 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Machine Learning Model Evaluation in Pathology
Paper and Code
Apr 18, 2022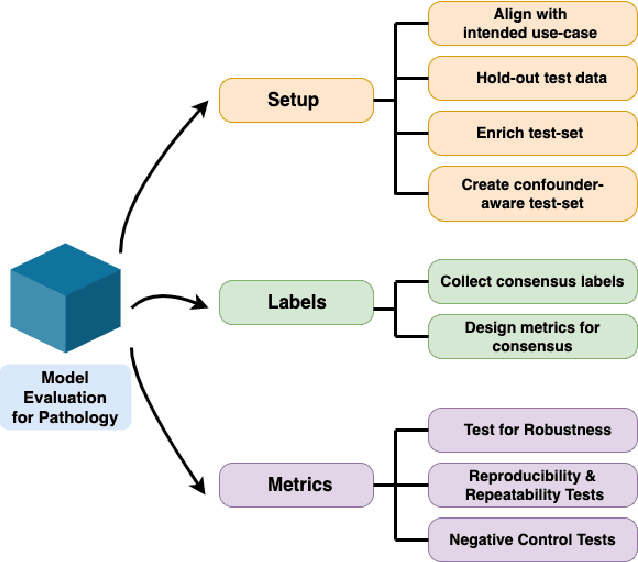
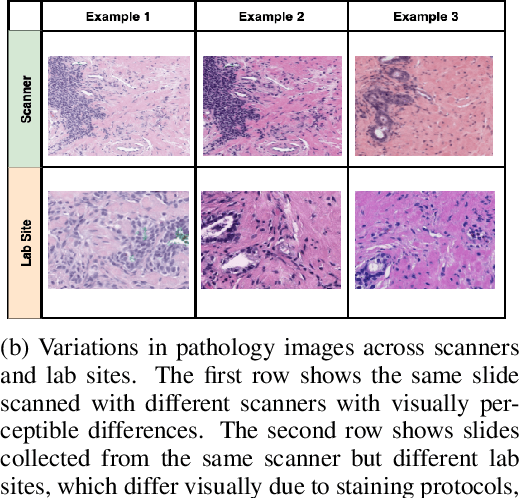
Machine Learning has been applied to pathology images in research and clinical practice with promising outcomes. However, standard ML models often lack the rigorous evaluation required for clinical decisions. Machine learning techniques for natural images are ill-equipped to deal with pathology images that are significantly large and noisy, require expensive labeling, are hard to interpret, and are susceptible to spurious correlations. We propose a set of practical guidelines for ML evaluation in pathology that address the above concerns. The paper includes measures for setting up the evaluation framework, effectively dealing with variability in labels, and a recommended suite of tests to address issues related to domain shift, robustness, and confounding variables. We hope that the proposed framework will bridge the gap between ML researchers and domain experts, leading to wider adoption of ML techniques in pathology and improving patient outcomes.