 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISE-Flow: Workflow-Induced Structured Experience for Self-Evolving Conversational Service Agents
Jan 13, 2026Large language model (LLM)-based agents are widely deployed in user-facing services but remain error-prone in new tasks, tend to repeat the same failure patterns, and show substantial run-to-run variability. Fixing failures via environment-specific training or manual patching is costly and hard to scale. To enable self-evolving agents in user-facing service environments, we propose WISE-Flow, a workflow-centric framework that converts historical service interactions into reusable procedural experience by inducing workflows with prerequisite-augmented action blocks. At deployment, WISE-Flow aligns the agent's execution trajectory to retrieved workflows and performs prerequisite-aware feasibility reasoning to achieve state-grounded next actions. Experiments on ToolSandbox and $τ^2$-bench show consistent improvement across base models.
Style Transfer: From Stitching to Neural Networks
Sep 01, 2024This article compares two style transfer methods in image processing: the traditional method, which synthesizes new images by stitching together small patches from existing images, and a modern machine learning-based approach that uses a segmentation network to isolate foreground objects and apply style transfer solely to the background. The traditional method excels in creating artistic abstractions but can struggle with seamlessness, whereas the machine learning method preserves the integrity of foreground elements while enhancing the background, offering improved aesthetic quality and computational efficiency. Our study indicates that machine learning-based methods are more suited for real-world applications where detail preservation in foreground elements is essential.
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Aug 28, 2024



As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
DHP Benchmark: Are LLMs Good NLG Evaluators?
Aug 25, 2024Large Language Models (LLMs) are increasingly serving as evaluators in Natural Language Generation (NLG) tasks. However, the capabilities of LLMs in scoring NLG quality remain inadequately explored. Current studies depend on human assessments and simple metrics that fail to capture the discernment of LLMs across diverse NLG tasks. To address this gap, we propose the Discernment of Hierarchical Perturbation (DHP) benchmarking framework, which provides quantitative discernment scores for LLMs utilizing hierarchically perturbed text data and statistical tests to measure the NLG evaluation capabilities of LLMs systematically. We have re-established six evaluation datasets for this benchmark, covering four NLG tasks: Summarization, Story Completion, Question Answering, and Translation. Our comprehensive benchmarking of five major LLM series provides critical insight into their strengths and limitations as NLG evaluators.
FANTAstic SEquences and Where to Find Them: Faithful and Efficient API Call Generation through State-tracked Constrained Decoding and Reranking
Jul 18, 2024



API call generation is the cornerstone of large language models' tool-using ability that provides access to the larger world. However, existing supervised and in-context learning approaches suffer from high training costs, poor data efficiency, and generated API calls that can be unfaithful to the API documentation and the user's request. To address these limitations, we propose an output-side optimization approach called FANTASE. Two of the unique contributions of FANTASE are its State-Tracked Constrained Decoding (SCD) and Reranking components. SCD dynamically incorporates appropriate API constraints in the form of Token Search Trie for efficient and guaranteed generation faithfulness with respect to the API documentation. The Reranking component efficiently brings in the supervised signal by leveraging a lightweight model as the discriminator to rerank the beam-searched candidate generations of the large language model. We demonstrate the superior performance of FANTASE in API call generation accuracy, inference efficiency, and context efficiency with DSTC8 and API Bank datasets.
Unsupervised Candidate Answer Extraction through Differentiable Masker-Reconstructor Model
Oct 19, 2023Question generation is a widely used data augmentation approach with extensive applications, and extracting qualified candidate answers from context passages is a critical step for most question generation systems. However, existing methods for candidate answer extraction are reliant on linguistic rules or annotated data that face the partial annotation issue and challenges in generalization. To overcome these limitations, we propose a novel unsupervised candidate answer extraction approach that leverages the inherent structure of context passages through a Differentiable Masker-Reconstructor (DMR) Model with the enforcement of self-consistency for picking up salient information tokens. We curated two datasets with exhaustively-annotated answers and benchmark a comprehensive set of supervised and unsupervised candidate answer extraction methods. We demonstrate the effectiveness of the DMR model by showing its performance is superior among unsupervised methods and comparable to supervised methods.
Co$^2$PT: Mitigating Bias in Pre-trained Language Models through Counterfactual Contrastive Prompt Tuning
Oct 19, 2023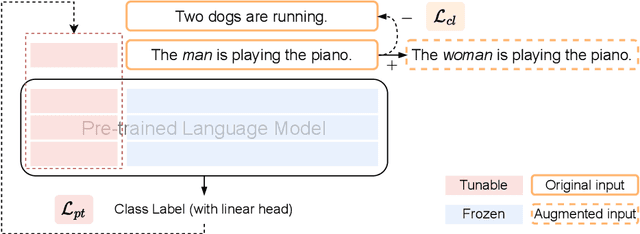
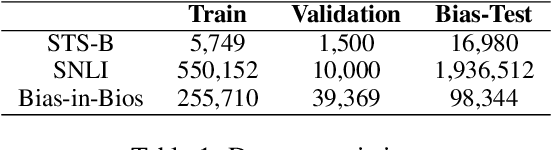
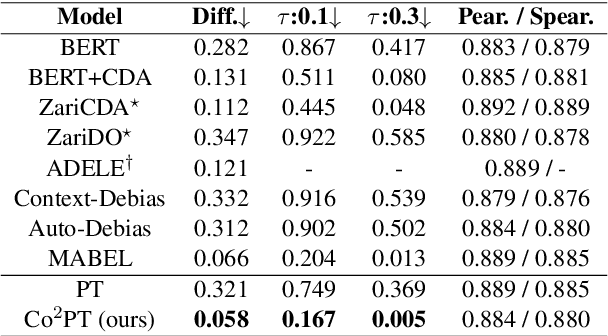
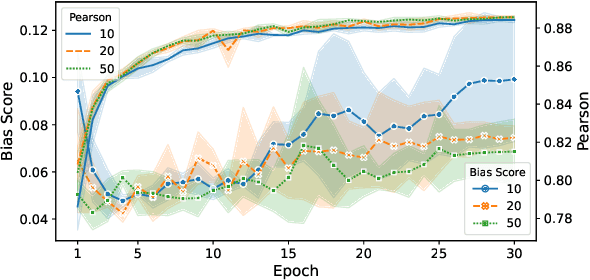
Pre-trained Language Models are widely used in many important real-world applications. However, recent studies show that these models can encode social biases from large pre-training corpora and even amplify biases in downstream applications. To address this challenge, we propose Co$^2$PT, an efficient and effective debias-while-prompt tuning method for mitigating biases via counterfactual contrastive prompt tuning on downstream tasks. Our experiments conducted on three extrinsic bias benchmarks demonstrate the effectiveness of Co$^2$PT on bias mitigation during the prompt tuning process and its adaptability to existing upstream debiased language models. These findings indicate the strength of Co$^2$PT and provide promising avenues for further enhancement in bias mitigation on downstream tasks.
Faithful Low-Resource Data-to-Text Generation through Cycle Training
May 24, 2023Methods to generate text from structured data have advanced significantly in recent years, primarily due to fine-tuning of pre-trained language models on large datasets. However, such models can fail to produce output faithful to the input data, particularly on out-of-domain data. Sufficient annotated data is often not available for specific domains, leading us to seek an unsupervised approach to improve the faithfulness of output text. Since the problem is fundamentally one of consistency between the representations of the structured data and text, we evaluate the effectiveness of cycle training in this work. Cycle training uses two models which are inverses of each other: one that generates text from structured data, and one which generates the structured data from natural language text. We show that cycle training, when initialized with a small amount of supervised data (100 samples in our case), achieves nearly the same performance as fully supervised approaches for the data-to-text generation task on the WebNLG, E2E, WTQ, and WSQL datasets. We perform extensive empirical analysis with automated evaluation metrics and a newly designed human evaluation schema to reveal different cycle training strategies' effectiveness of reducing various types of generation errors. Our code is publicly available at https://github.com/Edillower/CycleNLG.
Predicting the Reproducibility of Social and Behavioral Science Papers Using Supervised Learning Models
Apr 08, 2021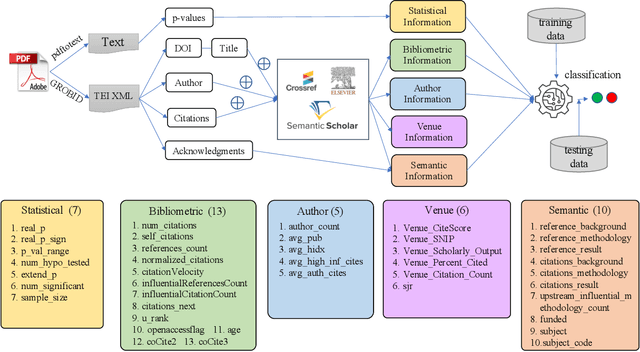
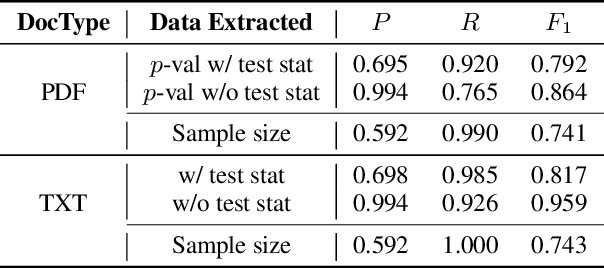
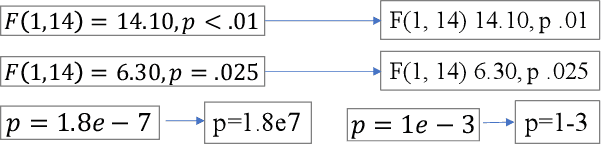
In recent years, significant effort has been invested verifying the reproducibility and robustness of research claims in social and behavioral sciences (SBS), much of which has involved resource-intensive replication projects. In this paper, we investigate prediction of the reproducibility of SBS papers using machine learning methods based on a set of features. We propose a framework that extracts five types of features from scholarly work that can be used to support assessments of reproducibility of published research claims. Bibliometric features, venue features, and author features are collected from public APIs or extracted using open source machine learning libraries with customized parsers. Statistical features, such as p-values, are extracted by recognizing patterns in the body text. Semantic features, such as funding information, are obtained from public APIs or are extracted using natural language processing models. We analyze pairwise correlations between individual features and their importance for predicting a set of human-assessed ground truth labels. In doing so, we identify a subset of 9 top features that play relatively more important roles in predicting the reproducibility of SBS papers in our corpus. Results are verified by comparing performances of 10 supervised predictive classifiers trained on different sets of features.
PARADE: A New Dataset for Paraphrase Identification Requiring Computer Science Domain Knowledge
Oct 08, 2020



We present a new benchmark dataset called PARADE for paraphrase identification that requires specialized domain knowledge. PARADE contains paraphrases that overlap very little at the lexical and syntactic level but are semantically equivalent based on computer science domain knowledge, as well as non-paraphrases that overlap greatly at the lexical and syntactic level but are not semantically equivalent based on this domain knowledge. Experiments show that both state-of-the-art neural models and non-expert human annotators have poor performance on PARADE. For example, BERT after fine-tuning achieves an F1 score of 0.709, which is much lower than its performance on other paraphrase identification datasets. PARADE can serve as a resource for researchers interested in testing models that incorporate domain knowledge. We make our data and code freely available.