 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case Study Investigating the Role of Generative AI in Quality Evaluations of Epics in Agile Software Development
May 12, 2025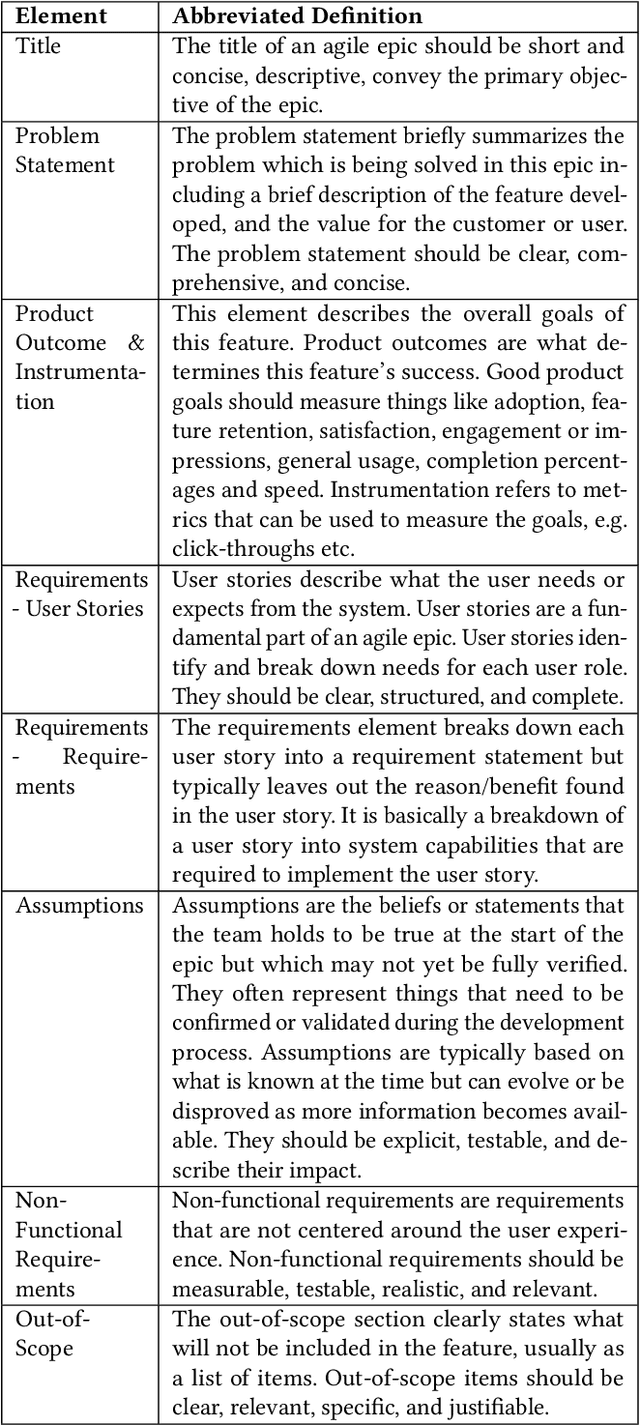
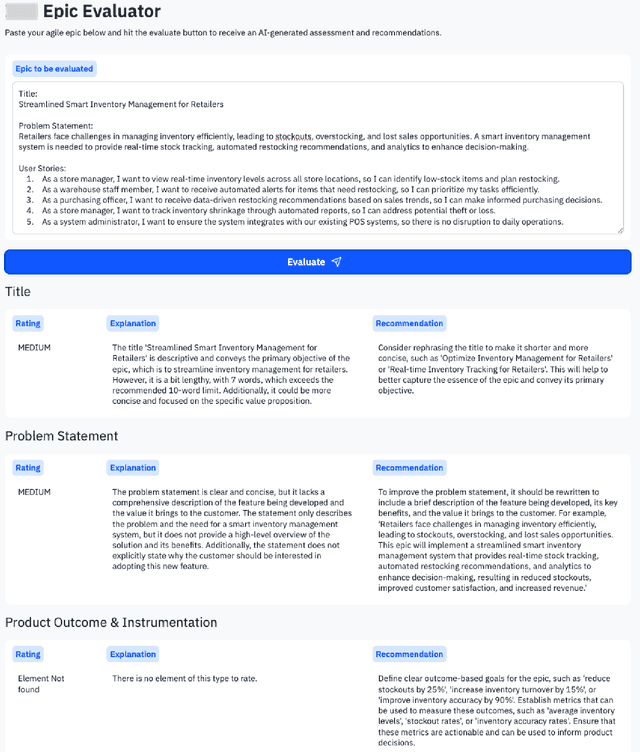
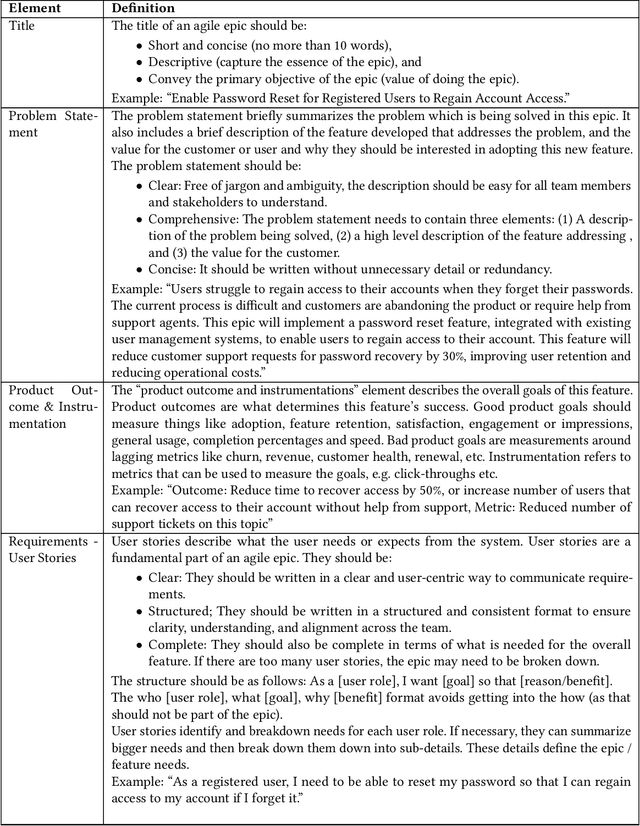
The broad availability of generative AI offers new opportunities to support various work domains, including agile software development. Agile epics are a key artifact for product managers to communicate requirements to stakeholders. However, in practice, they are often poorly defined, leading to churn, delivery delays, and cost overruns. In this industry case study, we investigate opportunities for large language models (LLMs) to evaluate agile epic quality in a global company. Results from a user study with 17 product managers indicate how LLM evaluations could be integrated into their work practices, including perceived values and usage in improving their epics. High levels of satisfaction indicate that agile epics are a new, viable application of AI evaluations. However, our findings also outline challenges, limitations, and adoption barriers that can inform both practitioners and researchers on the integration of such evaluations into future agile work practices.
"The Diagram is like Guardrails": Structuring GenAI-assisted Hypotheses Exploration with an Interactive Shared Representation
Mar 21, 2025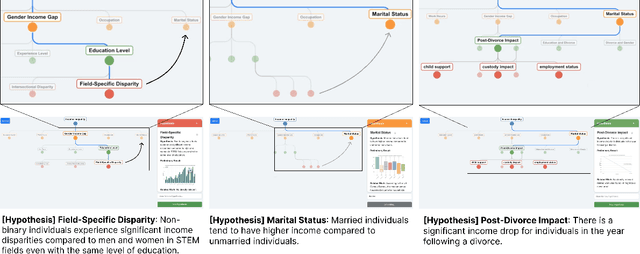
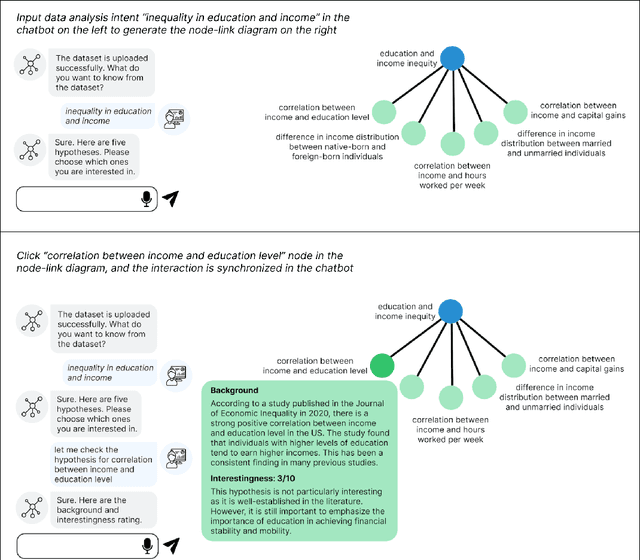
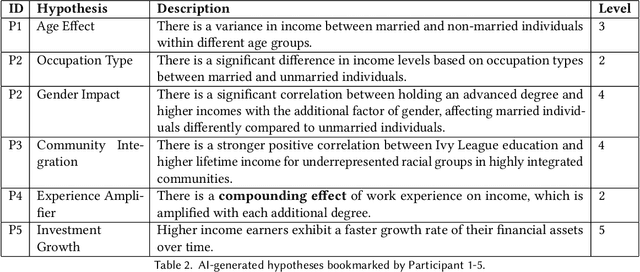
Data analysis encompasses a spectrum of tasks, from high-level conceptual reasoning to lower-level execution. While AI-powered tools increasingly support execution tasks, there remains a need for intelligent assistance in conceptual tasks. This paper investigates the design of an ordered node-link tree interface augmented with AI-generated information hints and visualizations, as a potential shared representation for hypothesis exploration. Through a design probe (n=22), participants generated diagrams averaging 21.82 hypotheses. Our findings showed that the node-link diagram acts as "guardrails" for hypothesis exploration, facilitating structured workflows, providing comprehensive overviews, and enabling efficient backtracking. The AI-generated information hints, particularly visualizations, aided users in transforming abstract ideas into data-backed concepts while reducing cognitive load. We further discuss how node-link diagrams can support both parallel exploration and iterative refinement in hypothesis formulation, potentially enhancing the breadth and depth of human-AI collaborative data analysis.
Design and Evaluation of Camera-Centric Mobile Crowdsourcing Applications
Sep 04, 2024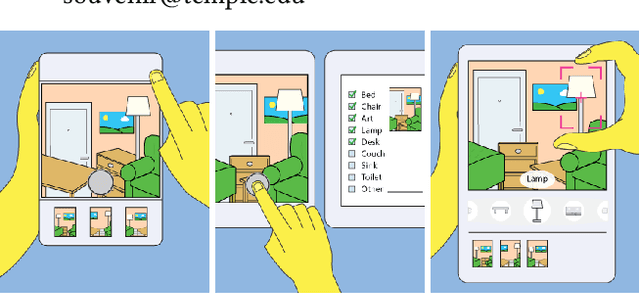
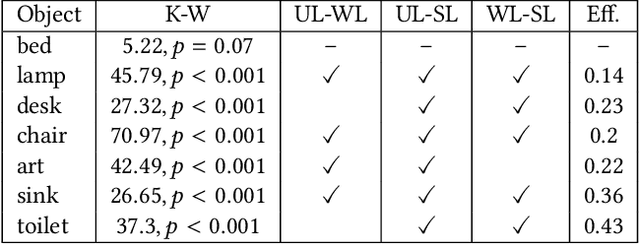
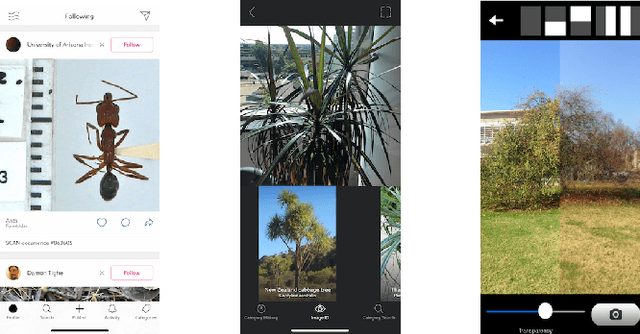
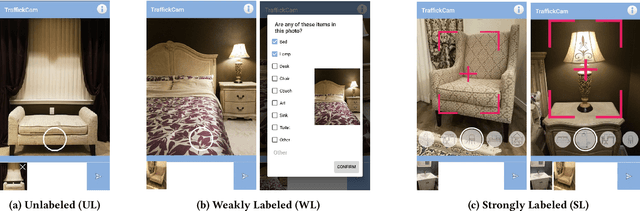
The data that underlies automated methods in computer vision and machine learning, such as image retrieval and fine-grained recognition, often comes from crowdsourcing. In contexts that rely on the intrinsic motivation of users, we seek to understand how the application design affects a user's willingness to contribute and the quantity and quality of the data they capture. In this project, we designed three versions of a camera-based mobile crowdsourcing application, which varied in the amount of labeling effort requested of the user and conducted a user study to evaluate the trade-off between the level of user-contributed information requested and the quantity and quality of labeled images collected. The results suggest that higher levels of user labeling do not lead to reduced contribution. Users collected and annotated the most images using the application version with the highest requested level of labeling with no decrease in user satisfaction. In preliminary experiments, the additional labeled data supported increased performance on an image retrieval task.
Exploring Prompt Engineering Practices in the Enterprise
Mar 13, 2024


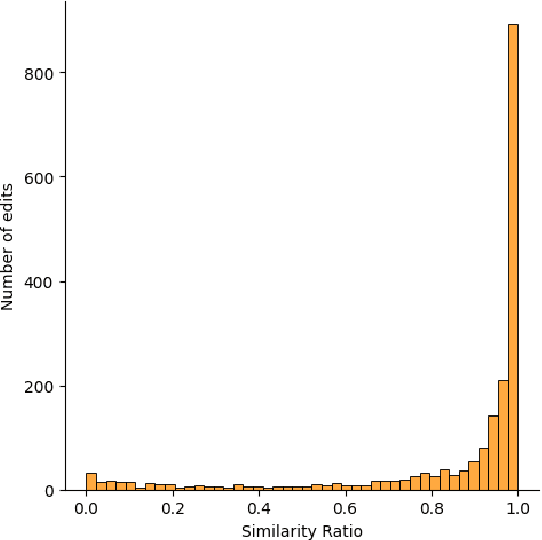
Interaction with Large Language Models (LLMs) is primarily carried out via prompting. A prompt is a natural language instruction designed to elicit certain behaviour or output from a model. In theory, natural language prompts enable non-experts to interact with and leverage LLMs. However, for complex tasks and tasks with specific requirements, prompt design is not trivial. Creating effective prompts requires skill and knowledge, as well as significant iteration in order to determine model behavior, and guide the model to accomplish a particular goal. We hypothesize that the way in which users iterate on their prompts can provide insight into how they think prompting and models work, as well as the kinds of support needed for more efficient prompt engineering. To better understand prompt engineering practices, we analyzed sessions of prompt editing behavior, categorizing the parts of prompts users iterated on and the types of changes they made. We discuss design implications and future directions based on these prompt engineering practices.