 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Evaluation of Camera-Centric Mobile Crowdsourcing Applications
Sep 04, 2024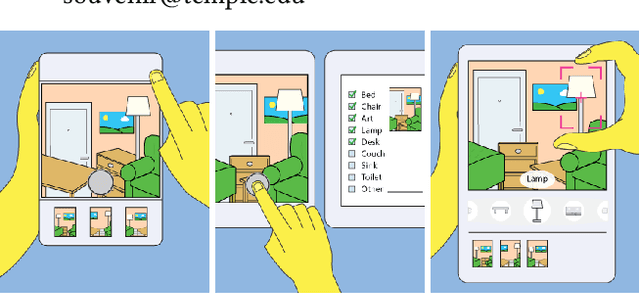
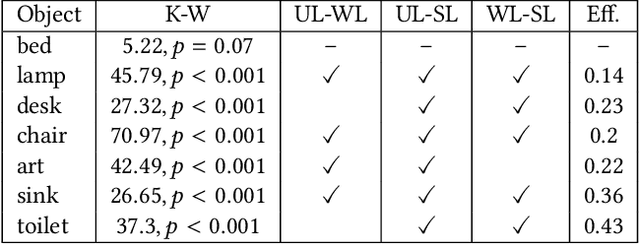
The data that underlies automated methods in computer vision and machine learning, such as image retrieval and fine-grained recognition, often comes from crowdsourcing. In contexts that rely on the intrinsic motivation of users, we seek to understand how the application design affects a user's willingness to contribute and the quantity and quality of the data they capture. In this project, we designed three versions of a camera-based mobile crowdsourcing application, which varied in the amount of labeling effort requested of the user and conducted a user study to evaluate the trade-off between the level of user-contributed information requested and the quantity and quality of labeled images collected. The results suggest that higher levels of user labeling do not lead to reduced contribution. Users collected and annotated the most images using the application version with the highest requested level of labeling with no decrease in user satisfaction. In preliminary experiments, the additional labeled data supported increased performance on an image retrieval task.
Comparing Traditional and LLM-based Search for Image Geolocation
Jan 18, 2024



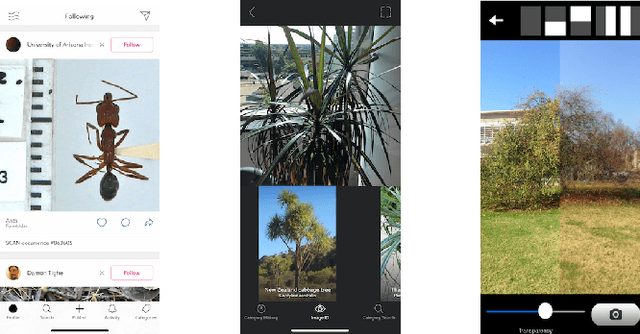
Web search engines have long served as indispensable tools for information retrieval; user behavior and query formulation strategies have been well studied. The introduction of search engines powered by large language models (LLMs) suggested more conversational search and new types of query strategies. In this paper, we compare traditional and LLM-based search for the task of image geolocation, i.e., determining the location where an image was captured. Our work examines user interactions, with a particular focus on query formulation strategies. In our study, 60 participants were assigned either traditional or LLM-based search engines as assistants for geolocation. Participants using traditional search more accurately predicted the location of the image compared to those using the LLM-based search. Distinct strategies emerged between users depending on the type of assistant. Participants using the LLM-based search issued longer, more natural language queries, but had shorter search sessions. When reformulating their search queries, traditional search participants tended to add more terms to their initial queries, whereas participants using the LLM-based search consistently rephrased their initial queries.
Federated Compositional Deep AUC Maximization
Apr 20, 2023



Federated learning has attracted increasing attention due to the promise of balancing privacy and large-scale learning; numerous approaches have been proposed. However, most existing approaches focus on problems with balanced data, and prediction performance is far from satisfactory for many real-world applications where the number of samples in different classes is highly imbalanced. To address this challenging problem, we developed a novel federated learning method for imbalanced data by directly optimizing the area under curve (AUC) score. In particular, we formulate the AUC maximization problem as a federated compositional minimax optimization problem, develop a local stochastic compositional gradient descent ascent with momentum algorithm, and provide bounds on the computational and communication complexities of our algorithm. To the best of our knowledge, this is the first work to achieve such favorable theoretical results. Finally, extensive experimental results confirm the efficacy of our method.
TraffickCam: Explainable Image Matching For Sex Trafficking Investigations
Oct 08, 2019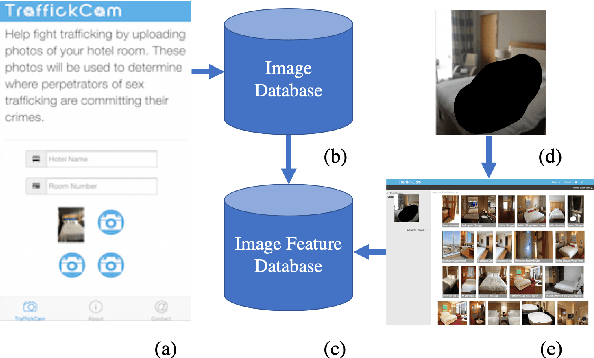
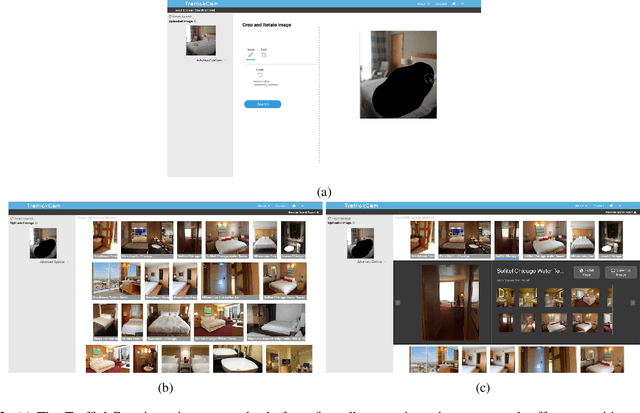

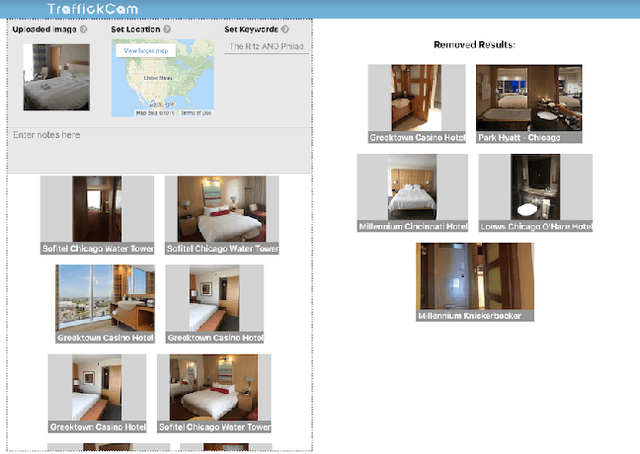
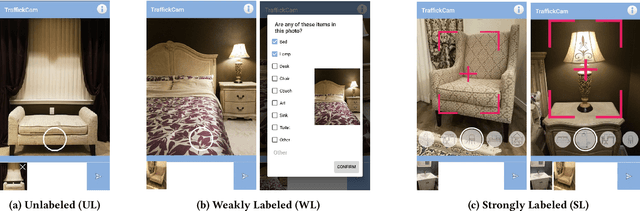
Investigations of sex trafficking sometimes have access to photographs of victims in hotel rooms. These images directly link victims to places, which can help verify where victims have been trafficked or where traffickers might operate in the future. Current machine learning approaches give promising results in image search to find the matching hotel. This paper explores approaches to make this end-to-end system better support government and law enforcement requirements, including improved performance, visualization approaches that explain what parts of the image led to a match, and infrastructure to support exporting the results of a query.
Hotels-50K: A Global Hotel Recognition Dataset
Jan 26, 2019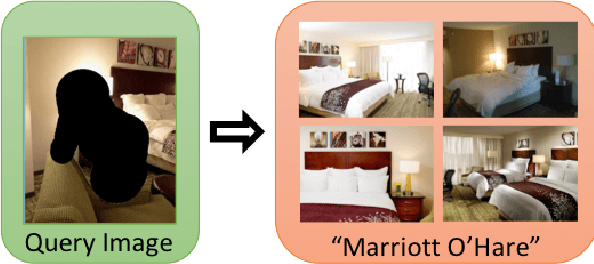


Recognizing a hotel from an image of a hotel room is important for human trafficking investigations. Images directly link victims to places and can help verify where victims have been trafficked, and where their traffickers might move them or others in the future. Recognizing the hotel from images is challenging because of low image quality, uncommon camera perspectives, large occlusions (often the victim), and the similarity of objects (e.g., furniture, art, bedding) across different hotel rooms. To support efforts towards this hotel recognition task, we have curated a dataset of over 1 million annotated hotel room images from 50,000 hotels. These images include professionally captured photographs from travel websites and crowd-sourced images from a mobile application, which are more similar to the types of images analyzed in real-world investigations. We present a baseline approach based on a standard network architecture and a collection of data-augmentation approaches tuned to this problem domain.
Visualizing Deep Similarity Networks
Jan 02, 2019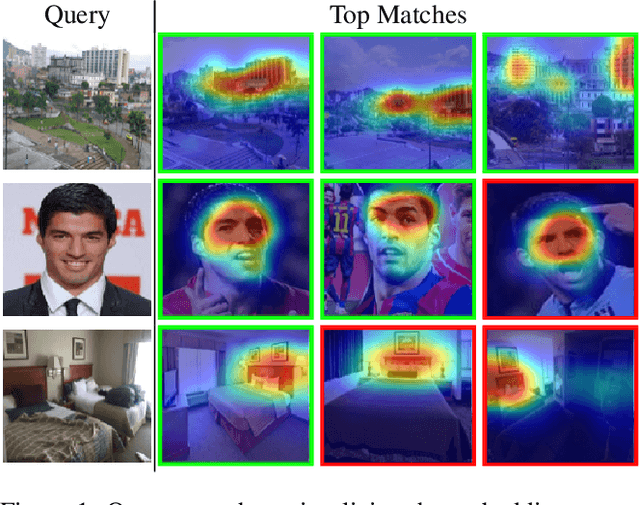
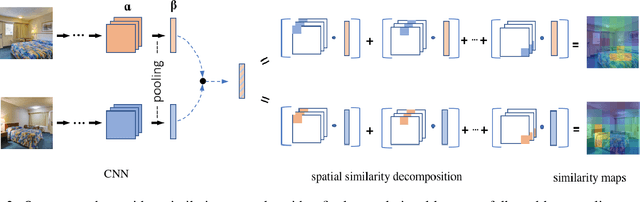
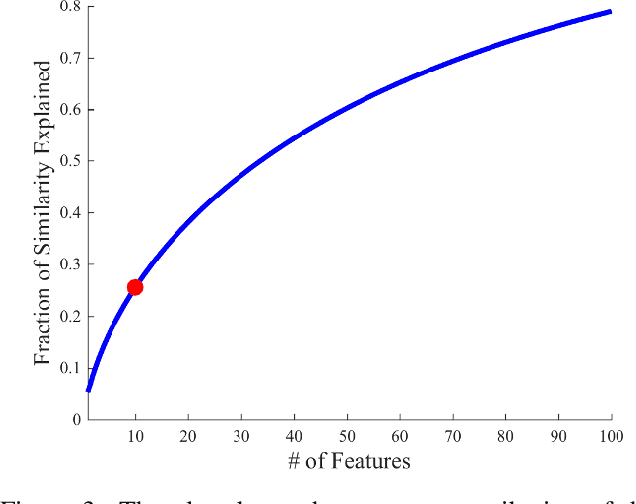

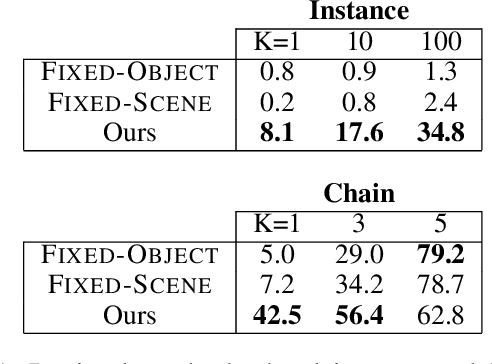
For convolutional neural network models that optimize an image embedding, we propose a method to highlight the regions of images that contribute most to pairwise similarity. This work is a corollary to the visualization tools developed for classification networks, but applicable to the problem domains better suited to similarity learning. The visualization shows how similarity networks that are fine-tuned learn to focus on different features. We also generalize our approach to embedding networks that use different pooling strategies and provide a simple mechanism to support image similarity searches on objects or sub-regions in the query image.
Deep Randomized Ensembles for Metric Learning
Sep 04, 2018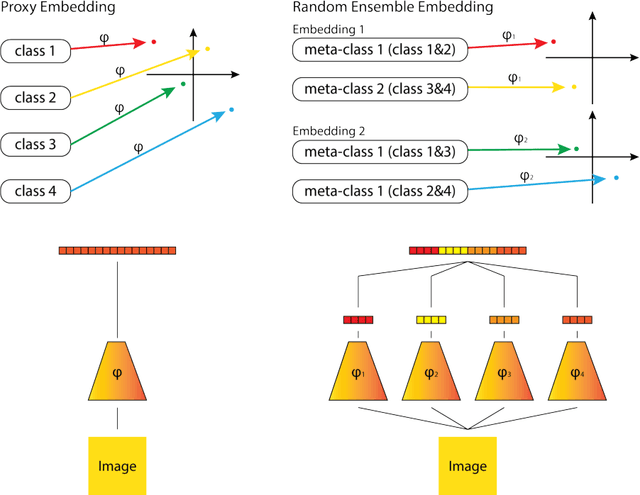


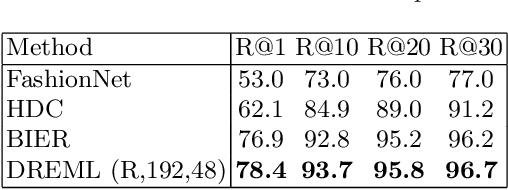
Learning embedding functions, which map semantically related inputs to nearby locations in a feature space supports a variety of classification and information retrieval tasks. In this work, we propose a novel, generalizable and fast method to define a family of embedding functions that can be used as an ensemble to give improved results. Each embedding function is learned by randomly bagging the training labels into small subsets. We show experimentally that these embedding ensembles create effective embedding functions. The ensemble output defines a metric space that improves state of the art performance for image retrieval on CUB-200-2011, Cars-196, In-Shop Clothes Retrieval and VehicleID.
Understanding and Mapping Natural Beauty
Aug 09, 2017

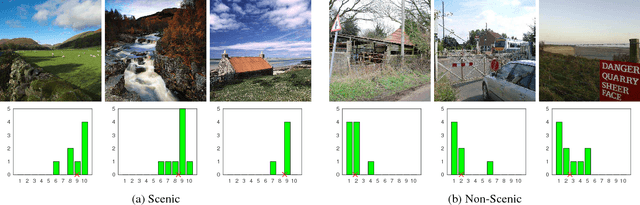

While natural beauty is often considered a subjective property of images, in this paper, we take an objective approach and provide methods for quantifying and predicting the scenicness of an image. Using a dataset containing hundreds of thousands of outdoor images captured throughout Great Britain with crowdsourced ratings of natural beauty, we propose an approach to predict scenicness which explicitly accounts for the variance of human ratings. We demonstrate that quantitative measures of scenicness can benefit semantic image understanding, content-aware image processing, and a novel application of cross-view mapping, where the sparsity of ground-level images can be addressed by incorporating unlabeled overhead images in the training and prediction steps. For each application, our methods for scenicness prediction result in quantitative and qualitative improvements over baseline approaches.
Wide-Area Image Geolocalization with Aerial Reference Imagery
Oct 13, 2015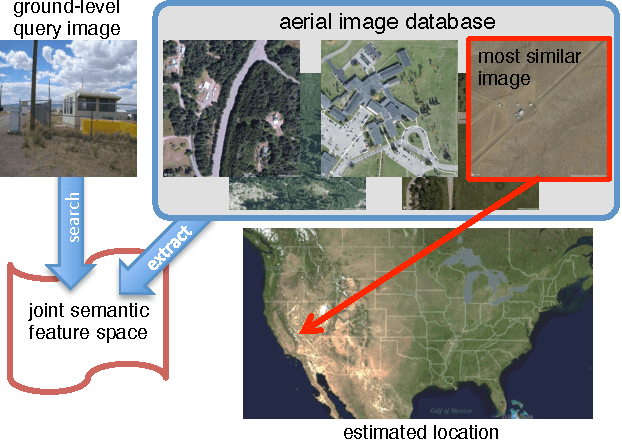


We propose to use deep convolutional neural networks to address the problem of cross-view image geolocalization, in which the geolocation of a ground-level query image is estimated by matching to georeferenced aerial images. We use state-of-the-art feature representations for ground-level images and introduce a cross-view training approach for learning a joint semantic feature representation for aerial images. We also propose a network architecture that fuses features extracted from aerial images at multiple spatial scales. To support training these networks, we introduce a massive database that contains pairs of aerial and ground-level images from across the United States. Our methods significantly out-perform the state of the art on two benchmark datasets. We also show, qualitatively, that the proposed feature representations are discriminative at both local and continental spatial scales.