 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Majority Vote Paradigm Shift: When Popular Meets Optimal
Feb 19, 2025



Reliably labelling data typically requires annotations from multiple human workers. However, humans are far from being perfect. Hence, it is a common practice to aggregate labels gathered from multiple annotators to make a more confident estimate of the true label. Among many aggregation methods, the simple and well known Majority Vote (MV) selects the class label polling the highest number of votes. However, despite its importance, the optimality of MV's label aggregation has not been extensively studied. We address this gap in our work by characterising the conditions under which MV achieves the theoretically optimal lower bound on label estimation error. Our results capture the tolerable limits on annotation noise under which MV can optimally recover labels for a given class distribution. This certificate of optimality provides a more principled approach to model selection for label aggregation as an alternative to otherwise inefficient practices that sometimes include higher experts, gold labels, etc., that are all marred by the same human uncertainty despite huge time and monetary costs. Experiments on both synthetic and real world data corroborate our theoretical findings.
Object-Level Context Modeling For Scene Classification with Context-CNN
Jun 02, 2017
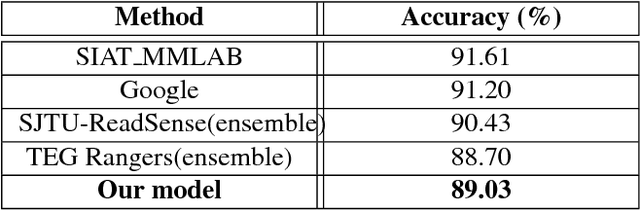
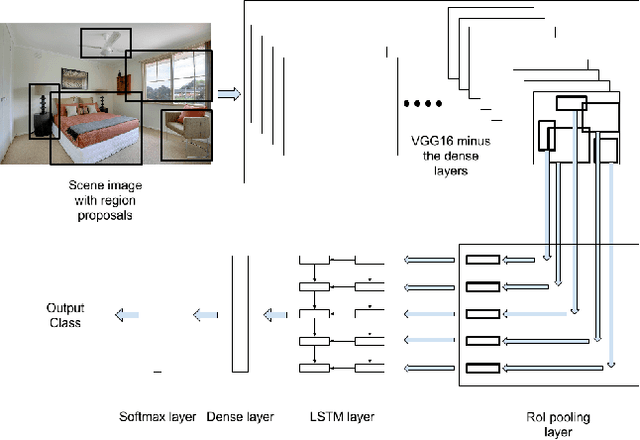
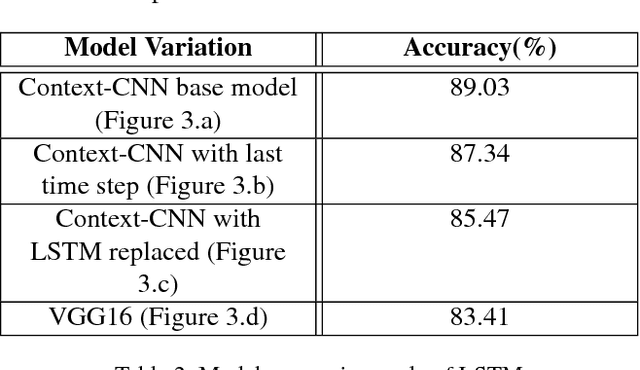
Convolutional Neural Networks (CNNs) have been used extensively for computer vision tasks and produce rich feature representation for objects or parts of an image. But reasoning about scenes requires integration between the low-level feature representations and the high-level semantic information. We propose a deep network architecture which models the semantic context of scenes by capturing object-level information. We use Long Short Term Memory(LSTM) units in conjunction with object proposals to incorporate object-object relationship and object-scene relationship in an end-to-end trainable manner. We evaluate our model on the LSUN dataset and achieve results comparable to the state-of-art. We further show visualization of the learned features and analyze the model with experiments to verify our model's ability to model context.