 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCC30k: A Citation Contexts Dataset for Reproducibility-Oriented Sentiment Analysis
Nov 11, 2025

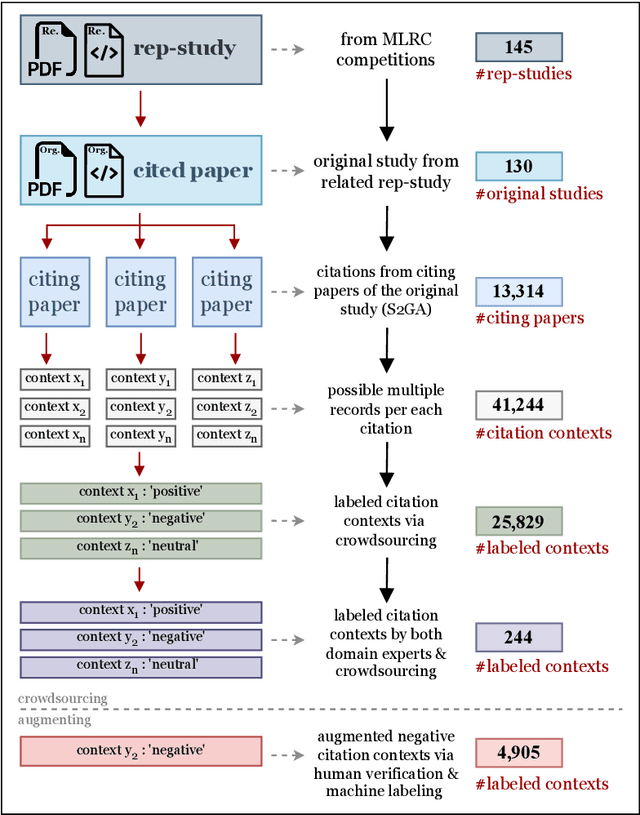

Sentiments about the reproducibility of cited papers in downstream literature offer community perspectives and have shown as a promising signal of the actual reproducibility of published findings. To train effective models to effectively predict reproducibility-oriented sentiments and further systematically study their correlation with reproducibility, we introduce the CC30k dataset, comprising a total of 30,734 citation contexts in machine learning papers. Each citation context is labeled with one of three reproducibility-oriented sentiment labels: Positive, Negative, or Neutral, reflecting the cited paper's perceived reproducibility or replicability. Of these, 25,829 are labeled through crowdsourcing, supplemented with negatives generated through a controlled pipeline to counter the scarcity of negative labels. Unlike traditional sentiment analysis datasets, CC30k focuses on reproducibility-oriented sentiments, addressing a research gap in resources for computational reproducibility studies. The dataset was created through a pipeline that includes robust data cleansing, careful crowd selection, and thorough validation. The resulting dataset achieves a labeling accuracy of 94%. We then demonstrated that the performance of three large language models significantly improves on the reproducibility-oriented sentiment classification after fine-tuning using our dataset. The dataset lays the foundation for large-scale assessments of the reproducibility of machine learning papers. The CC30k dataset and the Jupyter notebooks used to produce and analyze the dataset are publicly available at https://github.com/lamps-lab/CC30k .
Can citations tell us about a paper's reproducibility? A case study of machine learning papers
May 07, 2024



The iterative character of work in machine learning (ML) and artificial intelligence (AI) and reliance on comparisons against benchmark datasets emphasize the importance of reproducibility in that literature. Yet, resource constraints and inadequate documentation can make running replications particularly challenging. Our work explores the potential of using downstream citation contexts as a signal of reproducibility. We introduce a sentiment analysis framework applied to citation contexts from papers involved in Machine Learning Reproducibility Challenges in order to interpret the positive or negative outcomes of reproduction attempts. Our contributions include training classifiers for reproducibility-related contexts and sentiment analysis, and exploring correlations between citation context sentiment and reproducibility scores. Study data, software, and an artifact appendix are publicly available at https://github.com/lamps-lab/ccair-ai-reproducibility .
Active Class Selection for Few-Shot Class-Incremental Learning
Jul 05, 2023For real-world applications, robots will need to continually learn in their environments through limited interactions with their users. Toward this, previous works in few-shot class incremental learning (FSCIL) and active class selection (ACS) have achieved promising results but were tested in constrained setups. Therefore, in this paper, we combine ideas from FSCIL and ACS to develop a novel framework that can allow an autonomous agent to continually learn new objects by asking its users to label only a few of the most informative objects in the environment. To this end, we build on a state-of-the-art (SOTA) FSCIL model and extend it with techniques from ACS literature. We term this model Few-shot Incremental Active class SeleCtiOn (FIASco). We further integrate a potential field-based navigation technique with our model to develop a complete framework that can allow an agent to process and reason on its sensory data through the FIASco model, navigate towards the most informative object in the environment, gather data about the object through its sensors and incrementally update the FIASco model. Experimental results on a simulated agent and a real robot show the significance of our approach for long-term real-world robotics applications.
Predicting the Reproducibility of Social and Behavioral Science Papers Using Supervised Learning Models
Apr 08, 2021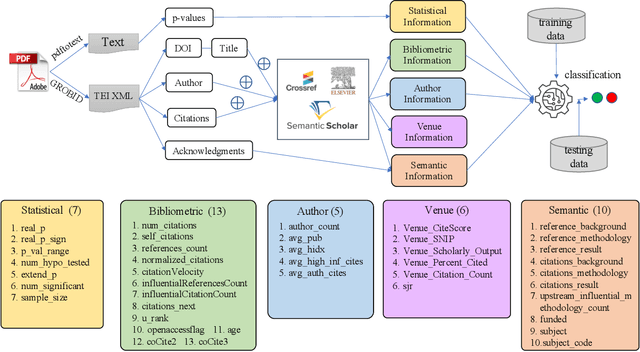
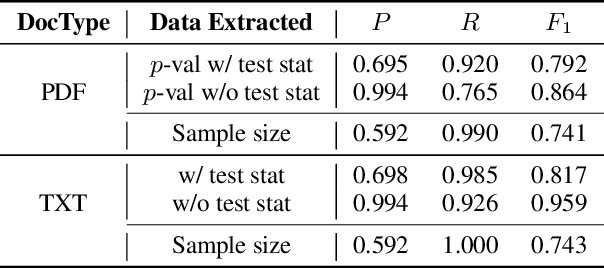
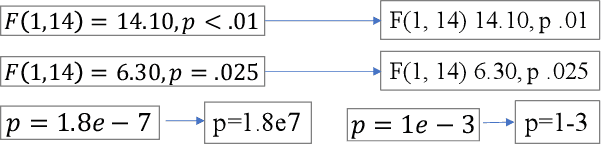
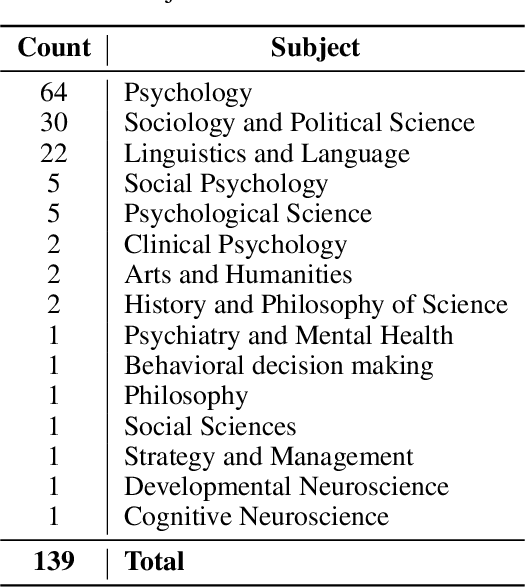
In recent years, significant effort has been invested verifying the reproducibility and robustness of research claims in social and behavioral sciences (SBS), much of which has involved resource-intensive replication projects. In this paper, we investigate prediction of the reproducibility of SBS papers using machine learning methods based on a set of features. We propose a framework that extracts five types of features from scholarly work that can be used to support assessments of reproducibility of published research claims. Bibliometric features, venue features, and author features are collected from public APIs or extracted using open source machine learning libraries with customized parsers. Statistical features, such as p-values, are extracted by recognizing patterns in the body text. Semantic features, such as funding information, are obtained from public APIs or are extracted using natural language processing models. We analyze pairwise correlations between individual features and their importance for predicting a set of human-assessed ground truth labels. In doing so, we identify a subset of 9 top features that play relatively more important roles in predicting the reproducibility of SBS papers in our corpus. Results are verified by comparing performances of 10 supervised predictive classifiers trained on different sets of features.