 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Scaling Universality: If Exponents Are Fixed, Time to Understand Coefficients
Jun 23, 2026Neural scaling laws describe how pre-training loss decays as power laws with training time, model size, and compute. This position paper argues that the exponents of these power laws are fixed by generic mechanisms: a one-third time scaling due to the strong nonlinearity of Softmax, an inverse width scaling due to representational superposition, and an inverse depth scaling due to ensemble averaging of Transformer layers. These mechanisms are robust to a wide range of data structures and architectural details, placing current large language models in a universality class with fixed exponents. The coefficients, however, are expected to be sensitive to data and architecture details, and directly determine practical quantities such as the optimal model shape and the compute-optimal frontier. We therefore argue that understanding the coefficients is the key to near-term performance improvements, and that a closer examination of the current universality class may reveal pathways to better universality classes.
Pause or Fabricate? Training Language Models for Grounded Reasoning
Apr 21, 2026Large language models have achieved remarkable progress on complex reasoning tasks. However, they often implicitly fabricate information when inputs are incomplete, producing confident but unreliable conclusions -- a failure mode we term ungrounded reasoning. We argue that this issue arises not from insufficient reasoning capability, but from the lack of inferential boundary awareness -- the ability to recognize when the necessary premises for valid inference are missing. To address this issue, we propose Grounded Reasoning via Interactive Reinforcement Learning (GRIL), a multi-turn reinforcement learning framework for grounded reasoning under incomplete information. GRIL decomposes the reasoning process into two stages: clarify and pause, which identifies whether the available information is sufficient, and grounded reasoning, which performs task solving once the necessary premises are established. We design stage-specific rewards to penalize hallucinations, enabling models to detect gaps, stop proactively, and resume reasoning after clarification. Experiments on GSM8K-Insufficient and MetaMATH-Insufficient show that GRIL significantly improves premise detection (up to 45%), leading to a 30% increase in task success while reducing average response length by over 20%. Additional analyses confirm robustness to noisy user responses and generalization to out-of-distribution tasks.
KnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
Apr 09, 2026Personalized mobile agents that infer user preferences and calibrate proactive assistance hold great promise as everyday digital assistants, yet existing benchmarks fail to capture what this requires. Prior work evaluates preference recovery from static histories or intent prediction from fixed contexts. Neither tests whether an agent can elicit missing preferences through interaction, nor whether it can decide when to intervene, seek consent, or remain silent in a live GUI environment. We introduce KnowU-Bench, an online benchmark for personalized mobile agents built on a reproducible Android emulation environment, covering 42 general GUI tasks, 86 personalized tasks, and 64 proactive tasks. Unlike prior work that treats user preferences as static context, KnowU-Bench hides the user profile from the agent and exposes only behavioral logs, forcing genuine preference inference rather than context lookup. To support multi-turn preference elicitation, it instantiates an LLM-driven user simulator grounded in structured profiles, enabling realistic clarification dialogues and proactive consent handling. Beyond personalization, KnowU-Bench provides comprehensive evaluation of the complete proactive decision chain, including grounded GUI execution, consent negotiation, and post-rejection restraint, evaluated through a hybrid protocol combining rule-based verification with LLM-as-a-Judge scoring. Our experiments reveal a striking degradation: agents that excel at explicit task execution fall below 50% under vague instructions requiring user preference inference or intervention calibration, even for frontier models like Claude Sonnet 4.6. The core bottlenecks are not GUI navigation but preference acquisition and intervention calibration, exposing a fundamental gap between competent interface operation and trustworthy personal assistance.
Search, Do not Guess: Teaching Small Language Models to Be Effective Search Agents
Apr 06, 2026Agents equipped with search tools have emerged as effective solutions for knowledge-intensive tasks. While Large Language Models (LLMs) exhibit strong reasoning capabilities, their high computational cost limits practical deployment for search agents. Consequently, recent work has focused on distilling agentic behaviors from LLMs into Small Language Models (SLMs). Through comprehensive evaluation on complex multi-hop reasoning tasks, we find that despite possessing less parametric knowledge, SLMs invoke search tools less frequently and are more prone to hallucinations. To address this issue, we propose \policy, a lightweight fine-tuning approach that explicitly trains SLMs to reliably retrieve and generate answers grounded in retrieved evidence. Compared to agent distillation from LLMs, our approach improves performance by 17.3 scores on Bamboogle and 15.3 scores on HotpotQA, achieving LLM-level results across benchmarks. Our further analysis reveals that adaptive search strategies in SLMs often degrade performance, highlighting the necessity of consistent search behavior for reliable reasoning.
Exploring Physical Intelligence Emergence via Omni-Modal Architecture and Physical Data Engine
Feb 05, 2026Physical understanding remains brittle in omni-modal models because key physical attributes are visually ambiguous and sparsely represented in web-scale data. We present OmniFysics, a compact omni-modal model that unifies understanding across images, audio, video, and text, with integrated speech and image generation. To inject explicit physical knowledge, we build a physical data engine with two components. FysicsAny produces physics-grounded instruction--image supervision by mapping salient objects to verified physical attributes through hierarchical retrieval over a curated prototype database, followed by physics-law--constrained verification and caption rewriting. FysicsOmniCap distills web videos via audio--visual consistency filtering to generate high-fidelity video--instruction pairs emphasizing cross-modal physical cues. We train OmniFysics with staged multimodal alignment and instruction tuning, adopt latent-space flow matching for text-to-image generation, and use an intent router to activate generation only when needed. Experiments show competitive performance on standard multimodal benchmarks and improved results on physics-oriented evaluations.
Inverse Depth Scaling From Most Layers Being Similar
Feb 05, 2026Neural scaling laws relate loss to model size in large language models (LLMs), yet depth and width may contribute to performance differently, requiring more detailed studies. Here, we quantify how depth affects loss via analysis of LLMs and toy residual networks. We find loss scales inversely proportional to depth in LLMs, probably due to functionally similar layers reducing error through ensemble averaging rather than compositional learning or discretizing smooth dynamics. This regime is inefficient yet robust and may arise from the architectural bias of residual networks and target functions incompatible with smooth dynamics. The findings suggest that improving LLM efficiency may require architectural innovations to encourage compositional use of depth.
Universal One-third Time Scaling in Learning Peaked Distributions
Feb 03, 2026Training large language models (LLMs) is computationally expensive, partly because the loss exhibits slow power-law convergence whose origin remains debatable. Through systematic analysis of toy models and empirical evaluation of LLMs, we show that this behavior can arise intrinsically from the use of softmax and cross-entropy. When learning peaked probability distributions, e.g., next-token distributions, these components yield power-law vanishing losses and gradients, creating a fundamental optimization bottleneck. This ultimately leads to power-law time scaling of the loss with a universal exponent of $1/3$. Our results provide a mechanistic explanation for observed neural scaling and suggest new directions for improving LLM training efficiency.
Superposition unifies power-law training dynamics
Feb 01, 2026We investigate the role of feature superposition in the emergence of power-law training dynamics using a teacher-student framework. We first derive an analytic theory for training without superposition, establishing that the power-law training exponent depends on both the input data statistics and channel importance. Remarkably, we discover that a superposition bottleneck induces a transition to a universal power-law exponent of $\sim 1$, independent of data and channel statistics. This one over time training with superposition represents an up to tenfold acceleration compared to the purely sequential learning that takes place in the absence of superposition. Our finding that superposition leads to rapid training with a data-independent power law exponent may have important implications for a wide range of neural networks that employ superposition, including production-scale large language models.
The Blessing of Dimensionality in LLM Fine-tuning: A Variance-Curvature Perspective
Jan 30, 2026Weight-perturbation evolution strategies (ES) can fine-tune billion-parameter language models with surprisingly small populations (e.g., $N\!\approx\!30$), contradicting classical zeroth-order curse-of-dimensionality intuition. We also observe a second seemingly separate phenomenon: under fixed hyperparameters, the stochastic fine-tuning reward often rises, peaks, and then degrades in both ES and GRPO. We argue that both effects reflect a shared geometric property of fine-tuning landscapes: they are low-dimensional in curvature. A small set of high-curvature dimensions dominates improvement, producing (i) heterogeneous time scales that yield rise-then-decay under fixed stochasticity, as captured by a minimal quadratic stochastic-ascent model, and (ii) degenerate improving updates, where many random perturbations share similar components along these directions. Using ES as a geometric probe on fine-tuning reward landscapes of GSM8K, ARC-C, and WinoGrande across Qwen2.5-Instruct models (0.5B--7B), we show that reward-improving perturbations remain empirically accessible with small populations across scales. Together, these results reconcile ES scalability with non-monotonic training dynamics and suggest that high-dimensional fine-tuning may admit a broader class of viable optimization methods than worst-case theory implies.
Beyond Pixel Simulation: Pathology Image Generation via Diagnostic Semantic Tokens and Prototype Control
Dec 24, 2025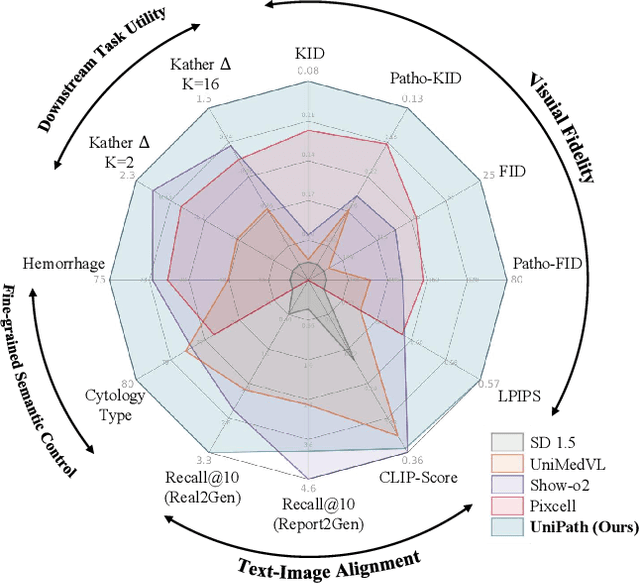
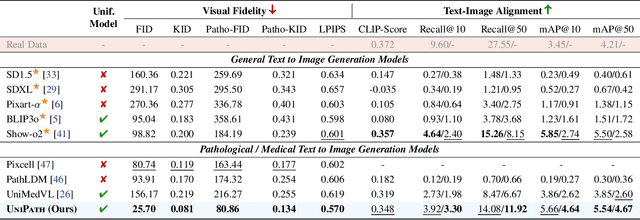
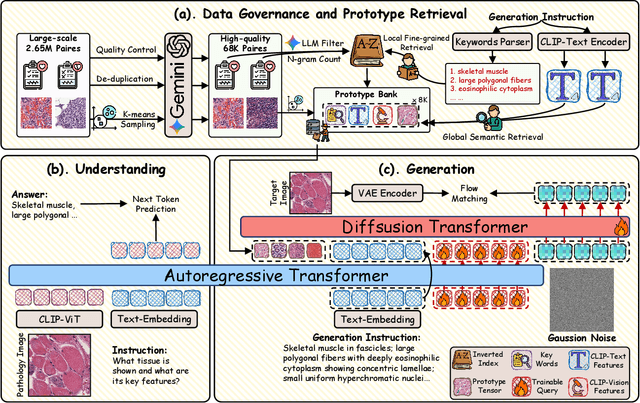
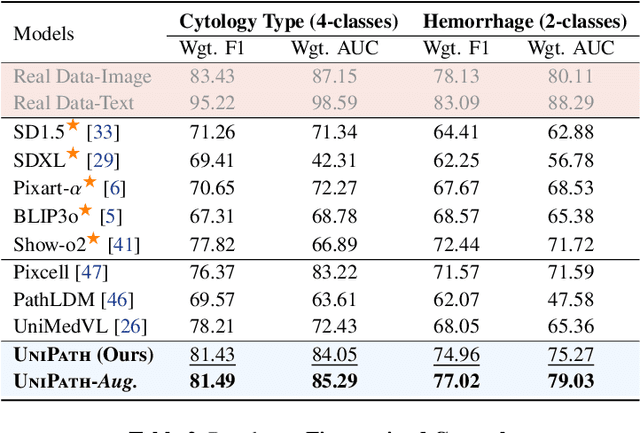
In computational pathology, understanding and generation have evolved along disparate paths: advanced understanding models already exhibit diagnostic-level competence, whereas generative models largely simulate pixels. Progress remains hindered by three coupled factors: the scarcity of large, high-quality image-text corpora; the lack of precise, fine-grained semantic control, which forces reliance on non-semantic cues; and terminological heterogeneity, where diverse phrasings for the same diagnostic concept impede reliable text conditioning. We introduce UniPath, a semantics-driven pathology image generation framework that leverages mature diagnostic understanding to enable controllable generation. UniPath implements Multi-Stream Control: a Raw-Text stream; a High-Level Semantics stream that uses learnable queries to a frozen pathology MLLM to distill paraphrase-robust Diagnostic Semantic Tokens and to expand prompts into diagnosis-aware attribute bundles; and a Prototype stream that affords component-level morphological control via a prototype bank. On the data front, we curate a 2.65M image-text corpus and a finely annotated, high-quality 68K subset to alleviate data scarcity. For a comprehensive assessment, we establish a four-tier evaluation hierarchy tailored to pathology. Extensive experiments demonstrate UniPath's SOTA performance, including a Patho-FID of 80.9 (51% better than the second-best) and fine-grained semantic control achieving 98.7% of the real-image. The meticulously curated datasets, complete source code, and pre-trained model weights developed in this study will be made openly accessible to the public.