 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Evaluation of Camera-Centric Mobile Crowdsourcing Applications
Sep 04, 2024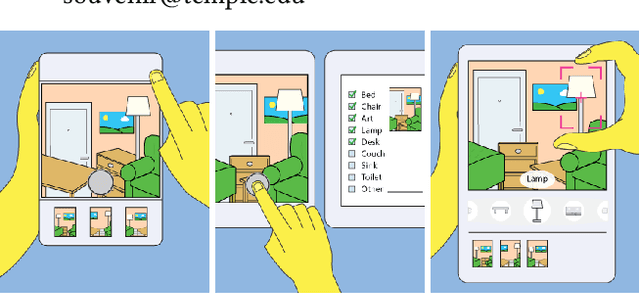
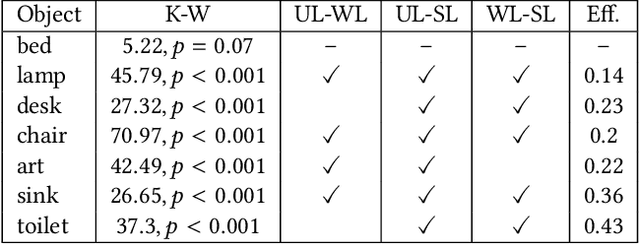
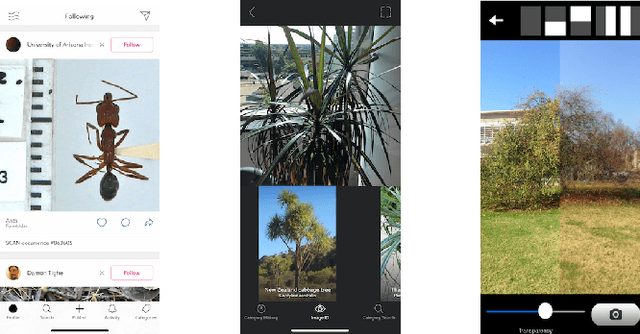
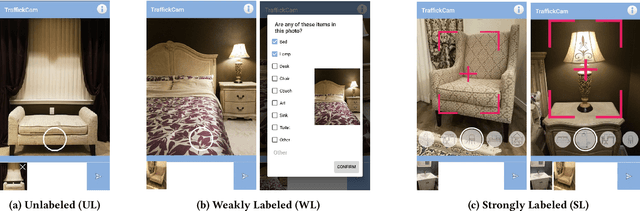
The data that underlies automated methods in computer vision and machine learning, such as image retrieval and fine-grained recognition, often comes from crowdsourcing. In contexts that rely on the intrinsic motivation of users, we seek to understand how the application design affects a user's willingness to contribute and the quantity and quality of the data they capture. In this project, we designed three versions of a camera-based mobile crowdsourcing application, which varied in the amount of labeling effort requested of the user and conducted a user study to evaluate the trade-off between the level of user-contributed information requested and the quantity and quality of labeled images collected. The results suggest that higher levels of user labeling do not lead to reduced contribution. Users collected and annotated the most images using the application version with the highest requested level of labeling with no decrease in user satisfaction. In preliminary experiments, the additional labeled data supported increased performance on an image retrieval task.
Comparing Traditional and LLM-based Search for Image Geolocation
Jan 18, 2024



Web search engines have long served as indispensable tools for information retrieval; user behavior and query formulation strategies have been well studied. The introduction of search engines powered by large language models (LLMs) suggested more conversational search and new types of query strategies. In this paper, we compare traditional and LLM-based search for the task of image geolocation, i.e., determining the location where an image was captured. Our work examines user interactions, with a particular focus on query formulation strategies. In our study, 60 participants were assigned either traditional or LLM-based search engines as assistants for geolocation. Participants using traditional search more accurately predicted the location of the image compared to those using the LLM-based search. Distinct strategies emerged between users depending on the type of assistant. Participants using the LLM-based search issued longer, more natural language queries, but had shorter search sessions. When reformulating their search queries, traditional search participants tended to add more terms to their initial queries, whereas participants using the LLM-based search consistently rephrased their initial queries.