 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect, Label, Evaluate: Active Testing in NLP
Mar 23, 2026Human annotation cost and time remain significant bottlenecks in Natural Language Processing (NLP), with test data annotation being particularly expensive due to the stringent requirement for low-error and high-quality labels necessary for reliable model evaluation. Traditional approaches require annotating entire test sets, leading to substantial resource requirements. Active Testing is a framework that selects the most informative test samples for annotation. Given a labeling budget, it aims to choose the subset that best estimates model performance while minimizing cost and human effort. In this work, we formalize Active Testing in NLP and we conduct an extensive benchmarking of existing approaches across 18 datasets and 4 embedding strategies spanning 4 different NLP tasks. The experiments show annotation reductions of up to 95%, with performance estimation accuracy difference from the full test set within 1%. Our analysis reveals variations in method effectiveness across different data characteristics and task types, with no single approach emerging as universally superior. Lastly, to address the limitation of requiring a predefined annotation budget in existing sample selection strategies, we introduce an adaptive stopping criterion that automatically determines the optimal number of samples.
Directional Sheaf Hypergraph Networks: Unifying Learning on Directed and Undirected Hypergraphs
Oct 06, 2025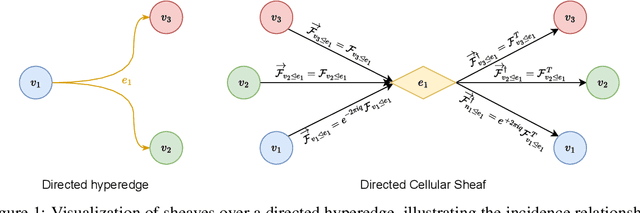
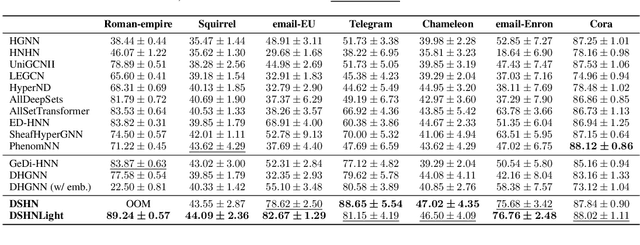
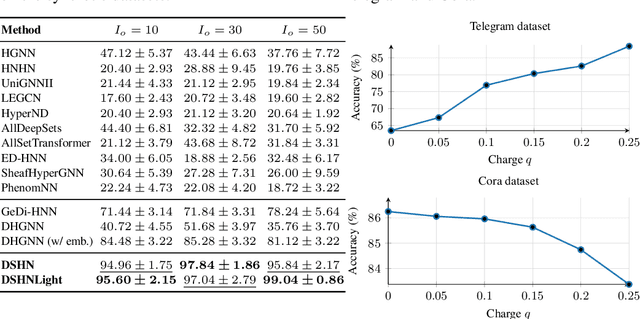
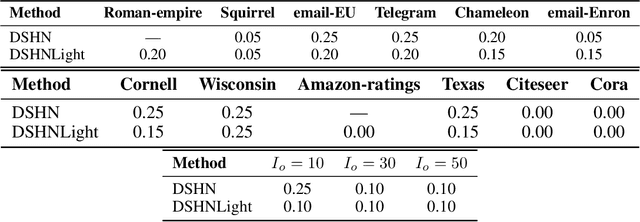
Hypergraphs provide a natural way to represent higher-order interactions among multiple entities. While undirected hypergraphs have been extensively studied, the case of directed hypergraphs, which can model oriented group interactions, remains largely under-explored despite its relevance for many applications. Recent approaches in this direction often exhibit an implicit bias toward homophily, which limits their effectiveness in heterophilic settings. Rooted in the algebraic topology notion of Cellular Sheaves, Sheaf Neural Networks (SNNs) were introduced as an effective solution to circumvent such a drawback. While a generalization to hypergraphs is known, it is only suitable for undirected hypergraphs, failing to tackle the directed case. In this work, we introduce Directional Sheaf Hypergraph Networks (DSHN), a framework integrating sheaf theory with a principled treatment of asymmetric relations within a hypergraph. From it, we construct the Directed Sheaf Hypergraph Laplacian, a complex-valued operator by which we unify and generalize many existing Laplacian matrices proposed in the graph- and hypergraph-learning literature. Across 7 real-world datasets and against 13 baselines, DSHN achieves relative accuracy gains from 2% up to 20%, showing how a principled treatment of directionality in hypergraphs, combined with the expressive power of sheaves, can substantially improve performance.
One Search Fits All: Pareto-Optimal Eco-Friendly Model Selection
May 02, 2025



The environmental impact of Artificial Intelligence (AI) is emerging as a significant global concern, particularly regarding model training. In this paper, we introduce GREEN (Guided Recommendations of Energy-Efficient Networks), a novel, inference-time approach for recommending Pareto-optimal AI model configurations that optimize validation performance and energy consumption across diverse AI domains and tasks. Our approach directly addresses the limitations of current eco-efficient neural architecture search methods, which are often restricted to specific architectures or tasks. Central to this work is EcoTaskSet, a dataset comprising training dynamics from over 1767 experiments across computer vision, natural language processing, and recommendation systems using both widely used and cutting-edge architectures. Leveraging this dataset and a prediction model, our approach demonstrates effectiveness in selecting the best model configuration based on user preferences. Experimental results show that our method successfully identifies energy-efficient configurations while ensuring competitive performance.
The Majority Vote Paradigm Shift: When Popular Meets Optimal
Feb 19, 2025



Reliably labelling data typically requires annotations from multiple human workers. However, humans are far from being perfect. Hence, it is a common practice to aggregate labels gathered from multiple annotators to make a more confident estimate of the true label. Among many aggregation methods, the simple and well known Majority Vote (MV) selects the class label polling the highest number of votes. However, despite its importance, the optimality of MV's label aggregation has not been extensively studied. We address this gap in our work by characterising the conditions under which MV achieves the theoretically optimal lower bound on label estimation error. Our results capture the tolerable limits on annotation noise under which MV can optimally recover labels for a given class distribution. This certificate of optimality provides a more principled approach to model selection for label aggregation as an alternative to otherwise inefficient practices that sometimes include higher experts, gold labels, etc., that are all marred by the same human uncertainty despite huge time and monetary costs. Experiments on both synthetic and real world data corroborate our theoretical findings.
Eco-Aware Graph Neural Networks for Sustainable Recommendations
Oct 12, 2024


Recommender systems play a crucial role in alleviating information overload by providing personalized recommendations tailored to users' preferences and interests. Recently, Graph Neural Networks (GNNs) have emerged as a promising approach for recommender systems, leveraging their ability to effectively capture complex relationships and dependencies between users and items by representing them as nodes in a graph structure. In this study, we investigate the environmental impact of GNN-based recommender systems, an aspect that has been largely overlooked in the literature. Specifically, we conduct a comprehensive analysis of the carbon emissions associated with training and deploying GNN models for recommendation tasks. We evaluate the energy consumption and carbon footprint of different GNN architectures and configurations, considering factors such as model complexity, training duration, hardware specifications and embedding size. By addressing the environmental impact of resource-intensive algorithms in recommender systems, this study contributes to the ongoing efforts towards sustainable and responsible artificial intelligence, promoting the development of eco-friendly recommendation technologies that balance performance and environmental considerations. Code is available at: https://github.com/antoniopurificato/gnn_recommendation_and_environment.
A Reproducible Analysis of Sequential Recommender Systems
Aug 07, 2024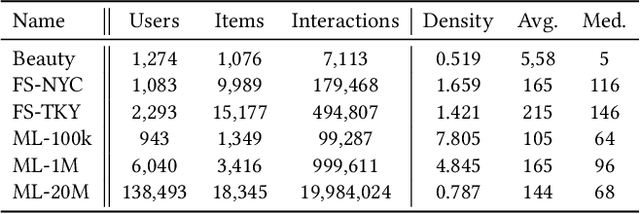
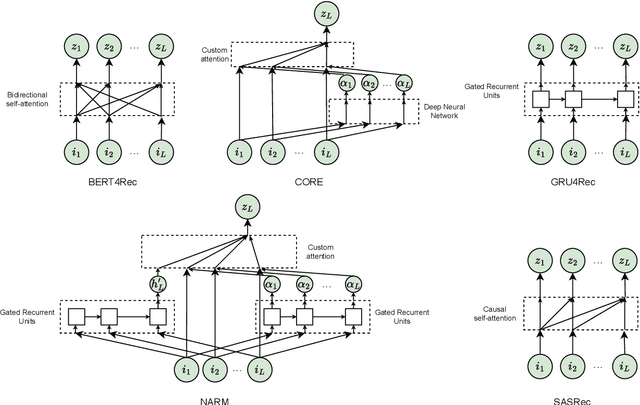

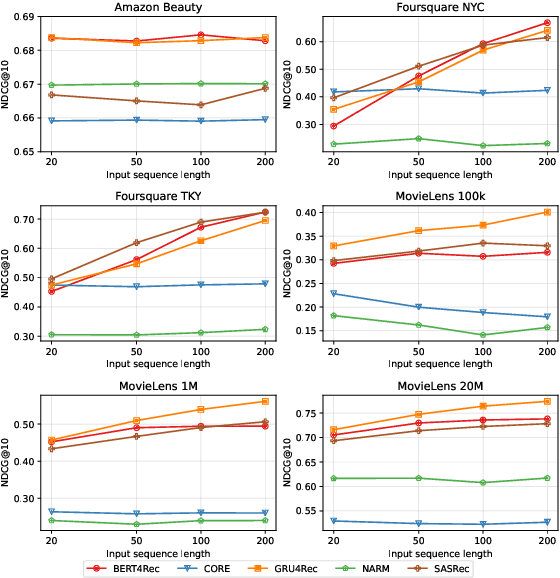
Sequential Recommender Systems (SRSs) have emerged as a highly efficient approach to recommendation systems. By leveraging sequential data, SRSs can identify temporal patterns in user behaviour, significantly improving recommendation accuracy and relevance.Ensuring the reproducibility of these models is paramount for advancing research and facilitating comparisons between them. Existing works exhibit shortcomings in reproducibility and replicability of results, leading to inconsistent statements across papers. Our work fills these gaps by standardising data pre-processing and model implementations, providing a comprehensive code resource, including a framework for developing SRSs and establishing a foundation for consistent and reproducible experimentation. We conduct extensive experiments on several benchmark datasets, comparing various SRSs implemented in our resource. We challenge prevailing performance benchmarks, offering new insights into the SR domain. For instance, SASRec does not consistently outperform GRU4Rec. On the contrary, when the number of model parameters becomes substantial, SASRec starts to clearly dominate all the other SRSs. This discrepancy underscores the significant impact that experimental configuration has on the outcomes and the importance of setting it up to ensure precise and comprehensive results. Failure to do so can lead to significantly flawed conclusions, highlighting the need for rigorous experimental design and analysis in SRS research. Our code is available at https://github.com/antoniopurificato/recsys_repro_conf.
Sheaf Neural Networks for Graph-based Recommender Systems
Apr 07, 2023



Recent progress in Graph Neural Networks has resulted in wide adoption by many applications, including recommendation systems. The reason for Graph Neural Networks' superiority over other approaches is that many problems in recommendation systems can be naturally modeled as graphs, where nodes can be either users or items and edges represent preference relationships. In current Graph Neural Network approaches, nodes are represented with a static vector learned at training time. This static vector might only be suitable to capture some of the nuances of users or items they define. To overcome this limitation, we propose using a recently proposed model inspired by category theory: Sheaf Neural Networks. Sheaf Neural Networks, and its connected Laplacian, can address the previous problem by associating every node (and edge) with a vector space instead than a single vector. The vector space representation is richer and allows picking the proper representation at inference time. This approach can be generalized for different related tasks on graphs and achieves state-of-the-art performance in terms of F1-Score@N in collaborative filtering and Hits@20 in link prediction. For collaborative filtering, the approach is evaluated on the MovieLens 100K with a 5.1% improvement, on MovieLens 1M with a 5.4% improvement and on Book-Crossing with a 2.8% improvement, while for link prediction on the ogbl-ddi dataset with a 1.6% refinement with respect to the respective baselines.