 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMergeNet: A Deep Net Architecture for Small Obstacle Discovery
Mar 17, 2018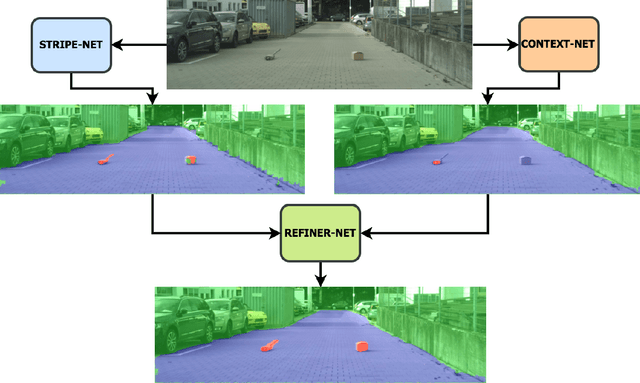
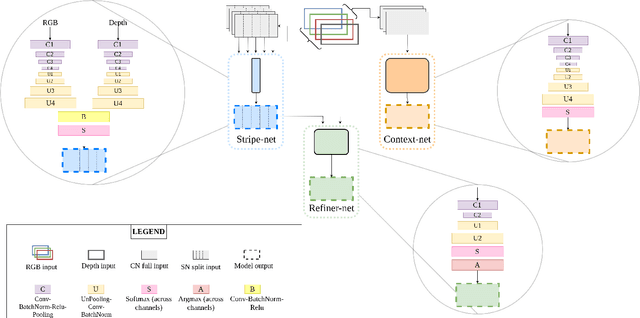
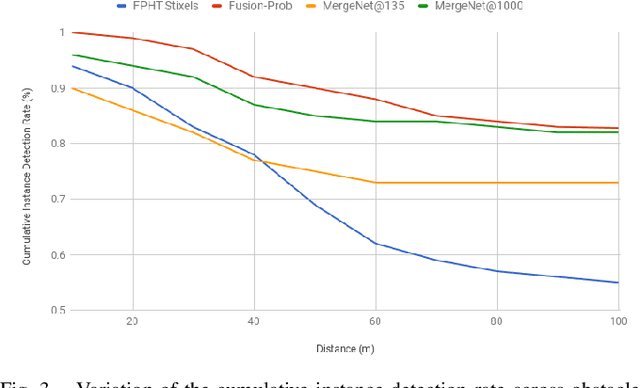

We present here, a novel network architecture called MergeNet for discovering small obstacles for on-road scenes in the context of autonomous driving. The basis of the architecture rests on the central consideration of training with less amount of data since the physical setup and the annotation process for small obstacles is hard to scale. For making effective use of the limited data, we propose a multi-stage training procedure involving weight-sharing, separate learning of low and high level features from the RGBD input and a refining stage which learns to fuse the obtained complementary features. The model is trained and evaluated on the Lost and Found dataset and is able to achieve state-of-art results with just 135 images in comparison to the 1000 images used by the previous benchmark. Additionally, we also compare our results with recent methods trained on 6000 images and show that our method achieves comparable performance with only 1000 training samples.