 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Level Context Modeling For Scene Classification with Context-CNN
Paper and Code
Jun 02, 2017
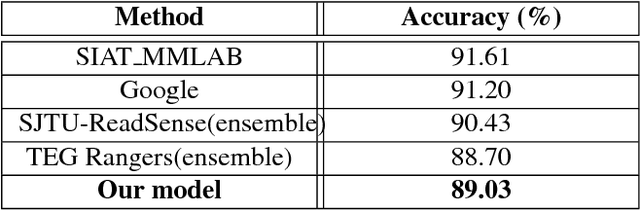
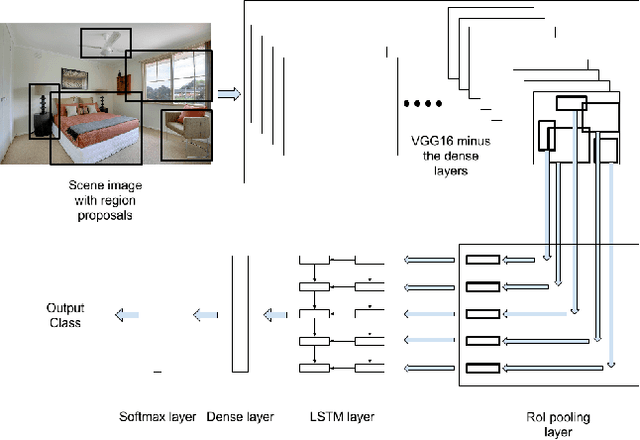
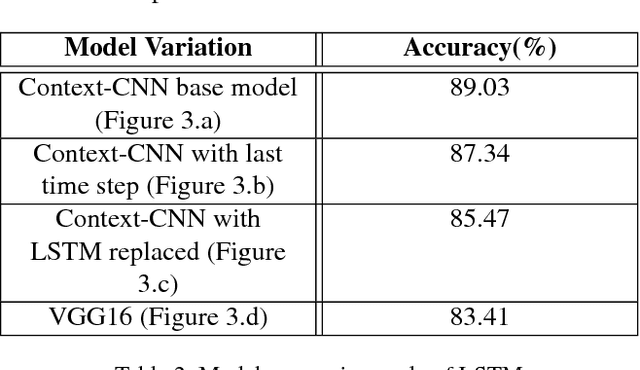
Convolutional Neural Networks (CNNs) have been used extensively for computer vision tasks and produce rich feature representation for objects or parts of an image. But reasoning about scenes requires integration between the low-level feature representations and the high-level semantic information. We propose a deep network architecture which models the semantic context of scenes by capturing object-level information. We use Long Short Term Memory(LSTM) units in conjunction with object proposals to incorporate object-object relationship and object-scene relationship in an end-to-end trainable manner. We evaluate our model on the LSUN dataset and achieve results comparable to the state-of-art. We further show visualization of the learned features and analyze the model with experiments to verify our model's ability to model context.