 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-Enhanced Multimodal RAG: Towards Interpretable and Accurate Radiology Report Generation
Feb 17, 2026Radiology Report Generation (RRG) through Vision-Language Models (VLMs) promises to reduce documentation burden, improve reporting consistency, and accelerate clinical workflows. However, their clinical adoption remains limited by the lack of interpretability and the tendency to hallucinate findings misaligned with imaging evidence. Existing research typically treats interpretability and accuracy as separate objectives, with concept-based explainability techniques focusing primarily on transparency, while Retrieval-Augmented Generation (RAG) methods targeting factual grounding through external retrieval. We present Concept-Enhanced Multimodal RAG (CEMRAG), a unified framework that decomposes visual representations into interpretable clinical concepts and integrates them with multimodal RAG. This approach exploits enriched contextual prompts for RRG, improving both interpretability and factual accuracy. Experiments on MIMIC-CXR and IU X-Ray across multiple VLM architectures, training regimes, and retrieval configurations demonstrate consistent improvements over both conventional RAG and concept-only baselines on clinical accuracy metrics and standard NLP measures. These results challenge the assumed trade-off between interpretability and performance, showing that transparent visual concepts can enhance rather than compromise diagnostic accuracy in medical VLMs. Our modular design decomposes interpretability into visual transparency and structured language model conditioning, providing a principled pathway toward clinically trustworthy AI-assisted radiology.
AutoBench: Automating LLM Evaluation through Reciprocal Peer Assessment
Oct 26, 2025We present AutoBench, a fully automated and self-sustaining framework for evaluating Large Language Models (LLMs) through reciprocal peer assessment. This paper provides a rigorous scientific validation of the AutoBench methodology, originally developed as an open-source project by eZecute S.R.L.. Unlike static benchmarks that suffer from test-set contamination and limited adaptability, AutoBench dynamically generates novel evaluation tasks while models alternately serve as question generators, contestants, and judges across diverse domains. An iterative weighting mechanism amplifies the influence of consistently reliable evaluators, aggregating peer judgments into consensus-based rankings that reflect collective model agreement. Our experiments demonstrate strong correlations with established benchmarks including MMLU-Pro and GPQA (respectively 78\% and 63\%), validating this peer-driven evaluation paradigm. The multi-judge design significantly outperforms single-judge baselines, confirming that distributed evaluation produces more robust and human-consistent assessments. AutoBench offers a scalable, contamination-resistant alternative to static benchmarks for the continuous evaluation of evolving language models.
Titans Revisited: A Lightweight Reimplementation and Critical Analysis of a Test-Time Memory Model
Oct 10, 2025
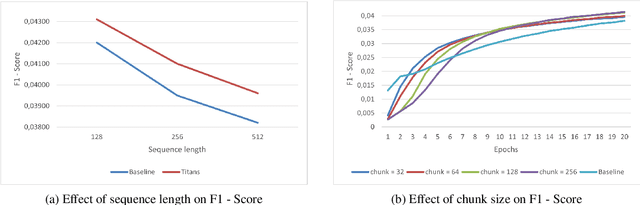
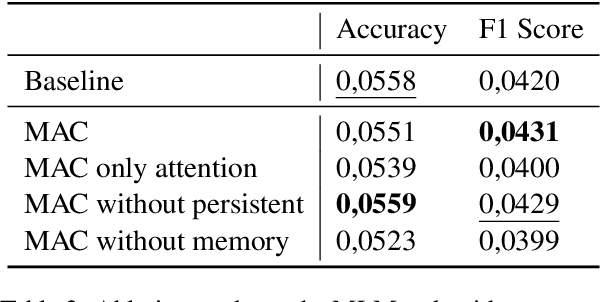
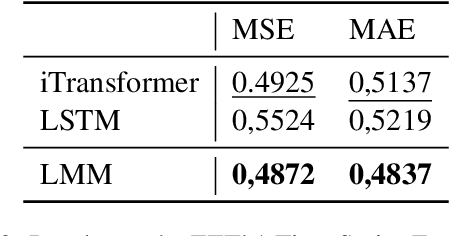
By the end of 2024, Google researchers introduced Titans: Learning at Test Time, a neural memory model achieving strong empirical results across multiple tasks. However, the lack of publicly available code and ambiguities in the original description hinder reproducibility. In this work, we present a lightweight reimplementation of Titans and conduct a comprehensive evaluation on Masked Language Modeling, Time Series Forecasting, and Recommendation tasks. Our results reveal that Titans does not always outperform established baselines due to chunking. However, its Neural Memory component consistently improves performance compared to attention-only models. These findings confirm the model's innovative potential while highlighting its practical limitations and raising questions for future research.
Directional Sheaf Hypergraph Networks: Unifying Learning on Directed and Undirected Hypergraphs
Oct 06, 2025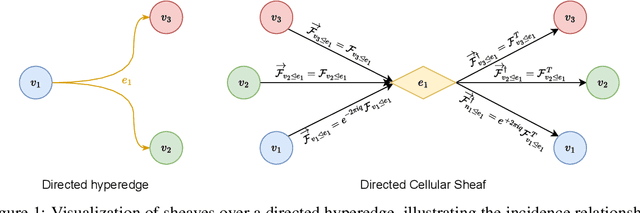
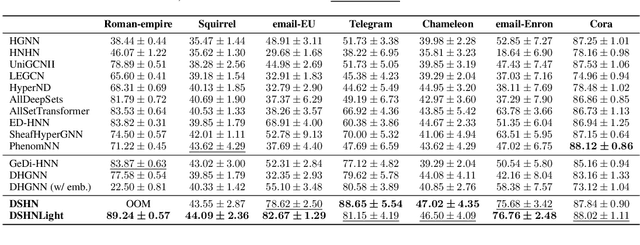
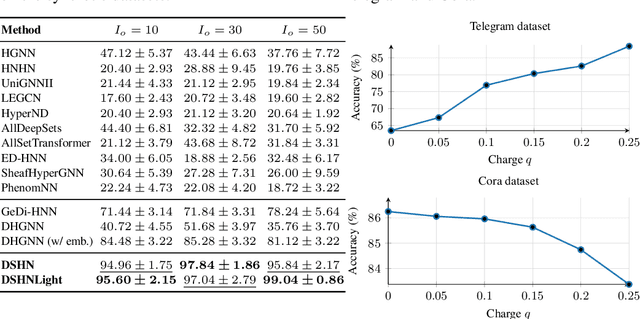
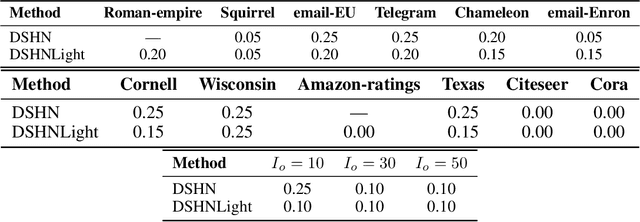
Hypergraphs provide a natural way to represent higher-order interactions among multiple entities. While undirected hypergraphs have been extensively studied, the case of directed hypergraphs, which can model oriented group interactions, remains largely under-explored despite its relevance for many applications. Recent approaches in this direction often exhibit an implicit bias toward homophily, which limits their effectiveness in heterophilic settings. Rooted in the algebraic topology notion of Cellular Sheaves, Sheaf Neural Networks (SNNs) were introduced as an effective solution to circumvent such a drawback. While a generalization to hypergraphs is known, it is only suitable for undirected hypergraphs, failing to tackle the directed case. In this work, we introduce Directional Sheaf Hypergraph Networks (DSHN), a framework integrating sheaf theory with a principled treatment of asymmetric relations within a hypergraph. From it, we construct the Directed Sheaf Hypergraph Laplacian, a complex-valued operator by which we unify and generalize many existing Laplacian matrices proposed in the graph- and hypergraph-learning literature. Across 7 real-world datasets and against 13 baselines, DSHN achieves relative accuracy gains from 2% up to 20%, showing how a principled treatment of directionality in hypergraphs, combined with the expressive power of sheaves, can substantially improve performance.
A Systematic Replicability and Comparative Study of BSARec and SASRec for Sequential Recommendation
Jun 17, 2025This study aims at comparing two sequential recommender systems: Self-Attention based Sequential Recommendation (SASRec), and Beyond Self-Attention based Sequential Recommendation (BSARec) in order to check the improvement frequency enhancement - the added element in BSARec - has on recommendations. The models in the study, have been re-implemented with a common base-structure from EasyRec, with the aim of obtaining a fair and reproducible comparison. The results obtained displayed how BSARec, by including bias terms for frequency enhancement, does indeed outperform SASRec, although the increases in performance obtained, are not as high as those presented by the authors. This work aims at offering an overview on existing methods, and most importantly at underlying the importance of implementation details for performance comparison.
Static Pruning in Dense Retrieval using Matrix Decomposition
Dec 13, 2024

In the era of dense retrieval, document indexing and retrieval is largely based on encoding models that transform text documents into embeddings. The efficiency of retrieval is directly proportional to the number of documents and the size of the embeddings. Recent studies have shown that it is possible to reduce embedding size without sacrificing - and in some cases improving - the retrieval effectiveness. However, the methods introduced by these studies are query-dependent, so they can't be applied offline and require additional computations during query processing, thus negatively impacting the retrieval efficiency. In this paper, we present a novel static pruning method for reducing the dimensionality of embeddings using Principal Components Analysis. This approach is query-independent and can be executed offline, leading to a significant boost in dense retrieval efficiency with a negligible impact on the system effectiveness. Our experiments show that our proposed method reduces the dimensionality of document representations by over 50% with up to a 5% reduction in NDCG@10, for different dense retrieval models.
A Theoretical Analysis of Recommendation Loss Functions under Negative Sampling
Nov 12, 2024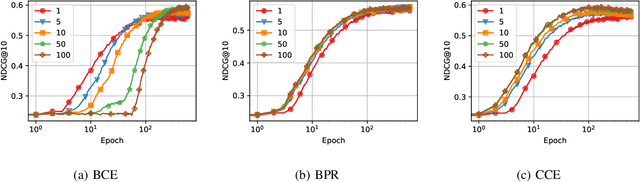
Recommender Systems (RSs) are pivotal in diverse domains such as e-commerce, music streaming, and social media. This paper conducts a comparative analysis of prevalent loss functions in RSs: Binary Cross-Entropy (BCE), Categorical Cross-Entropy (CCE), and Bayesian Personalized Ranking (BPR). Exploring the behaviour of these loss functions across varying negative sampling settings, we reveal that BPR and CCE are equivalent when one negative sample is used. Additionally, we demonstrate that all losses share a common global minimum. Evaluation of RSs mainly relies on ranking metrics known as Normalized Discounted Cumulative Gain (NDCG) and Mean Reciprocal Rank (MRR). We produce bounds of the different losses for negative sampling settings to establish a probabilistic lower bound for NDCG. We show that the BPR bound on NDCG is weaker than that of BCE, contradicting the common assumption that BPR is superior to BCE in RSs training. Experiments on five datasets and four models empirically support these theoretical findings. Our code is available at \url{https://anonymous.4open.science/r/recsys_losses} .
A Reproducible Analysis of Sequential Recommender Systems
Aug 07, 2024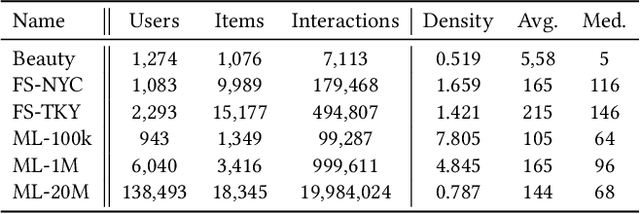
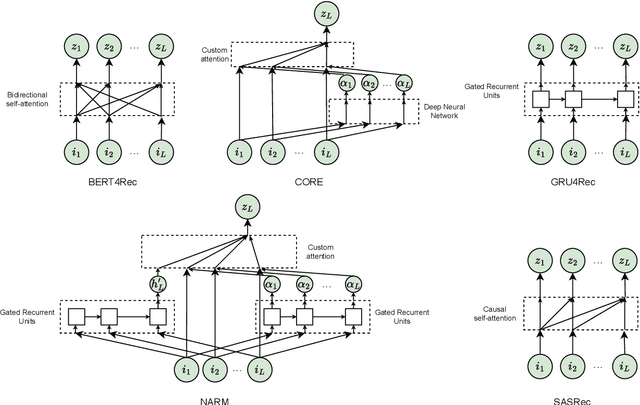

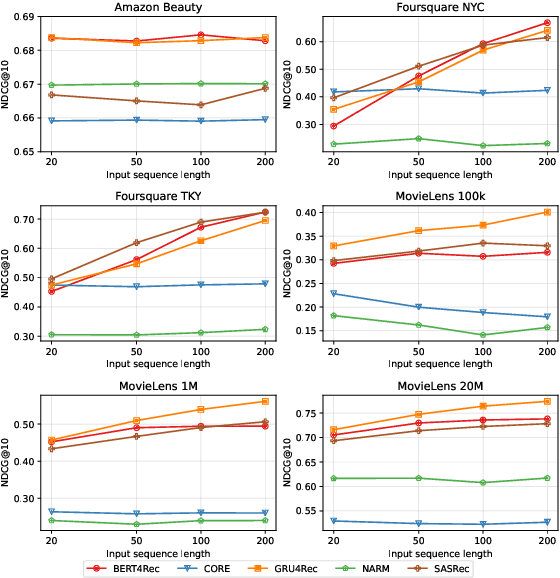
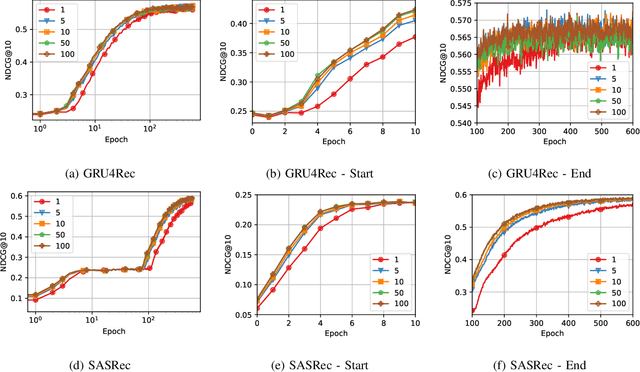
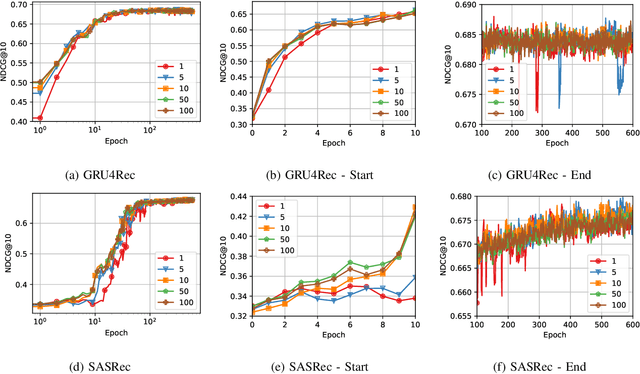
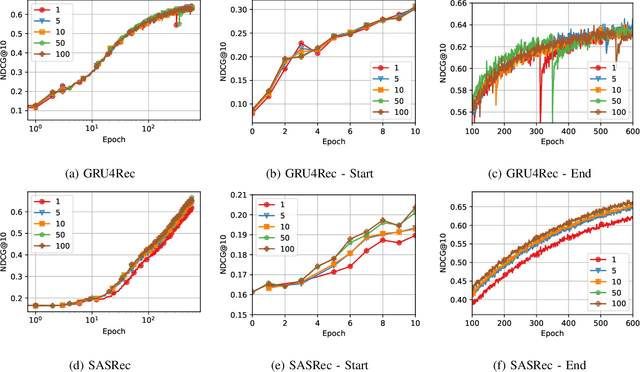
Sequential Recommender Systems (SRSs) have emerged as a highly efficient approach to recommendation systems. By leveraging sequential data, SRSs can identify temporal patterns in user behaviour, significantly improving recommendation accuracy and relevance.Ensuring the reproducibility of these models is paramount for advancing research and facilitating comparisons between them. Existing works exhibit shortcomings in reproducibility and replicability of results, leading to inconsistent statements across papers. Our work fills these gaps by standardising data pre-processing and model implementations, providing a comprehensive code resource, including a framework for developing SRSs and establishing a foundation for consistent and reproducible experimentation. We conduct extensive experiments on several benchmark datasets, comparing various SRSs implemented in our resource. We challenge prevailing performance benchmarks, offering new insights into the SR domain. For instance, SASRec does not consistently outperform GRU4Rec. On the contrary, when the number of model parameters becomes substantial, SASRec starts to clearly dominate all the other SRSs. This discrepancy underscores the significant impact that experimental configuration has on the outcomes and the importance of setting it up to ensure precise and comprehensive results. Failure to do so can lead to significantly flawed conclusions, highlighting the need for rigorous experimental design and analysis in SRS research. Our code is available at https://github.com/antoniopurificato/recsys_repro_conf.
The Power of Noise: Redefining Retrieval for RAG Systems
Jan 29, 2024



Retrieval-Augmented Generation (RAG) systems represent a significant advancement over traditional Large Language Models (LLMs). RAG systems enhance their generation ability by incorporating external data retrieved through an Information Retrieval (IR) phase, overcoming the limitations of standard LLMs, which are restricted to their pre-trained knowledge and limited context window. Most research in this area has predominantly concentrated on the generative aspect of LLMs within RAG systems. Our study fills this gap by thoroughly and critically analyzing the influence of IR components on RAG systems. This paper analyzes which characteristics a retriever should possess for an effective RAG's prompt formulation, focusing on the type of documents that should be retrieved. We evaluate various elements, such as the relevance of the documents to the prompt, their position, and the number included in the context. Our findings reveal, among other insights, that including irrelevant documents can unexpectedly enhance performance by more than 30% in accuracy, contradicting our initial assumption of diminished quality. These results underscore the need for developing specialized strategies to integrate retrieval with language generation models, thereby laying the groundwork for future research in this field.
Adversarial Data Poisoning for Fake News Detection: How to Make a Model Misclassify a Target News without Modifying It
Jan 04, 2024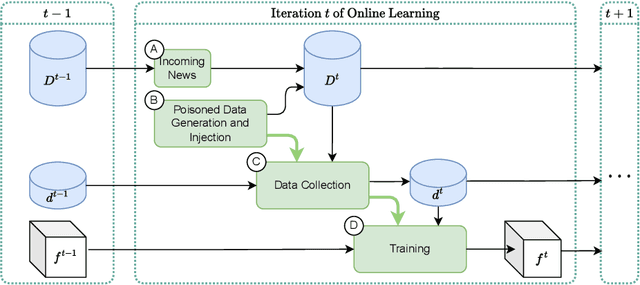
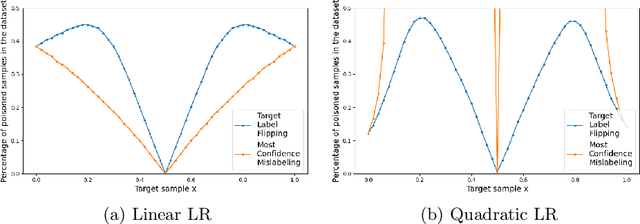
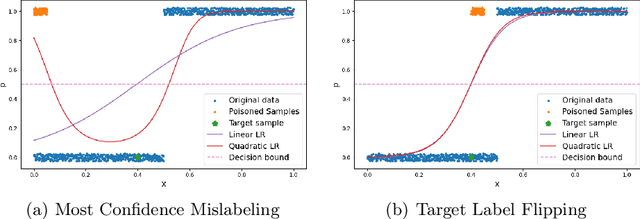
Fake news detection models are critical to countering disinformation but can be manipulated through adversarial attacks. In this position paper, we analyze how an attacker can compromise the performance of an online learning detector on specific news content without being able to manipulate the original target news. In some contexts, such as social networks, where the attacker cannot exert complete control over all the information, this scenario can indeed be quite plausible. Therefore, we show how an attacker could potentially introduce poisoning data into the training data to manipulate the behavior of an online learning method. Our initial findings reveal varying susceptibility of logistic regression models based on complexity and attack type.