 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveRAG: A diverse Q&A dataset with varying difficulty level for RAG evaluation
Nov 18, 2025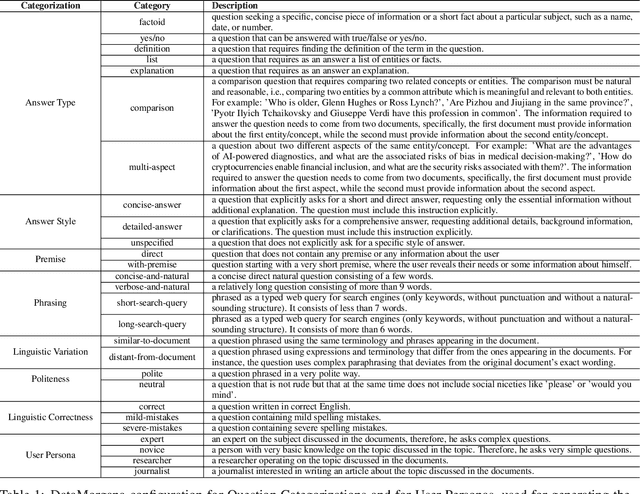
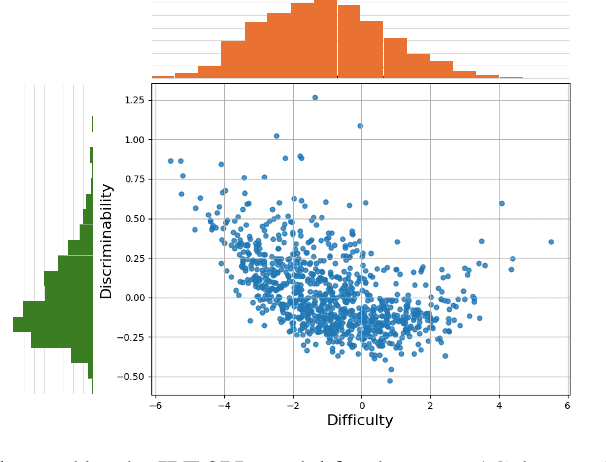
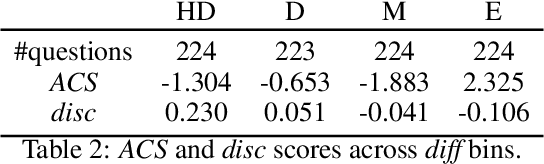
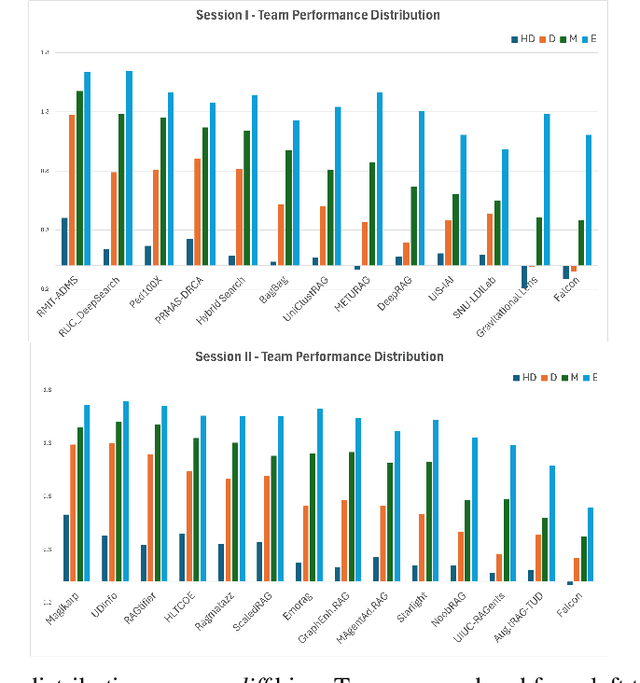
With Retrieval Augmented Generation (RAG) becoming more and more prominent in generative AI solutions, there is an emerging need for systematically evaluating their effectiveness. We introduce the LiveRAG benchmark, a publicly available dataset of 895 synthetic questions and answers designed to support systematic evaluation of RAG-based Q&A systems. This synthetic benchmark is derived from the one used during the SIGIR'2025 LiveRAG Challenge, where competitors were evaluated under strict time constraints. It is augmented with information that was not made available to competitors during the Challenge, such as the ground-truth answers, together with their associated supporting claims which were used for evaluating competitors' answers. In addition, each question is associated with estimated difficulty and discriminability scores, derived from applying an Item Response Theory model to competitors' responses. Our analysis highlights the benchmark's questions diversity, the wide range of their difficulty levels, and their usefulness in differentiating between system capabilities. The LiveRAG benchmark will hopefully help the community advance RAG research, conduct systematic evaluation, and develop more robust Q&A systems.
Redefining Retrieval Evaluation in the Era of LLMs
Oct 24, 2025Traditional Information Retrieval (IR) metrics, such as nDCG, MAP, and MRR, assume that human users sequentially examine documents with diminishing attention to lower ranks. This assumption breaks down in Retrieval Augmented Generation (RAG) systems, where search results are consumed by Large Language Models (LLMs), which, unlike humans, process all retrieved documents as a whole rather than sequentially. Additionally, traditional IR metrics do not account for related but irrelevant documents that actively degrade generation quality, rather than merely being ignored. Due to these two major misalignments, namely human vs. machine position discount and human relevance vs. machine utility, classical IR metrics do not accurately predict RAG performance. We introduce a utility-based annotation schema that quantifies both the positive contribution of relevant passages and the negative impact of distracting ones. Building on this foundation, we propose UDCG (Utility and Distraction-aware Cumulative Gain), a metric using an LLM-oriented positional discount to directly optimize the correlation with the end-to-end answer accuracy. Experiments on five datasets and six LLMs demonstrate that UDCG improves correlation by up to 36% compared to traditional metrics. Our work provides a critical step toward aligning IR evaluation with LLM consumers and enables more reliable assessment of RAG components
Do RAG Systems Suffer From Positional Bias?
May 21, 2025Retrieval Augmented Generation enhances LLM accuracy by adding passages retrieved from an external corpus to the LLM prompt. This paper investigates how positional bias - the tendency of LLMs to weight information differently based on its position in the prompt - affects not only the LLM's capability to capitalize on relevant passages, but also its susceptibility to distracting passages. Through extensive experiments on three benchmarks, we show how state-of-the-art retrieval pipelines, while attempting to retrieve relevant passages, systematically bring highly distracting ones to the top ranks, with over 60% of queries containing at least one highly distracting passage among the top-10 retrieved passages. As a result, the impact of the LLM positional bias, which in controlled settings is often reported as very prominent by related works, is actually marginal in real scenarios since both relevant and distracting passages are, in turn, penalized. Indeed, our findings reveal that sophisticated strategies that attempt to rearrange the passages based on LLM positional preferences do not perform better than random shuffling.
The Distracting Effect: Understanding Irrelevant Passages in RAG
May 11, 2025A well-known issue with Retrieval Augmented Generation (RAG) is that retrieved passages that are irrelevant to the query sometimes distract the answer-generating LLM, causing it to provide an incorrect response. In this paper, we shed light on this core issue and formulate the distracting effect of a passage w.r.t. a query (and an LLM). We provide a quantifiable measure of the distracting effect of a passage and demonstrate its robustness across LLMs. Our research introduces novel methods for identifying and using hard distracting passages to improve RAG systems. By fine-tuning LLMs with these carefully selected distracting passages, we achieve up to a 7.5% increase in answering accuracy compared to counterparts fine-tuned on conventional RAG datasets. Our contribution is two-fold: first, we move beyond the simple binary classification of irrelevant passages as either completely unrelated vs. distracting, and second, we develop and analyze multiple methods for finding hard distracting passages. To our knowledge, no other research has provided such a comprehensive framework for identifying and utilizing hard distracting passages.
Enhancing Low-Resource LLMs Classification with PEFT and Synthetic Data
Apr 03, 2024Large Language Models (LLMs) operating in 0-shot or few-shot settings achieve competitive results in Text Classification tasks. In-Context Learning (ICL) typically achieves better accuracy than the 0-shot setting, but it pays in terms of efficiency, due to the longer input prompt. In this paper, we propose a strategy to make LLMs as efficient as 0-shot text classifiers, while getting comparable or better accuracy than ICL. Our solution targets the low resource setting, i.e., when only 4 examples per class are available. Using a single LLM and few-shot real data we perform a sequence of generation, filtering and Parameter-Efficient Fine-Tuning steps to create a robust and efficient classifier. Experimental results show that our approach leads to competitive results on multiple text classification datasets.
The Power of Noise: Redefining Retrieval for RAG Systems
Jan 29, 2024



Retrieval-Augmented Generation (RAG) systems represent a significant advancement over traditional Large Language Models (LLMs). RAG systems enhance their generation ability by incorporating external data retrieved through an Information Retrieval (IR) phase, overcoming the limitations of standard LLMs, which are restricted to their pre-trained knowledge and limited context window. Most research in this area has predominantly concentrated on the generative aspect of LLMs within RAG systems. Our study fills this gap by thoroughly and critically analyzing the influence of IR components on RAG systems. This paper analyzes which characteristics a retriever should possess for an effective RAG's prompt formulation, focusing on the type of documents that should be retrieved. We evaluate various elements, such as the relevance of the documents to the prompt, their position, and the number included in the context. Our findings reveal, among other insights, that including irrelevant documents can unexpectedly enhance performance by more than 30% in accuracy, contradicting our initial assumption of diminished quality. These results underscore the need for developing specialized strategies to integrate retrieval with language generation models, thereby laying the groundwork for future research in this field.
Evaluation Metrics of Language Generation Models for Synthetic Traffic Generation Tasks
Nov 21, 2023Many Natural Language Generation (NLG) tasks aim to generate a single output text given an input prompt. Other settings require the generation of multiple texts, e.g., for Synthetic Traffic Generation (STG). This generation task is crucial for training and evaluating QA systems as well as conversational agents, where the goal is to generate multiple questions or utterances resembling the linguistic variability of real users. In this paper, we show that common NLG metrics, like BLEU, are not suitable for evaluating STG. We propose and evaluate several metrics designed to compare the generated traffic to the distribution of real user texts. We validate our metrics with an automatic procedure to verify whether they capture different types of quality issues of generated data; we also run human annotations to verify the correlation with human judgements. Experiments on three tasks, i.e., Shopping Utterance Generation, Product Question Generation and Query Auto Completion, demonstrate that our metrics are effective for evaluating STG tasks, and improve the agreement with human judgement up to 20% with respect to common NLG metrics. We believe these findings can pave the way towards better solutions for estimating the representativeness of synthetic text data.
Faithful Low-Resource Data-to-Text Generation through Cycle Training
May 24, 2023



Methods to generate text from structured data have advanced significantly in recent years, primarily due to fine-tuning of pre-trained language models on large datasets. However, such models can fail to produce output faithful to the input data, particularly on out-of-domain data. Sufficient annotated data is often not available for specific domains, leading us to seek an unsupervised approach to improve the faithfulness of output text. Since the problem is fundamentally one of consistency between the representations of the structured data and text, we evaluate the effectiveness of cycle training in this work. Cycle training uses two models which are inverses of each other: one that generates text from structured data, and one which generates the structured data from natural language text. We show that cycle training, when initialized with a small amount of supervised data (100 samples in our case), achieves nearly the same performance as fully supervised approaches for the data-to-text generation task on the WebNLG, E2E, WTQ, and WSQL datasets. We perform extensive empirical analysis with automated evaluation metrics and a newly designed human evaluation schema to reveal different cycle training strategies' effectiveness of reducing various types of generation errors. Our code is publicly available at https://github.com/Edillower/CycleNLG.
Preventing Catastrophic Forgetting in Continual Learning of New Natural Language Tasks
Feb 22, 2023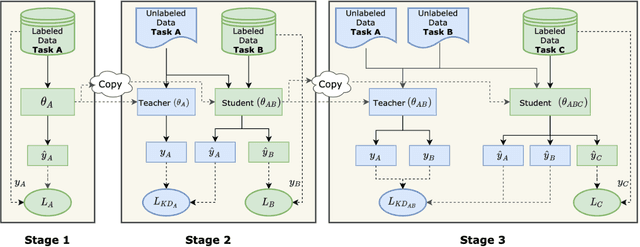

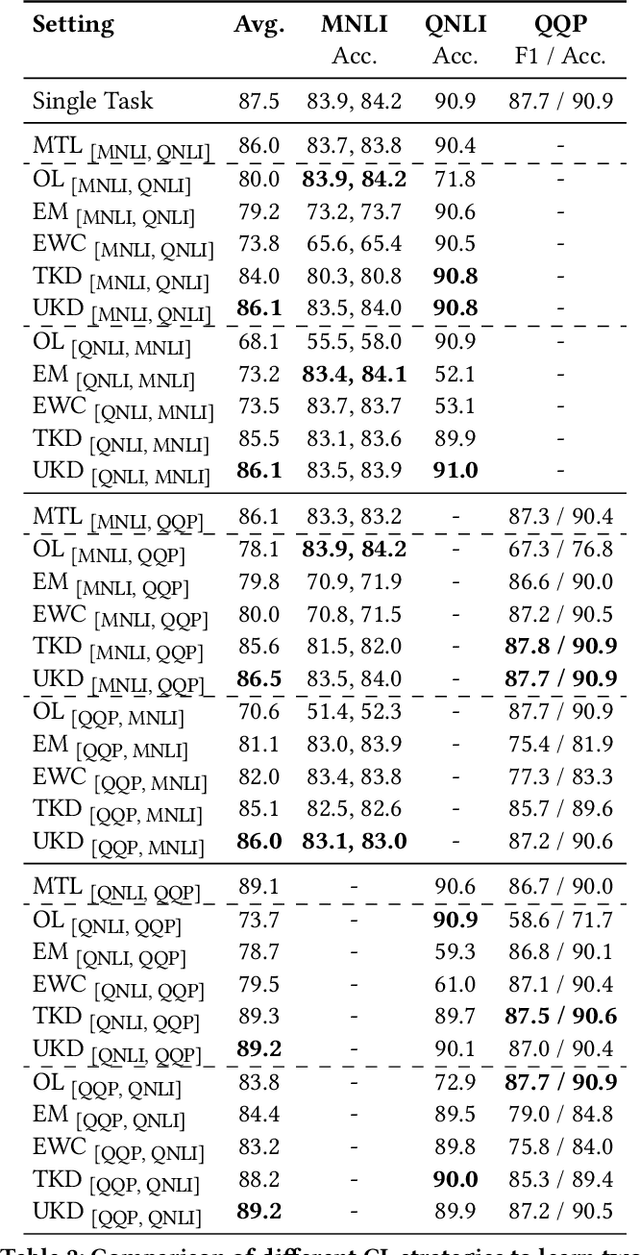
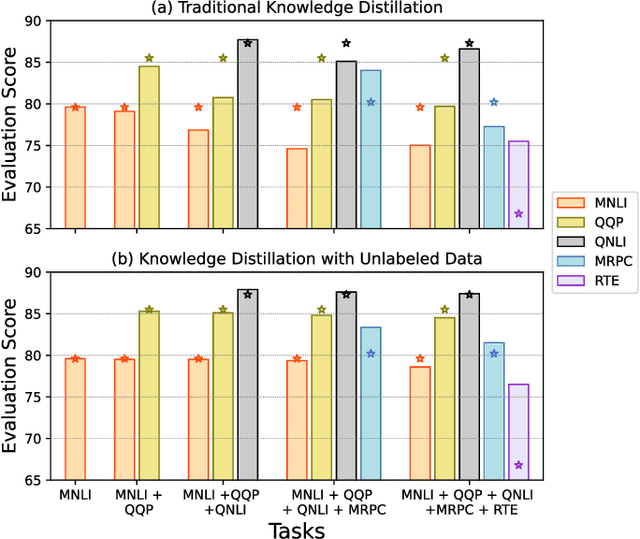
Multi-Task Learning (MTL) is widely-accepted in Natural Language Processing as a standard technique for learning multiple related tasks in one model. Training an MTL model requires having the training data for all tasks available at the same time. As systems usually evolve over time, (e.g., to support new functionalities), adding a new task to an existing MTL model usually requires retraining the model from scratch on all the tasks and this can be time-consuming and computationally expensive. Moreover, in some scenarios, the data used to train the original training may be no longer available, for example, due to storage or privacy concerns. In this paper, we approach the problem of incrementally expanding MTL models' capability to solve new tasks over time by distilling the knowledge of an already trained model on n tasks into a new one for solving n+1 tasks. To avoid catastrophic forgetting, we propose to exploit unlabeled data from the same distributions of the old tasks. Our experiments on publicly available benchmarks show that such a technique dramatically benefits the distillation by preserving the already acquired knowledge (i.e., preventing up to 20% performance drops on old tasks) while obtaining good performance on the incrementally added tasks. Further, we also show that our approach is beneficial in practical settings by using data from a leading voice assistant.
Global Thread-Level Inference for Comment Classification in Community Question Answering
Nov 20, 2019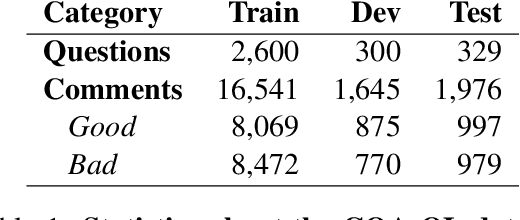

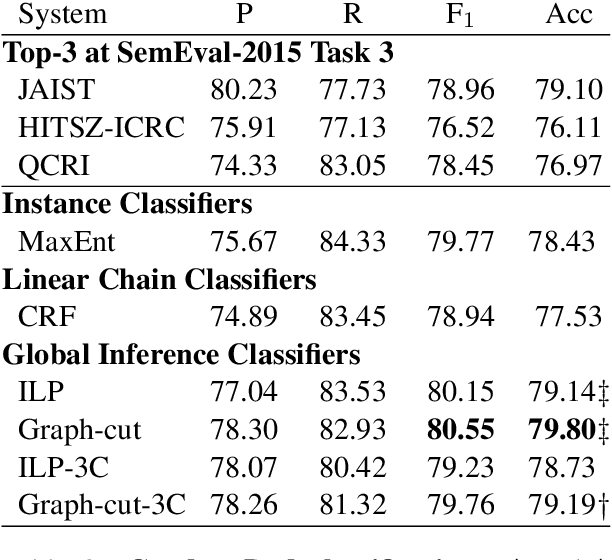
Community question answering, a recent evolution of question answering in the Web context, allows a user to quickly consult the opinion of a number of people on a particular topic, thus taking advantage of the wisdom of the crowd. Here we try to help the user by deciding automatically which answers are good and which are bad for a given question. In particular, we focus on exploiting the output structure at the thread level in order to make more consistent global decisions. More specifically, we exploit the relations between pairs of comments at any distance in the thread, which we incorporate in a graph-cut and in an ILP frameworks. We evaluated our approach on the benchmark dataset of SemEval-2015 Task 3. Results improved over the state of the art, confirming the importance of using thread level information.
* community question answering, thread-level inference, graph-cut, inductive logic programming