 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Within, Why LLMs Hallucinate: A Causal Perspective
Paper and Code
Jul 14, 2024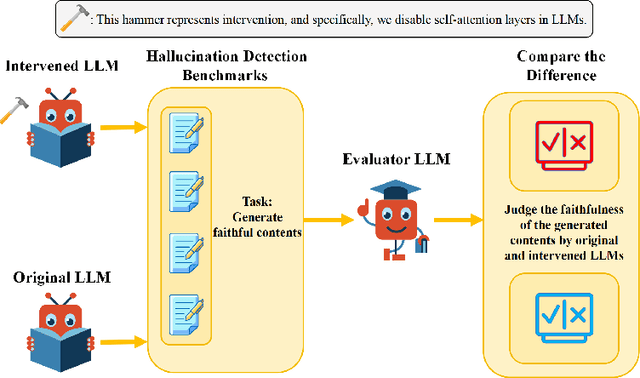



The emergence of large language models (LLMs) is a milestone in generative artificial intelligence, achieving significant success in text comprehension and generation tasks. Despite the tremendous success of LLMs in many downstream tasks, they suffer from severe hallucination problems, posing significant challenges to the practical applications of LLMs. Most of the works about LLMs' hallucinations focus on data quality. Self-attention is a core module in transformer-based LLMs, while its potential relationship with LLMs' hallucination has been hardly investigated. To fill this gap, we study this problem from a causal perspective. We propose a method to intervene in LLMs' self-attention layers and maintain their structures and sizes intact. Specifically, we disable different self-attention layers in several popular open-source LLMs and then compare their degrees of hallucination with the original ones. We evaluate the intervened LLMs on hallucination assessment benchmarks and conclude that disabling some specific self-attention layers in the front or tail of the LLMs can alleviate hallucination issues. The study paves a new way for understanding and mitigating LLMs' hallucinations.