 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Intelligent Fault Self-Healing Mechanism for Cloud AI Systems via Integration of Large Language Models and Deep Reinforcement Learning
Jun 09, 2025As the scale and complexity of cloud-based AI systems continue to increase, the detection and adaptive recovery of system faults have become the core challenges to ensure service reliability and continuity. In this paper, we propose an Intelligent Fault Self-Healing Mechanism (IFSHM) that integrates Large Language Model (LLM) and Deep Reinforcement Learning (DRL), aiming to realize a fault recovery framework with semantic understanding and policy optimization capabilities in cloud AI systems. On the basis of the traditional DRL-based control model, the proposed method constructs a two-stage hybrid architecture: (1) an LLM-driven fault semantic interpretation module, which can dynamically extract deep contextual semantics from multi-source logs and system indicators to accurately identify potential fault modes; (2) DRL recovery strategy optimizer, based on reinforcement learning, learns the dynamic matching of fault types and response behaviors in the cloud environment. The innovation of this method lies in the introduction of LLM for environment modeling and action space abstraction, which greatly improves the exploration efficiency and generalization ability of reinforcement learning. At the same time, a memory-guided meta-controller is introduced, combined with reinforcement learning playback and LLM prompt fine-tuning strategy, to achieve continuous adaptation to new failure modes and avoid catastrophic forgetting. Experimental results on the cloud fault injection platform show that compared with the existing DRL and rule methods, the IFSHM framework shortens the system recovery time by 37% with unknown fault scenarios.
Anomaly Detection and Early Warning Mechanism for Intelligent Monitoring Systems in Multi-Cloud Environments Based on LLM
Jun 09, 2025With the rapid development of multi-cloud environments, it is increasingly important to ensure the security and reliability of intelligent monitoring systems. In this paper, we propose an anomaly detection and early warning mechanism for intelligent monitoring system in multi-cloud environment based on Large-Scale Language Model (LLM). On the basis of the existing monitoring framework, the proposed model innovatively introduces a multi-level feature extraction method, which combines the natural language processing ability of LLM with traditional machine learning methods to enhance the accuracy of anomaly detection and improve the real-time response efficiency. By introducing the contextual understanding capabilities of LLMs, the model dynamically adapts to different cloud service providers and environments, so as to more effectively detect abnormal patterns and predict potential failures. Experimental results show that the proposed model is significantly better than the traditional anomaly detection system in terms of detection accuracy and latency, and significantly improves the resilience and active management ability of cloud infrastructure.
Research on Cloud Platform Network Traffic Monitoring and Anomaly Detection System based on Large Language Models
Apr 22, 2025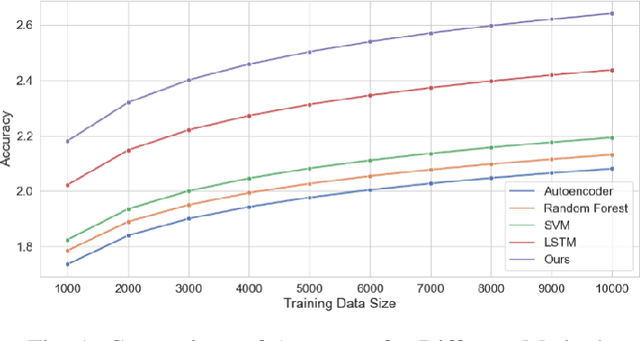
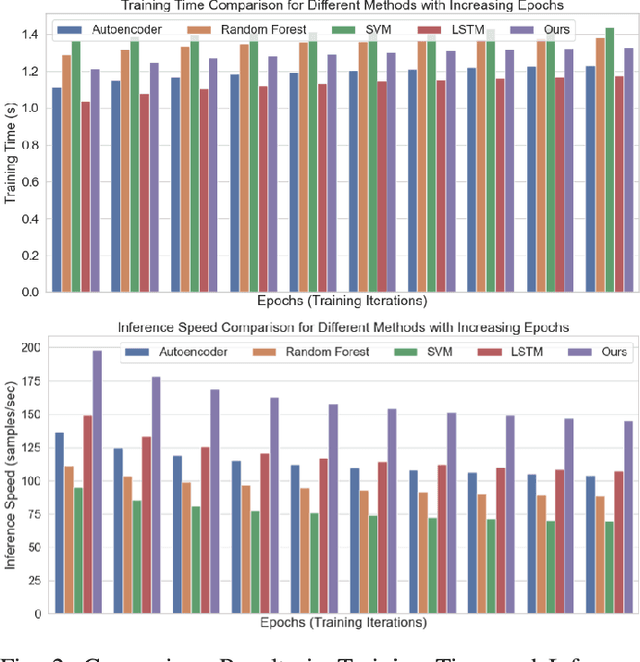
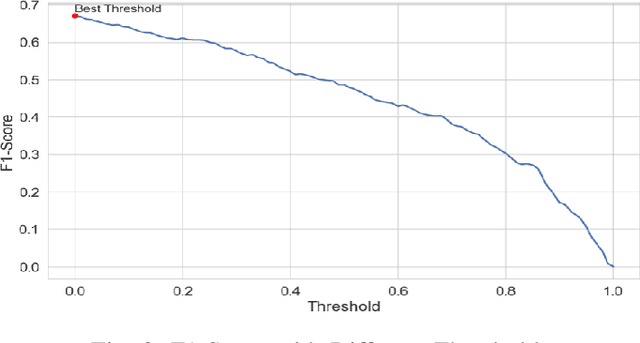

The rapidly evolving cloud platforms and the escalating complexity of network traffic demand proper network traffic monitoring and anomaly detection to ensure network security and performance. This paper introduces a large language model (LLM)-based network traffic monitoring and anomaly detection system. In addition to existing models such as autoencoders and decision trees, we harness the power of large language models for processing sequence data from network traffic, which allows us a better capture of underlying complex patterns, as well as slight fluctuations in the dataset. We show for a given detection task, the need for a hybrid model that incorporates the attention mechanism of the transformer architecture into a supervised learning framework in order to achieve better accuracy. A pre-trained large language model analyzes and predicts the probable network traffic, and an anomaly detection layer that considers temporality and context is added. Moreover, we present a novel transfer learning-based methodology to enhance the model's effectiveness to quickly adapt to unknown network structures and adversarial conditions without requiring extensive labeled datasets. Actual results show that the designed model outperforms traditional methods in detection accuracy and computational efficiency, effectively identify various network anomalies such as zero-day attacks and traffic congestion pattern, and significantly reduce the false positive rate.
Adaptive Fault Tolerance Mechanisms of Large Language Models in Cloud Computing Environments
Mar 15, 2025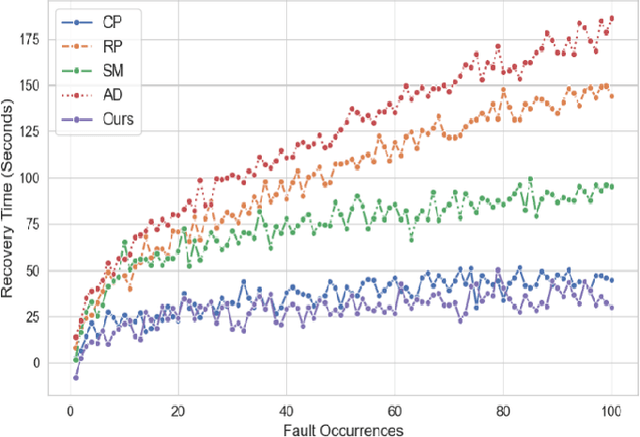
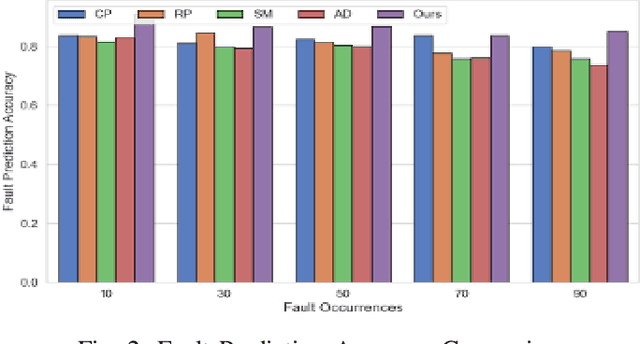
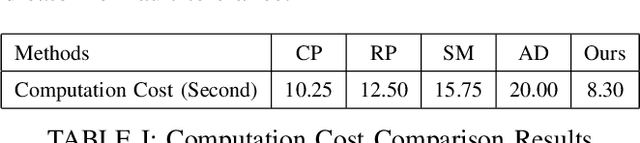
With the rapid evolution of Large Language Models (LLMs) and their large-scale experimentation in cloud-computing spaces, the challenge of guaranteeing their security and efficiency in a failure scenario has become a main issue. To ensure the reliability and availability of large-scale language models in cloud computing scenarios, such as frequent resource failures, network problems, and computational overheads, this study proposes a novel adaptive fault tolerance mechanism. It builds upon known fault-tolerant mechanisms, such as checkpointing, redundancy, and state transposition, introducing dynamic resource allocation and prediction of failure based on real-time performance metrics. The hybrid model integrates data driven deep learning-based anomaly detection technique underlining the contribution of cloud orchestration middleware for predictive prevention of system failures. Additionally, the model integrates adaptive checkpointing and recovery strategies that dynamically adapt according to load and system state to minimize the influence on the performance of the model and minimize downtime. The experimental results demonstrate that the designed model considerably enhances the fault tolerance in large-scale cloud surroundings, and decreases the system downtime by $\mathbf{30\%}$, and has a better modeling availability than the classical fault tolerance mechanism.
Research on Large Language Model Cross-Cloud Privacy Protection and Collaborative Training based on Federated Learning
Mar 15, 2025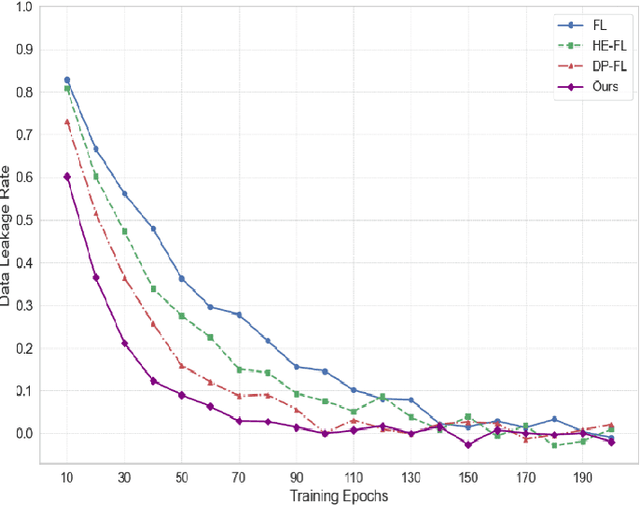
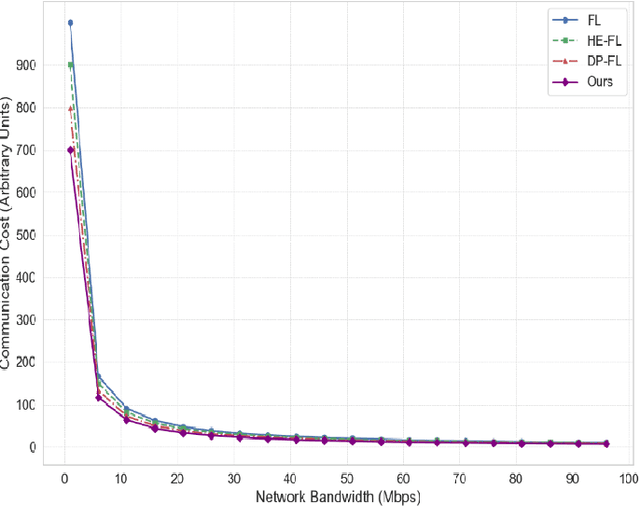
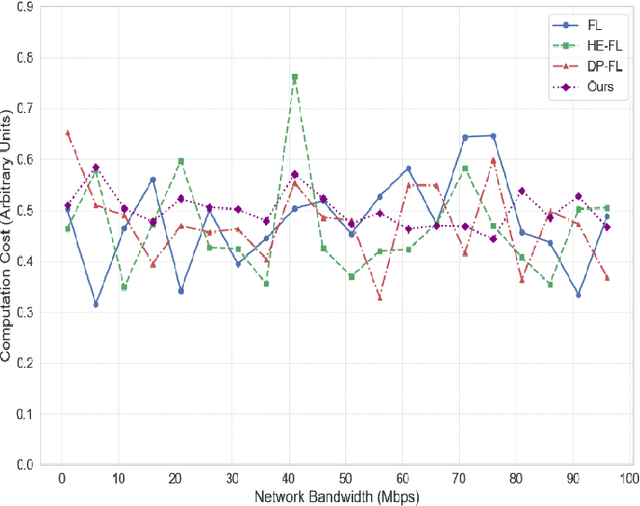
The fast development of large language models (LLMs) and popularization of cloud computing have led to increasing concerns on privacy safeguarding and data security of cross-cloud model deployment and training as the key challenges. We present a new framework for addressing these issues along with enabling privacy preserving collaboration on training between distributed clouds based on federated learning. Our mechanism encompasses cutting-edge cryptographic primitives, dynamic model aggregation techniques, and cross-cloud data harmonization solutions to enhance security, efficiency, and scalability to the traditional federated learning paradigm. Furthermore, we proposed a hybrid aggregation scheme to mitigate the threat of Data Leakage and to optimize the aggregation of model updates, thus achieving substantial enhancement on the model effectiveness and stability. Experimental results demonstrate that the training efficiency, privacy protection, and model accuracy of the proposed model compare favorably to those of the traditional federated learning method.
HADES: Hardware Accelerated Decoding for Efficient Speculation in Large Language Models
Dec 27, 2024Large Language Models (LLMs) have revolutionized natural language processing by understanding and generating human-like text. However, the increasing demand for more sophisticated LLMs presents significant computational challenges due to their scale and complexity. This paper introduces Hardware Accelerated Decoding (HADES), a novel approach to enhance the performance and energy efficiency of LLMs. We address the design of an LLM accelerator with hardware-level speculative decoding support, a concept not previously explored in existing literature. Our work demonstrates how speculative decoding can significantly improve the efficiency of LLM operations, paving the way for more advanced and practical applications of these models.
Style Transfer: From Stitching to Neural Networks
Sep 01, 2024



This article compares two style transfer methods in image processing: the traditional method, which synthesizes new images by stitching together small patches from existing images, and a modern machine learning-based approach that uses a segmentation network to isolate foreground objects and apply style transfer solely to the background. The traditional method excels in creating artistic abstractions but can struggle with seamlessness, whereas the machine learning method preserves the integrity of foreground elements while enhancing the background, offering improved aesthetic quality and computational efficiency. Our study indicates that machine learning-based methods are more suited for real-world applications where detail preservation in foreground elements is essential.
A Comparative Study on Enhancing Prediction in Social Network Advertisement through Data Augmentation
Apr 28, 2024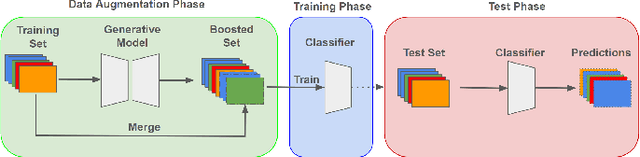
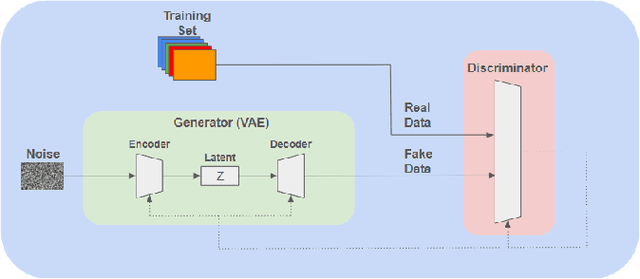
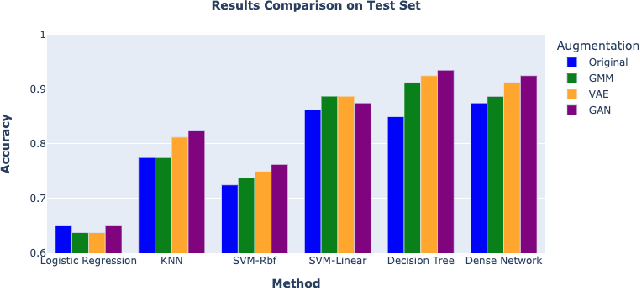
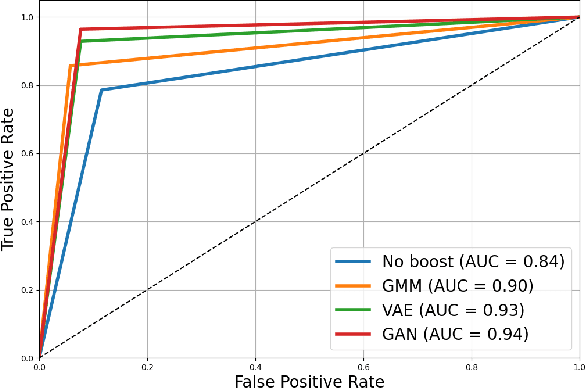
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.