 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMA: Efficient Model Adaptation for Learning-based Systems
May 13, 2026Machine learning (ML) is increasingly applied to optimize system performance in tasks such as resource management and network simulation. Unlike traditional ML tasks (e.g., image classification), networked systems often operate in heterogeneous, long-running, and dynamic environment states, where input conditions (e.g., network loads) and operational objectives can shift over time and across settings. Existing learning-based systems offer little support for adaptation, resulting in costly model training, extensive data collection, degraded system performance, and slow responsiveness. This paper presents EMA, the first model adaptation system supporting learning-based systems to adapt to evolving environments with minimal operational overhead. EMA takes a system-driven, data-centric approach that accommodates diverse system and model designs while addressing two key deployment challenges. First, it reduces expensive model training by introducing state transformers that align the input state of a new environment with previously similar states, allowing models to warm-start adaptation. Second, it addresses the often-overlooked yet costly process of data labeling--collecting ground truth for exploring and training on various system decisions--by prioritizing labeling high-utility data while balancing the tradeoff between training and labeling cost. Evaluations on eight representative learning-based systems show that EMA reduces adaptation costs (e.g., GPU training time) by 14.9-42.4% while improving system performance (e.g., network throughput) by 6.9-31.3%.
Optimal Estimation in Orthogonally Invariant Generalized Linear Models: Spectral Initialization and Approximate Message Passing
Feb 09, 2026We consider the problem of parameter estimation from a generalized linear model with a random design matrix that is orthogonally invariant in law. Such a model allows the design have an arbitrary distribution of singular values and only assumes that its singular vectors are generic. It is a vast generalization of the i.i.d. Gaussian design typically considered in the theoretical literature, and is motivated by the fact that real data often have a complex correlation structure so that methods relying on i.i.d. assumptions can be highly suboptimal. Building on the paradigm of spectrally-initialized iterative optimization, this paper proposes optimal spectral estimators and combines them with an approximate message passing (AMP) algorithm, establishing rigorous performance guarantees for these two algorithmic steps. Both the spectral initialization and the subsequent AMP meet existing conjectures on the fundamental limits to estimation -- the former on the optimal sample complexity for efficient weak recovery, and the latter on the optimal errors. Numerical experiments suggest the effectiveness of our methods and accuracy of our theory beyond orthogonally invariant data.
ViCA: Efficient Multimodal LLMs with Vision-Only Cross-Attention
Feb 07, 2026Modern multimodal large language models (MLLMs) adopt a unified self-attention design that processes visual and textual tokens at every Transformer layer, incurring substantial computational overhead. In this work, we revisit the necessity of such dense visual processing and show that projected visual embeddings are already well-aligned with the language space, while effective vision-language interaction occurs in only a small subset of layers. Based on these insights, we propose ViCA (Vision-only Cross-Attention), a minimal MLLM architecture in which visual tokens bypass all self-attention and feed-forward layers, interacting with text solely through sparse cross-attention at selected layers. Extensive evaluations across three MLLM backbones, nine multimodal benchmarks, and 26 pruning-based baselines show that ViCA preserves 98% of baseline accuracy while reducing visual-side computation to 4%, consistently achieving superior performance-efficiency trade-offs. Moreover, ViCA provides a regular, hardware-friendly inference pipeline that yields over 3.5x speedup in single-batch inference and over 10x speedup in multi-batch inference, reducing visual grounding to near-zero overhead compared with text-only LLMs. It is also orthogonal to token pruning methods and can be seamlessly combined for further efficiency gains. Our code is available at https://github.com/EIT-NLP/ViCA.
UCCL-EP: Portable Expert-Parallel Communication
Dec 22, 2025Mixture-of-Experts (MoE) workloads rely on expert parallelism (EP) to achieve high GPU efficiency. State-of-the-art EP communication systems such as DeepEP demonstrate strong performance but exhibit poor portability across heterogeneous GPU and NIC platforms. The poor portability is rooted in architecture: GPU-initiated token-level RDMA communication requires tight vertical integration between GPUs and NICs, e.g., GPU writes to NIC driver/MMIO interfaces. We present UCCL-EP, a portable EP communication system that delivers DeepEP-level performance across heterogeneous GPU and NIC hardware. UCCL-EP replaces GPU-initiated RDMA with a high-throughput GPU-CPU control channel: compact token-routing commands are transferred to multithreaded CPU proxies, which then issue GPUDirect RDMA operations on behalf of GPUs. UCCL-EP further emulates various ordering semantics required by specialized EP communication modes using RDMA immediate data, enabling correctness on NICs that lack such ordering, e.g., AWS EFA. We implement UCCL-EP on NVIDIA and AMD GPUs with EFA and Broadcom NICs. On EFA, it outperforms the best existing EP solution by up to $2.1\times$ for dispatch and combine throughput. On NVIDIA-only platform, UCCL-EP achieves comparable performance to the original DeepEP. UCCL-EP also improves token throughput on SGLang by up to 40% on the NVIDIA+EFA platform, and improves DeepSeek-V3 training throughput over the AMD Primus/Megatron-LM framework by up to 45% on a 16-node AMD+Broadcom platform.
Nonconvex Decentralized Stochastic Bilevel Optimization under Heavy-Tailed Noises
Sep 19, 2025Existing decentralized stochastic optimization methods assume the lower-level loss function is strongly convex and the stochastic gradient noise has finite variance. These strong assumptions typically are not satisfied in real-world machine learning models. To address these limitations, we develop a novel decentralized stochastic bilevel optimization algorithm for the nonconvex bilevel optimization problem under heavy-tailed noises. Specifically, we develop a normalized stochastic variance-reduced bilevel gradient descent algorithm, which does not rely on any clipping operation. Moreover, we establish its convergence rate by innovatively bounding interdependent gradient sequences under heavy-tailed noises for nonconvex decentralized bilevel optimization problems. As far as we know, this is the first decentralized bilevel optimization algorithm with rigorous theoretical guarantees under heavy-tailed noises. The extensive experimental results confirm the effectiveness of our algorithm in handling heavy-tailed noises.
Research on Cloud Platform Network Traffic Monitoring and Anomaly Detection System based on Large Language Models
Apr 22, 2025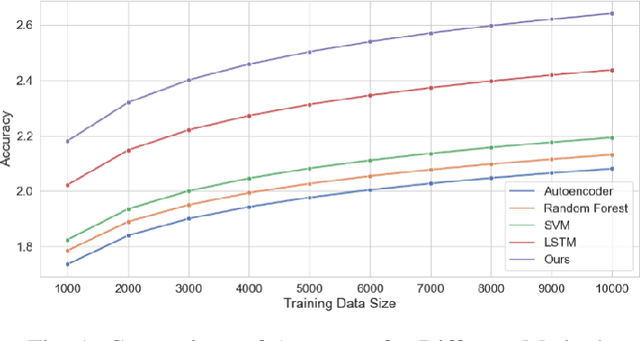
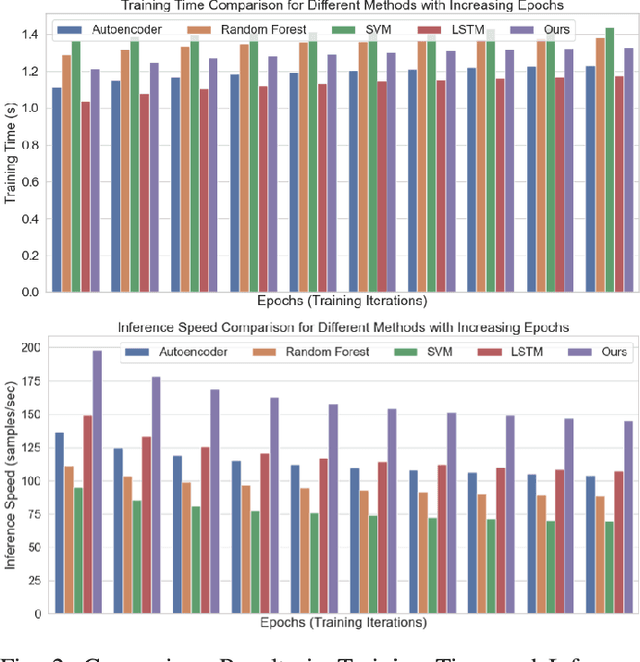
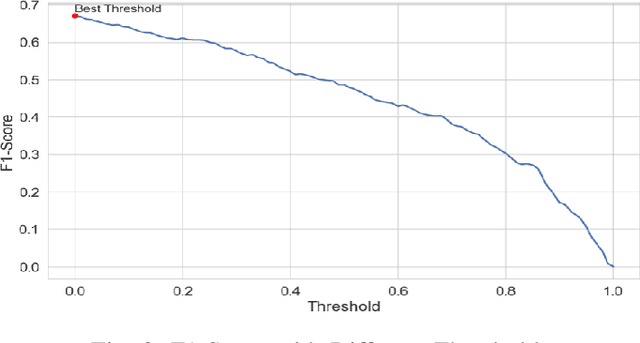

The rapidly evolving cloud platforms and the escalating complexity of network traffic demand proper network traffic monitoring and anomaly detection to ensure network security and performance. This paper introduces a large language model (LLM)-based network traffic monitoring and anomaly detection system. In addition to existing models such as autoencoders and decision trees, we harness the power of large language models for processing sequence data from network traffic, which allows us a better capture of underlying complex patterns, as well as slight fluctuations in the dataset. We show for a given detection task, the need for a hybrid model that incorporates the attention mechanism of the transformer architecture into a supervised learning framework in order to achieve better accuracy. A pre-trained large language model analyzes and predicts the probable network traffic, and an anomaly detection layer that considers temporality and context is added. Moreover, we present a novel transfer learning-based methodology to enhance the model's effectiveness to quickly adapt to unknown network structures and adversarial conditions without requiring extensive labeled datasets. Actual results show that the designed model outperforms traditional methods in detection accuracy and computational efficiency, effectively identify various network anomalies such as zero-day attacks and traffic congestion pattern, and significantly reduce the false positive rate.
Research on Large Language Model Cross-Cloud Privacy Protection and Collaborative Training based on Federated Learning
Mar 15, 2025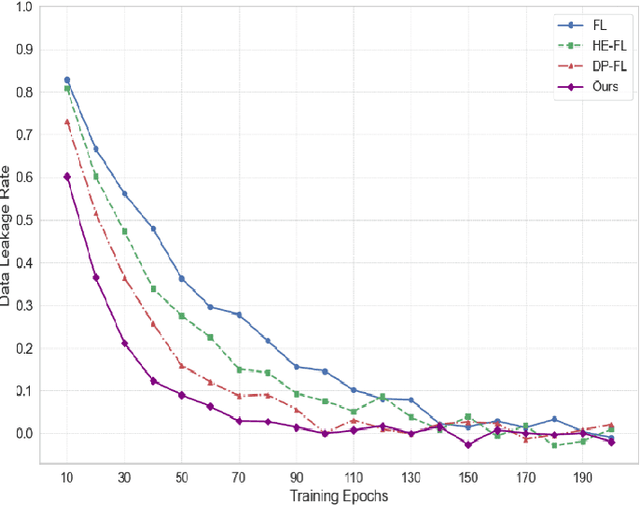
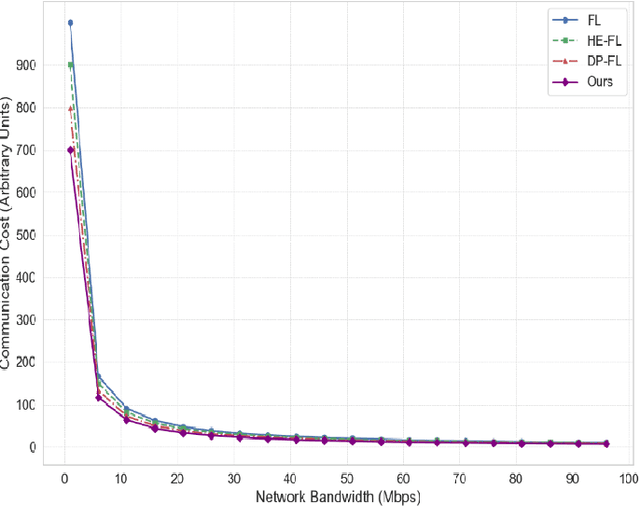
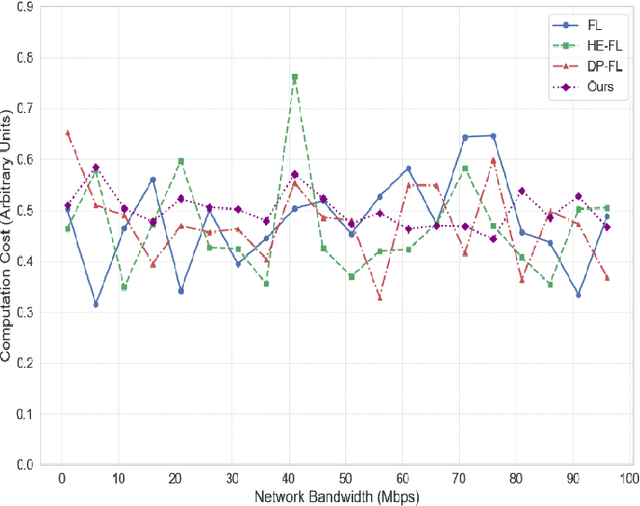
The fast development of large language models (LLMs) and popularization of cloud computing have led to increasing concerns on privacy safeguarding and data security of cross-cloud model deployment and training as the key challenges. We present a new framework for addressing these issues along with enabling privacy preserving collaboration on training between distributed clouds based on federated learning. Our mechanism encompasses cutting-edge cryptographic primitives, dynamic model aggregation techniques, and cross-cloud data harmonization solutions to enhance security, efficiency, and scalability to the traditional federated learning paradigm. Furthermore, we proposed a hybrid aggregation scheme to mitigate the threat of Data Leakage and to optimize the aggregation of model updates, thus achieving substantial enhancement on the model effectiveness and stability. Experimental results demonstrate that the training efficiency, privacy protection, and model accuracy of the proposed model compare favorably to those of the traditional federated learning method.
Adaptive Fault Tolerance Mechanisms of Large Language Models in Cloud Computing Environments
Mar 15, 2025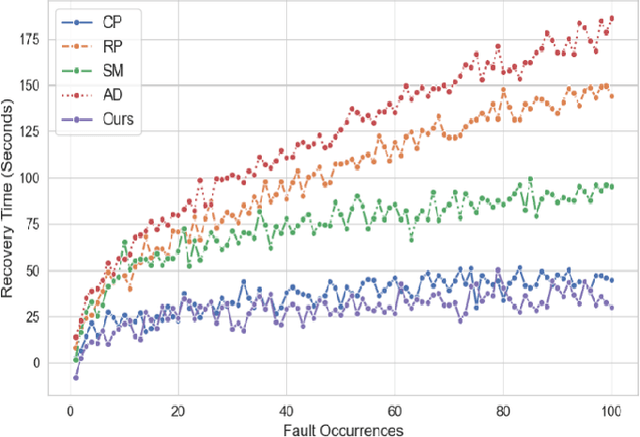
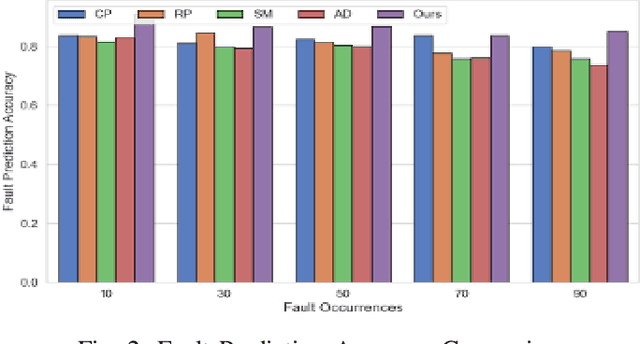
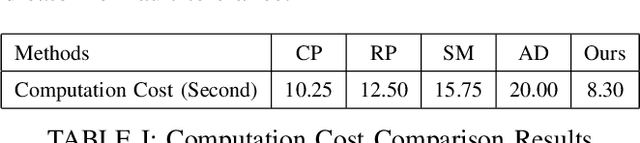
With the rapid evolution of Large Language Models (LLMs) and their large-scale experimentation in cloud-computing spaces, the challenge of guaranteeing their security and efficiency in a failure scenario has become a main issue. To ensure the reliability and availability of large-scale language models in cloud computing scenarios, such as frequent resource failures, network problems, and computational overheads, this study proposes a novel adaptive fault tolerance mechanism. It builds upon known fault-tolerant mechanisms, such as checkpointing, redundancy, and state transposition, introducing dynamic resource allocation and prediction of failure based on real-time performance metrics. The hybrid model integrates data driven deep learning-based anomaly detection technique underlining the contribution of cloud orchestration middleware for predictive prevention of system failures. Additionally, the model integrates adaptive checkpointing and recovery strategies that dynamically adapt according to load and system state to minimize the influence on the performance of the model and minimize downtime. The experimental results demonstrate that the designed model considerably enhances the fault tolerance in large-scale cloud surroundings, and decreases the system downtime by $\mathbf{30\%}$, and has a better modeling availability than the classical fault tolerance mechanism.
Spectral Estimators for Multi-Index Models: Precise Asymptotics and Optimal Weak Recovery
Feb 03, 2025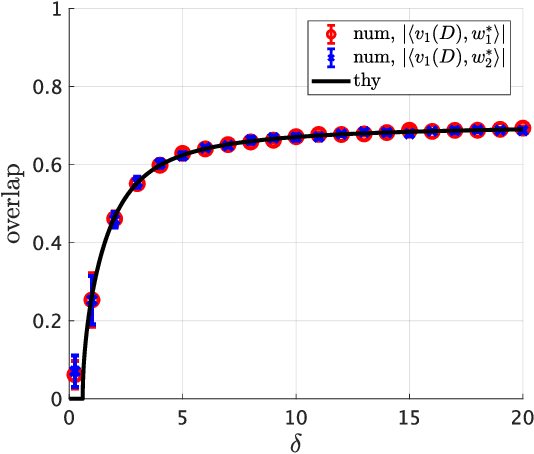
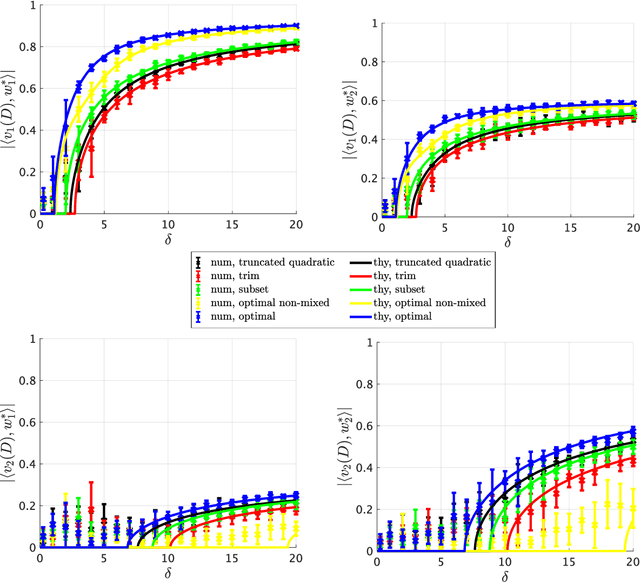
Multi-index models provide a popular framework to investigate the learnability of functions with low-dimensional structure and, also due to their connections with neural networks, they have been object of recent intensive study. In this paper, we focus on recovering the subspace spanned by the signals via spectral estimators -- a family of methods that are routinely used in practice, often as a warm-start for iterative algorithms. Our main technical contribution is a precise asymptotic characterization of the performance of spectral methods, when sample size and input dimension grow proportionally and the dimension $p$ of the space to recover is fixed. Specifically, we locate the top-$p$ eigenvalues of the spectral matrix and establish the overlaps between the corresponding eigenvectors (which give the spectral estimators) and a basis of the signal subspace. Our analysis unveils a phase transition phenomenon in which, as the sample complexity grows, eigenvalues escape from the bulk of the spectrum and, when that happens, eigenvectors recover directions of the desired subspace. The precise characterization we put forward enables the optimization of the data preprocessing, thus allowing to identify the spectral estimator that requires the minimal sample size for weak recovery.
Style Transfer: From Stitching to Neural Networks
Sep 01, 2024



This article compares two style transfer methods in image processing: the traditional method, which synthesizes new images by stitching together small patches from existing images, and a modern machine learning-based approach that uses a segmentation network to isolate foreground objects and apply style transfer solely to the background. The traditional method excels in creating artistic abstractions but can struggle with seamlessness, whereas the machine learning method preserves the integrity of foreground elements while enhancing the background, offering improved aesthetic quality and computational efficiency. Our study indicates that machine learning-based methods are more suited for real-world applications where detail preservation in foreground elements is essential.