 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUTO: Pathology-Universal Transformer
May 13, 2024



Pathology is the study of microscopic inspection of tissue, and a pathology diagnosis is often the medical gold standard to diagnose disease. Pathology images provide a unique challenge for computer-vision-based analysis: a single pathology Whole Slide Image (WSI) is gigapixel-sized and often contains hundreds of thousands to millions of objects of interest across multiple resolutions. In this work, we propose PathoLogy Universal TransfOrmer (PLUTO): a light-weight pathology FM that is pre-trained on a diverse dataset of 195 million image tiles collected from multiple sites and extracts meaningful representations across multiple WSI scales that enable a large variety of downstream pathology tasks. In particular, we design task-specific adaptation heads that utilize PLUTO's output embeddings for tasks which span pathology scales ranging from subcellular to slide-scale, including instance segmentation, tile classification, and slide-level prediction. We compare PLUTO's performance to other state-of-the-art methods on a diverse set of external and internal benchmarks covering multiple biologically relevant tasks, tissue types, resolutions, stains, and scanners. We find that PLUTO matches or outperforms existing task-specific baselines and pathology-specific foundation models, some of which use orders-of-magnitude larger datasets and model sizes when compared to PLUTO. Our findings present a path towards a universal embedding to power pathology image analysis, and motivate further exploration around pathology foundation models in terms of data diversity, architectural improvements, sample efficiency, and practical deployability in real-world applications.
SC-MIL: Supervised Contrastive Multiple Instance Learning for Imbalanced Classification in Pathology
Mar 23, 2023Multiple Instance learning (MIL) models have been extensively used in pathology to predict biomarkers and risk-stratify patients from gigapixel-sized images. Machine learning problems in medical imaging often deal with rare diseases, making it important for these models to work in a label-imbalanced setting. Furthermore, these imbalances can occur in out-of-distribution (OOD) datasets when the models are deployed in the real-world. We leverage the idea that decoupling feature and classifier learning can lead to improved decision boundaries for label imbalanced datasets. To this end, we investigate the integration of supervised contrastive learning with multiple instance learning (SC-MIL). Specifically, we propose a joint-training MIL framework in the presence of label imbalance that progressively transitions from learning bag-level representations to optimal classifier learning. We perform experiments with different imbalance settings for two well-studied problems in cancer pathology: subtyping of non-small cell lung cancer and subtyping of renal cell carcinoma. SC-MIL provides large and consistent improvements over other techniques on both in-distribution (ID) and OOD held-out sets across multiple imbalanced settings.
Additive MIL: Intrinsic Interpretability for Pathology
Jun 03, 2022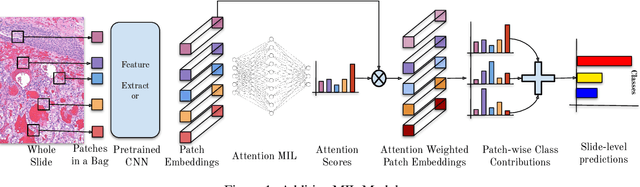
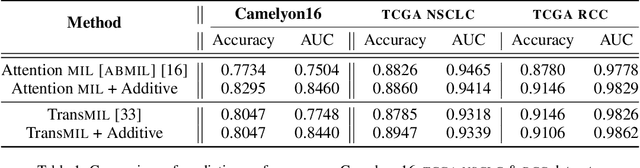
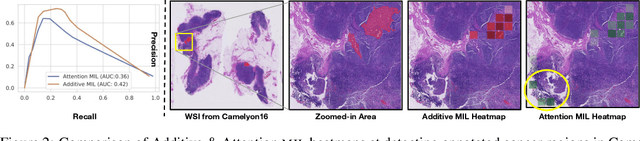

Multiple Instance Learning (MIL) has been widely applied in pathology towards solving critical problems such as automating cancer diagnosis and grading, predicting patient prognosis, and therapy response. Deploying these models in a clinical setting requires careful inspection of these black boxes during development and deployment to identify failures and maintain physician trust. In this work, we propose a simple formulation of MIL models, which enables interpretability while maintaining similar predictive performance. Our Additive MIL models enable spatial credit assignment such that the contribution of each region in the image can be exactly computed and visualized. We show that our spatial credit assignment coincides with regions used by pathologists during diagnosis and improves upon classical attention heatmaps from attention MIL models. We show that any existing MIL model can be made additive with a simple change in function composition. We also show how these models can debug model failures, identify spurious features, and highlight class-wise regions of interest, enabling their use in high-stakes environments such as clinical decision-making.
Rethinking Machine Learning Model Evaluation in Pathology
Apr 18, 2022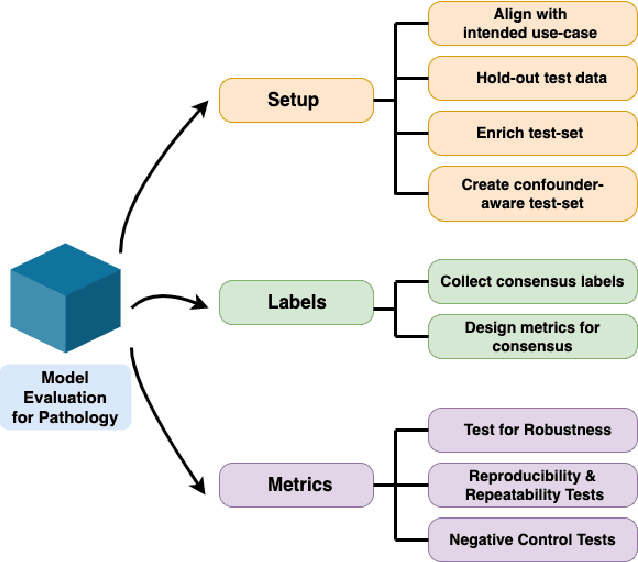
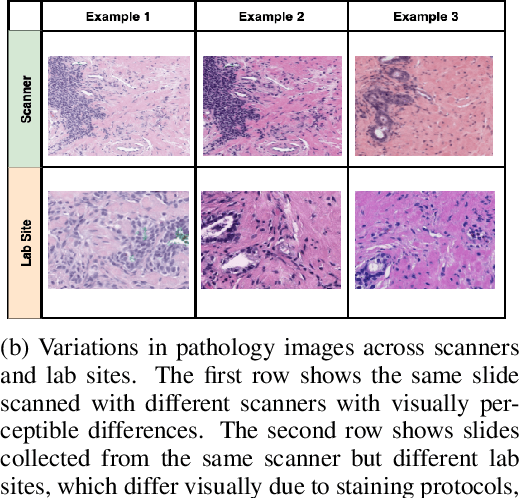
Machine Learning has been applied to pathology images in research and clinical practice with promising outcomes. However, standard ML models often lack the rigorous evaluation required for clinical decisions. Machine learning techniques for natural images are ill-equipped to deal with pathology images that are significantly large and noisy, require expensive labeling, are hard to interpret, and are susceptible to spurious correlations. We propose a set of practical guidelines for ML evaluation in pathology that address the above concerns. The paper includes measures for setting up the evaluation framework, effectively dealing with variability in labels, and a recommended suite of tests to address issues related to domain shift, robustness, and confounding variables. We hope that the proposed framework will bridge the gap between ML researchers and domain experts, leading to wider adoption of ML techniques in pathology and improving patient outcomes.
CineFilter: Unsupervised Filtering for Real Time Autonomous Camera Systems
Dec 11, 2019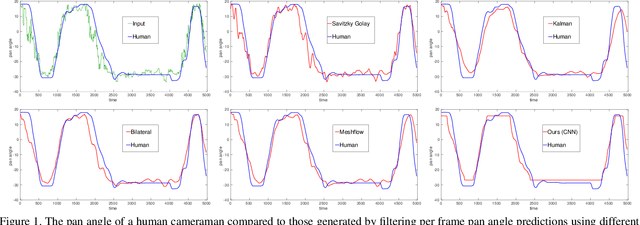
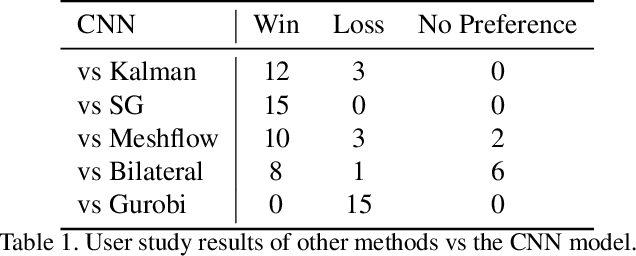
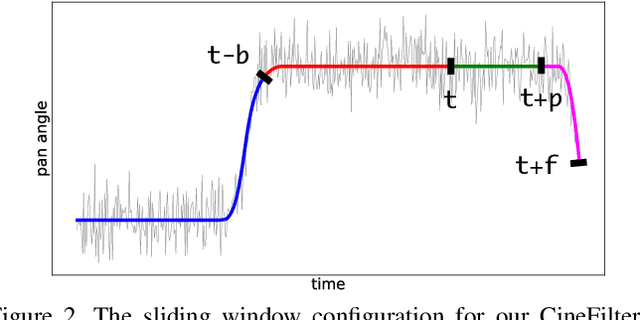
Learning to mimic the smooth and deliberate camera movement of a human cameraman is an essential requirement for autonomous camera systems. This paper presents a novel formulation for online and real-time estimation of smooth camera trajectories. Many works have focused on global optimization of the trajectory to produce an offline output. Some recent works have tried to extend this to the online setting, but lack either in the quality of the camera trajectories or need large labeled datasets to train their supervised model. We propose two models, one a convex optimization based approach and another a CNN based model, both of which can exploit the temporal trends in the camera behavior. Our model is built in an unsupervised way without any ground truth trajectories and is robust to noisy outliers. We evaluate our models on two different settings namely a basketball dataset and a stage performance dataset and compare against multiple baselines and past approaches. Our models outperform other methods on quantitative and qualitative metrics and produce smooth camera trajectories that are motivated by cinematographic principles. These models can also be easily adopted to run in real-time with a low computational cost, making them fit for a variety of applications.
Embodied Language Grounding with Implicit 3D Visual Feature Representations
Oct 02, 2019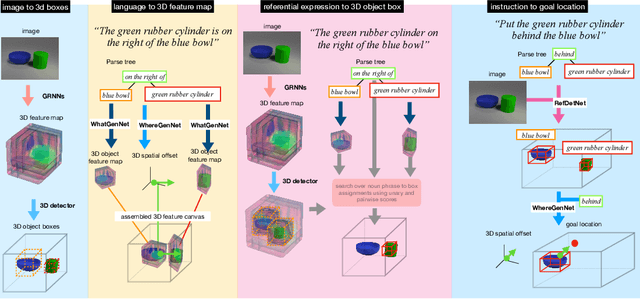



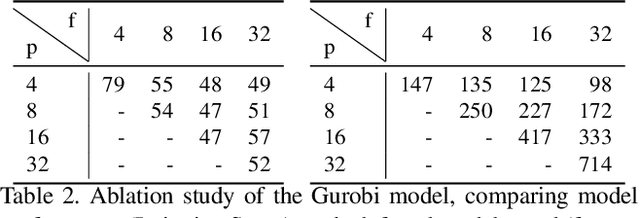
Consider the utterance "the tomato is to the left of the pot." Humans can answer numerous questions about the situation described, as well as reason through counterfactuals and alternatives, such as, "is the pot larger than the tomato ?", "can we move to a viewpoint from which the tomato is completely hidden behind the pot ?", "can we have an object that is both to the left of the tomato and to the right of the pot ?", "would the tomato fit inside the pot ?", and so on. Such reasoning capability remains elusive from current computational models of language understanding. To link language processing with spatial reasoning, we propose associating natural language utterances to a mental workspace of their meaning, encoded as 3-dimensional visual feature representations of the world scenes they describe. We learn such 3-dimensional visual representations---we call them visual imaginations--- by predicting images a mobile agent sees while moving around in the 3D world. The input image streams the agent collects are unprojected into egomotion-stable 3D scene feature maps of the scene, and projected from novel viewpoints to match the observed RGB image views in an end-to-end differentiable manner. We then train modular neural models to generate such 3D feature representations given language utterances, to localize the objects an utterance mentions in the 3D feature representation inferred from an image, and to predict the desired 3D object locations given a manipulation instruction. We empirically show the proposed models outperform by a large margin existing 2D models in spatial reasoning, referential object detection and instruction following, and generalize better across camera viewpoints and object arrangements.
Learning Unsupervised Visual Grounding Through Semantic Self-Supervision
Sep 05, 2018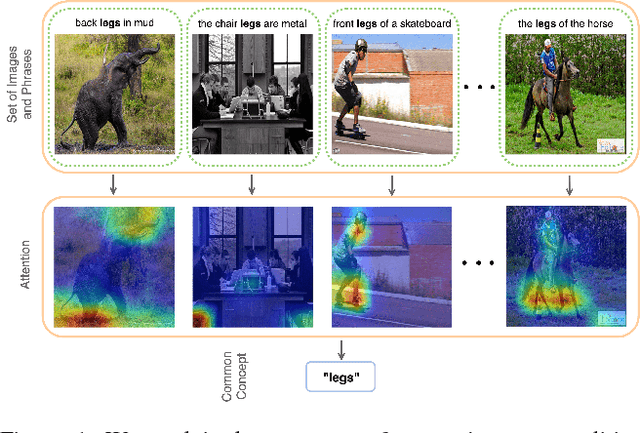
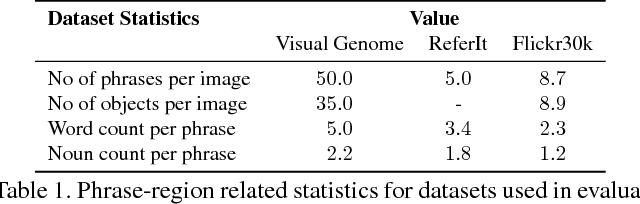
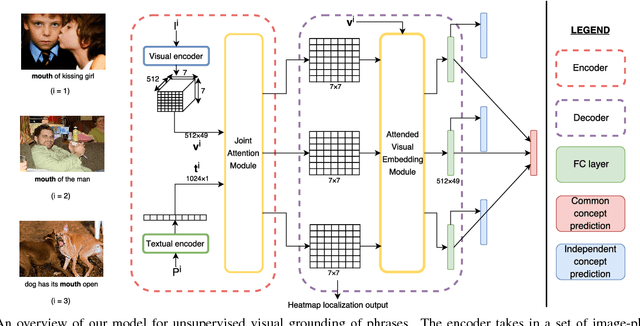
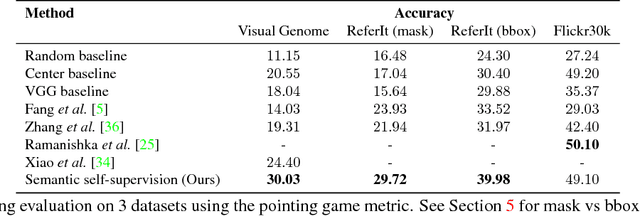
Localizing natural language phrases in images is a challenging problem that requires joint understanding of both the textual and visual modalities. In the unsupervised setting, lack of supervisory signals exacerbate this difficulty. In this paper, we propose a novel framework for unsupervised visual grounding which uses concept learning as a proxy task to obtain self-supervision. The simple intuition behind this idea is to encourage the model to localize to regions which can explain some semantic property in the data, in our case, the property being the presence of a concept in a set of images. We present thorough quantitative and qualitative experiments to demonstrate the efficacy of our approach and show a 5.6% improvement over the current state of the art on Visual Genome dataset, a 5.8% improvement on the ReferItGame dataset and comparable to state-of-art performance on the Flickr30k dataset.
MergeNet: A Deep Net Architecture for Small Obstacle Discovery
Mar 17, 2018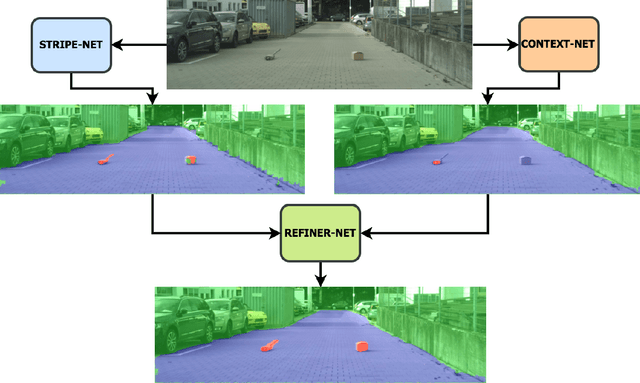
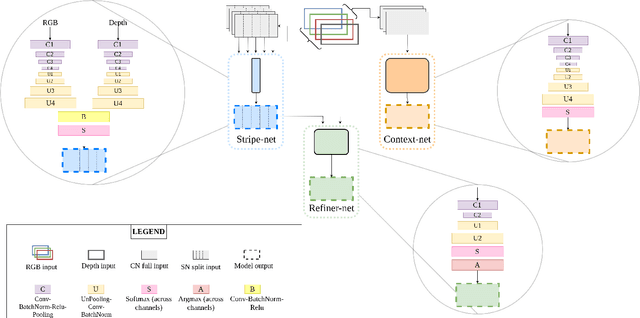
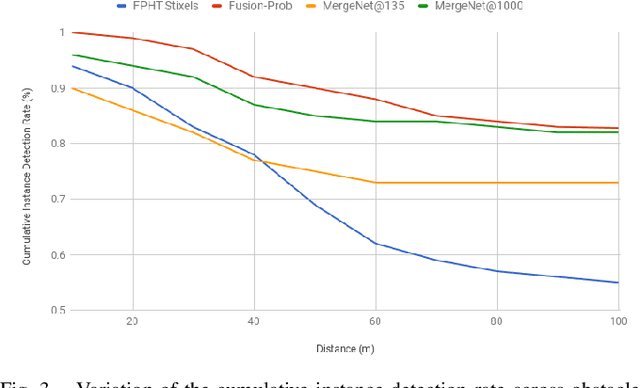

We present here, a novel network architecture called MergeNet for discovering small obstacles for on-road scenes in the context of autonomous driving. The basis of the architecture rests on the central consideration of training with less amount of data since the physical setup and the annotation process for small obstacles is hard to scale. For making effective use of the limited data, we propose a multi-stage training procedure involving weight-sharing, separate learning of low and high level features from the RGBD input and a refining stage which learns to fuse the obtained complementary features. The model is trained and evaluated on the Lost and Found dataset and is able to achieve state-of-art results with just 135 images in comparison to the 1000 images used by the previous benchmark. Additionally, we also compare our results with recent methods trained on 6000 images and show that our method achieves comparable performance with only 1000 training samples.
Object-Level Context Modeling For Scene Classification with Context-CNN
Jun 02, 2017
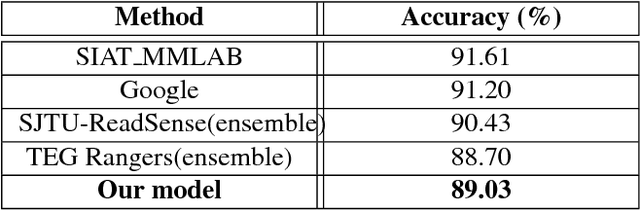
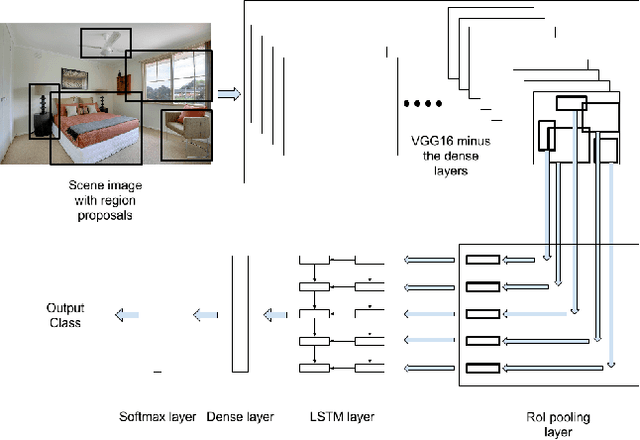
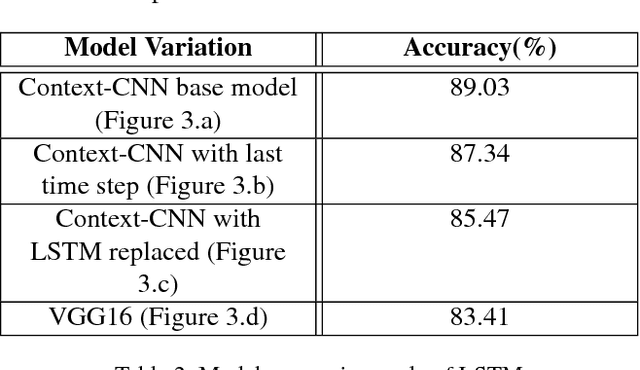
Convolutional Neural Networks (CNNs) have been used extensively for computer vision tasks and produce rich feature representation for objects or parts of an image. But reasoning about scenes requires integration between the low-level feature representations and the high-level semantic information. We propose a deep network architecture which models the semantic context of scenes by capturing object-level information. We use Long Short Term Memory(LSTM) units in conjunction with object proposals to incorporate object-object relationship and object-scene relationship in an end-to-end trainable manner. We evaluate our model on the LSUN dataset and achieve results comparable to the state-of-art. We further show visualization of the learned features and analyze the model with experiments to verify our model's ability to model context.