-violating and benign states. Subsequently, SHARPEN incorporates CMA-ES to repair identified neurons. CMA-ES leverages a covariance matrix to capture variable dependencies, enabling gradient-free search and coordinated adjustments across coupled neurons. By combining interpretable localization with evolutionary optimization, SHARPEN enables derivative-free repair across architectures, being less sensitive to gradient anomalies and hyperparameters. We demonstrate SHARPEN's effectiveness on three repair tasks. Balancing property repair and accuracy preservation, it outperforms baselines in backdoor removal (+10.56%), adversarial mitigation (+5.78%), and unfairness repair (+11.82%). Notably, SHARPEN handles diverse tasks, and its modular design is plug-and-play with different derivative-free optimizers, highlighting its flexibility.
Causal Representation Learning with Optimal Compression under Complex Treatments
Mar 12, 2026Estimating Individual Treatment Effects (ITE) in multi-treatment scenarios faces two critical challenges: the Hyperparameter Selection Dilemma for balancing weights and the Curse of Dimensionality in computational scalability. This paper derives a novel multi-treatment generalization bound and proposes a theoretical estimator for the optimal balancing weight $α$, eliminating expensive heuristic tuning. We investigate three balancing strategies: Pairwise, One-vs-All (OVA), and Treatment Aggregation. While OVA achieves superior precision in low-dimensional settings, our proposed Treatment Aggregation ensures both accuracy and O(1) scalability as the treatment space expands. Furthermore, we extend our framework to a generative architecture, Multi-Treatment CausalEGM, which preserves the Wasserstein geodesic structure of the treatment manifold. Experiments on semi-synthetic and image datasets demonstrate that our approach significantly outperforms traditional models in estimation accuracy and efficiency, particularly in large-scale intervention scenarios.
Breaking the Gradient Barrier: Unveiling Large Language Models for Strategic Classification
Nov 10, 2025Strategic classification~(SC) explores how individuals or entities modify their features strategically to achieve favorable classification outcomes. However, existing SC methods, which are largely based on linear models or shallow neural networks, face significant limitations in terms of scalability and capacity when applied to real-world datasets with significantly increasing scale, especially in financial services and the internet sector. In this paper, we investigate how to leverage large language models to design a more scalable and efficient SC framework, especially in the case of growing individuals engaged with decision-making processes. Specifically, we introduce GLIM, a gradient-free SC method grounded in in-context learning. During the feed-forward process of self-attention, GLIM implicitly simulates the typical bi-level optimization process of SC, including both the feature manipulation and decision rule optimization. Without fine-tuning the LLMs, our proposed GLIM enjoys the advantage of cost-effective adaptation in dynamic strategic environments. Theoretically, we prove GLIM can support pre-trained LLMs to adapt to a broad range of strategic manipulations. We validate our approach through experiments with a collection of pre-trained LLMs on real-world and synthetic datasets in financial and internet domains, demonstrating that our GLIM exhibits both robustness and efficiency, and offering an effective solution for large-scale SC tasks.
Look Within, Why LLMs Hallucinate: A Causal Perspective
Jul 14, 2024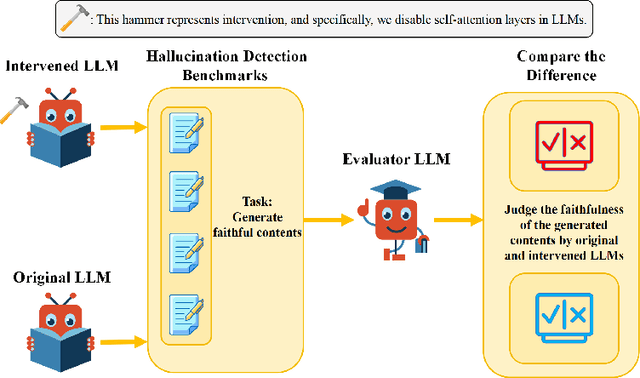



The emergence of large language models (LLMs) is a milestone in generative artificial intelligence, achieving significant success in text comprehension and generation tasks. Despite the tremendous success of LLMs in many downstream tasks, they suffer from severe hallucination problems, posing significant challenges to the practical applications of LLMs. Most of the works about LLMs' hallucinations focus on data quality. Self-attention is a core module in transformer-based LLMs, while its potential relationship with LLMs' hallucination has been hardly investigated. To fill this gap, we study this problem from a causal perspective. We propose a method to intervene in LLMs' self-attention layers and maintain their structures and sizes intact. Specifically, we disable different self-attention layers in several popular open-source LLMs and then compare their degrees of hallucination with the original ones. We evaluate the intervened LLMs on hallucination assessment benchmarks and conclude that disabling some specific self-attention layers in the front or tail of the LLMs can alleviate hallucination issues. The study paves a new way for understanding and mitigating LLMs' hallucinations.
Are All Unseen Data Out-of-Distribution?
Jan 02, 2024



Distributions of unseen data have been all treated as out-of-distribution (OOD), making their generalization a significant challenge. Much evidence suggests that the size increase of training data can monotonically decrease generalization errors in test data. However, this is not true from other observations and analysis. In particular, when the training data have multiple source domains and the test data contain distribution drifts, then not all generalization errors on the test data decrease monotonically with the increasing size of training data. Such a non-decreasing phenomenon is formally investigated under a linear setting with empirical verification across varying visual benchmarks. Motivated by these results, we redefine the OOD data as a type of data outside the convex hull of the training domains and prove a new generalization bound based on this new definition. It implies that the effectiveness of a well-trained model can be guaranteed for the unseen data that is within the convex hull of the training domains. But, for some data beyond the convex hull, a non-decreasing error trend can happen. Therefore, we investigate the performance of popular strategies such as data augmentation and pre-training to overcome this issue. Moreover, we propose a novel reinforcement learning selection algorithm in the source domains only that can deliver superior performance over the baseline methods.
Diversity-enhancing Generative Network for Few-shot Hypothesis Adaptation
Jul 12, 2023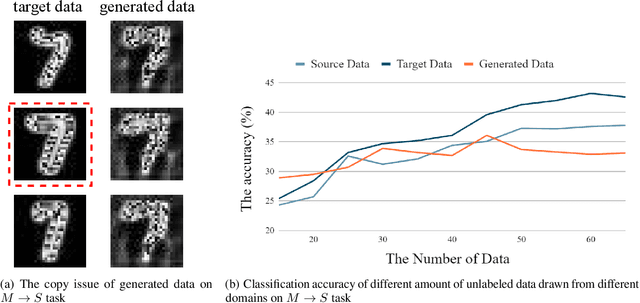
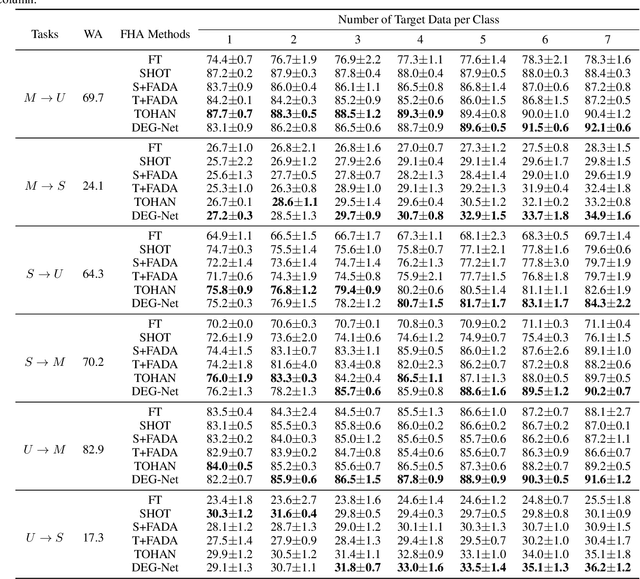
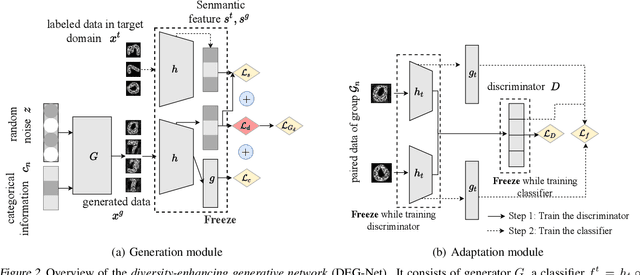

Generating unlabeled data has been recently shown to help address the few-shot hypothesis adaptation (FHA) problem, where we aim to train a classifier for the target domain with a few labeled target-domain data and a well-trained source-domain classifier (i.e., a source hypothesis), for the additional information of the highly-compatible unlabeled data. However, the generated data of the existing methods are extremely similar or even the same. The strong dependency among the generated data will lead the learning to fail. In this paper, we propose a diversity-enhancing generative network (DEG-Net) for the FHA problem, which can generate diverse unlabeled data with the help of a kernel independence measure: the Hilbert-Schmidt independence criterion (HSIC). Specifically, DEG-Net will generate data via minimizing the HSIC value (i.e., maximizing the independence) among the semantic features of the generated data. By DEG-Net, the generated unlabeled data are more diverse and more effective for addressing the FHA problem. Experimental results show that the DEG-Net outperforms existing FHA baselines and further verifies that generating diverse data plays a vital role in addressing the FHA problem
Multi-scale Knowledge Distillation for Unsupervised Person Re-Identification
Apr 21, 2022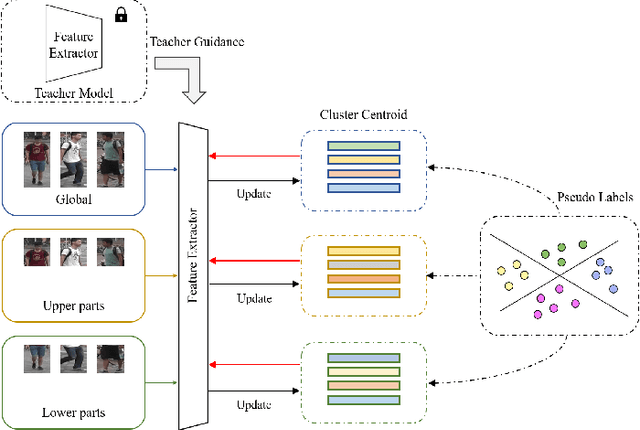
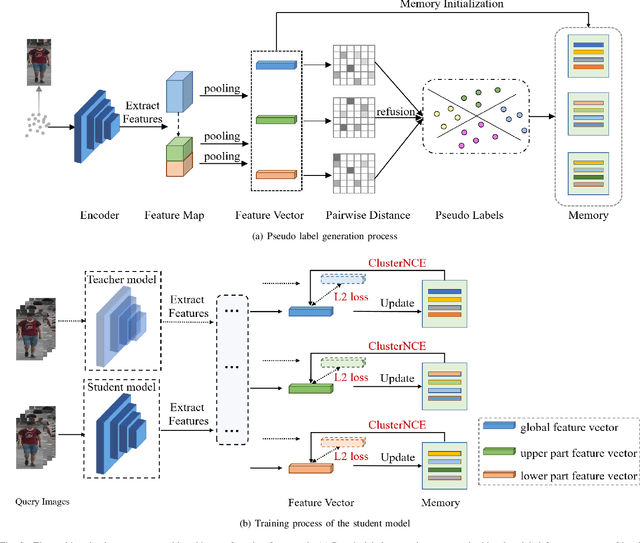
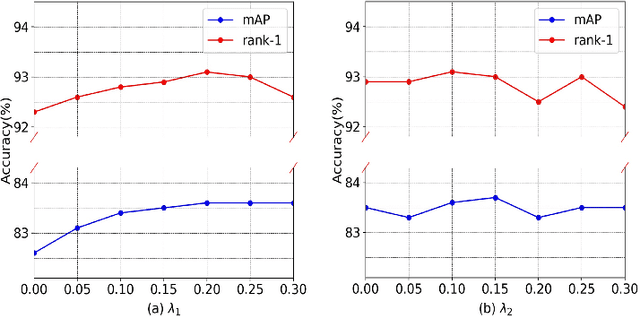
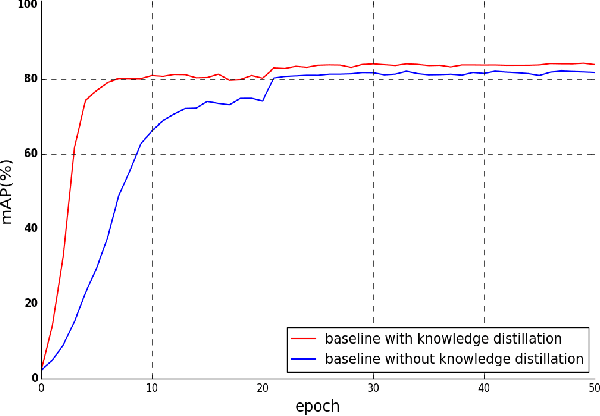
Unsupervised person re-identification is a challenging and promising task in the computer vision. Nowadays unsupervised person re-identification methods have achieved great improvements by training with pseudo labels. However, the appearance and label noise are less explicitly studied in the unsupervised manner. To relieve the effects of appearance noise the global features involved, we also take into account the features from two local views and produce multi-scale features. We explore the knowledge distillation to filter label noise, Specifically, we first train a teacher model from noisy pseudo labels in a iterative way, and then use the teacher model to guide the learning of our student model. In our setting, the student model could converge fast in the supervision of the teacher model thus reduce the interference of noisy labels as the teacher model greatly suffered. After carefully handling the noises in the feature learning, Our multi-scale knowledge distillation are proven to be very effective in the unsupervised re-identification. Extensive experiments on three popular person re-identification datasets demonstrate the superiority of our method. Especially, our approach achieves a state-of-the-art accuracy 85.7% @mAP or 94.3% @Rank-1 on the challenging Market-1501 benchmark with ResNet-50 under the fully unsupervised setting.
TOHAN: A One-step Approach towards Few-shot Hypothesis Adaptation
Jun 11, 2021
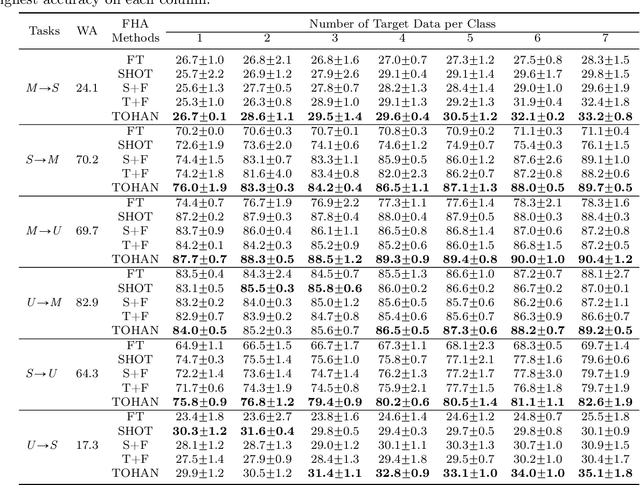
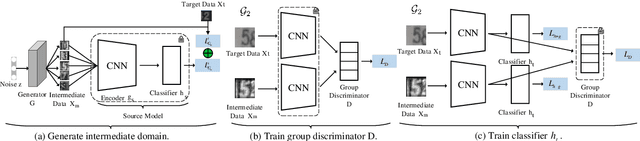

In few-shot domain adaptation (FDA), classifiers for the target domain are trained with accessible labeled data in the source domain (SD) and few labeled data in the target domain (TD). However, data usually contain private information in the current era, e.g., data distributed on personal phones. Thus, the private information will be leaked if we directly access data in SD to train a target-domain classifier (required by FDA methods). In this paper, to thoroughly prevent the privacy leakage in SD, we consider a very challenging problem setting, where the classifier for the TD has to be trained using few labeled target data and a well-trained SD classifier, named few-shot hypothesis adaptation (FHA). In FHA, we cannot access data in SD, as a result, the private information in SD will be protected well. To this end, we propose a target orientated hypothesis adaptation network (TOHAN) to solve the FHA problem, where we generate highly-compatible unlabeled data (i.e., an intermediate domain) to help train a target-domain classifier. TOHAN maintains two deep networks simultaneously, where one focuses on learning an intermediate domain and the other takes care of the intermediate-to-target distributional adaptation and the target-risk minimization. Experimental results show that TOHAN outperforms competitive baselines significantly.
Meta Discovery: Learning to Discover Novel Classes given Very Limited Data
Feb 18, 2021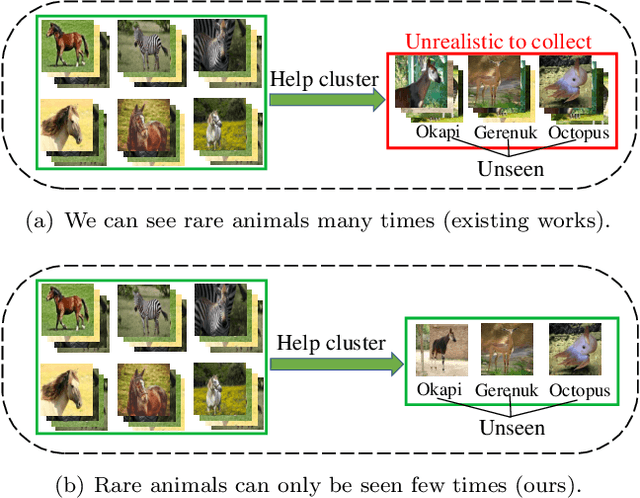

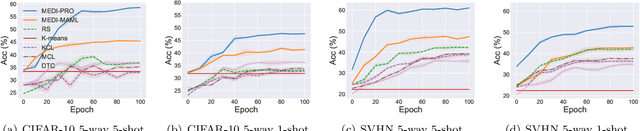
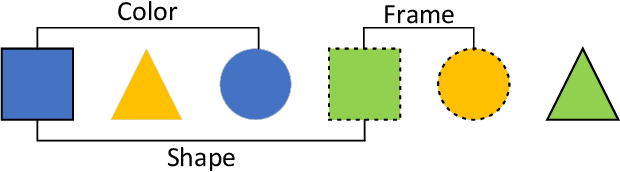
In learning to discover novel classes(L2DNC), we are given labeled data from seen classes and unlabeled data from unseen classes, and we need to train clustering models for the unseen classes. Since L2DNC is a new problem, its application scenario and implicit assumption are unclear. In this paper, we analyze and improve it by linking it to meta-learning: although there are no meta-training and meta-test phases, the underlying assumption is exactly the same, namely high-level semantic features are shared among the seen and unseen classes. Under this assumption, L2DNC is not only theoretically solvable, but also can be empirically solved by meta-learning algorithms slightly modified to fit our proposed framework. This L2DNC methodology significantly reduces the amount of unlabeled data needed for training and makes it more practical, as demonstrated in experiments. The use of very limited data is also justified by the application scenario of L2DNC: since it is unnatural to label only seen-class data, L2DNC is causally sampling instead of labeling. The unseen-class data should be collected on the way of collecting seen-class data, which is why they are novel and first need to be clustered.