 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect, Label, Evaluate: Active Testing in NLP
Mar 23, 2026Human annotation cost and time remain significant bottlenecks in Natural Language Processing (NLP), with test data annotation being particularly expensive due to the stringent requirement for low-error and high-quality labels necessary for reliable model evaluation. Traditional approaches require annotating entire test sets, leading to substantial resource requirements. Active Testing is a framework that selects the most informative test samples for annotation. Given a labeling budget, it aims to choose the subset that best estimates model performance while minimizing cost and human effort. In this work, we formalize Active Testing in NLP and we conduct an extensive benchmarking of existing approaches across 18 datasets and 4 embedding strategies spanning 4 different NLP tasks. The experiments show annotation reductions of up to 95%, with performance estimation accuracy difference from the full test set within 1%. Our analysis reveals variations in method effectiveness across different data characteristics and task types, with no single approach emerging as universally superior. Lastly, to address the limitation of requiring a predefined annotation budget in existing sample selection strategies, we introduce an adaptive stopping criterion that automatically determines the optimal number of samples.
Monte Carlo Temperature: a robust sampling strategy for LLM's uncertainty quantification methods
Feb 25, 2025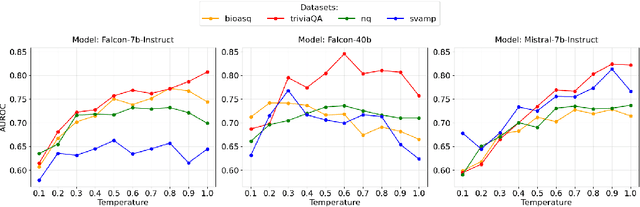
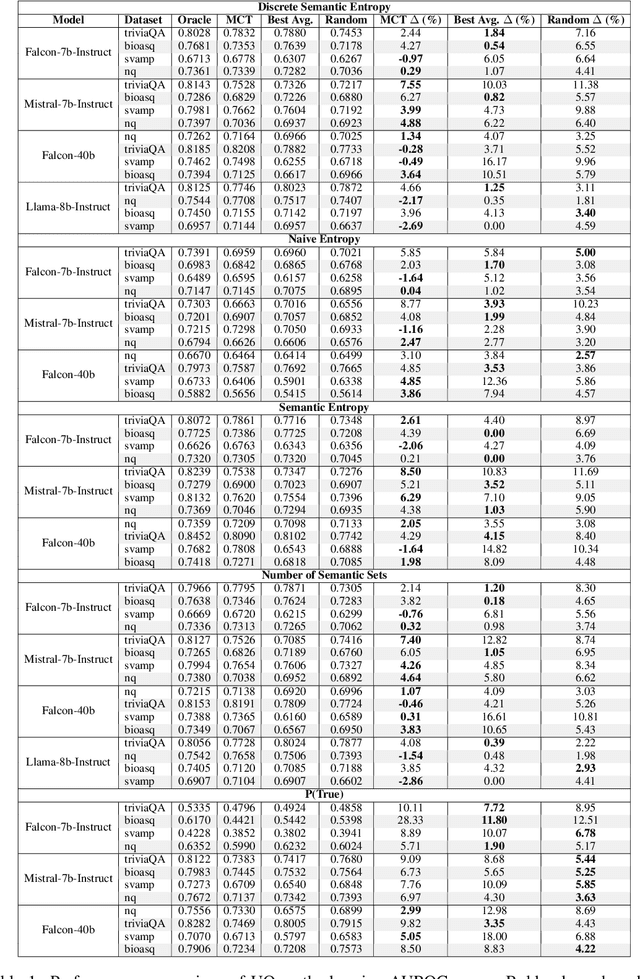
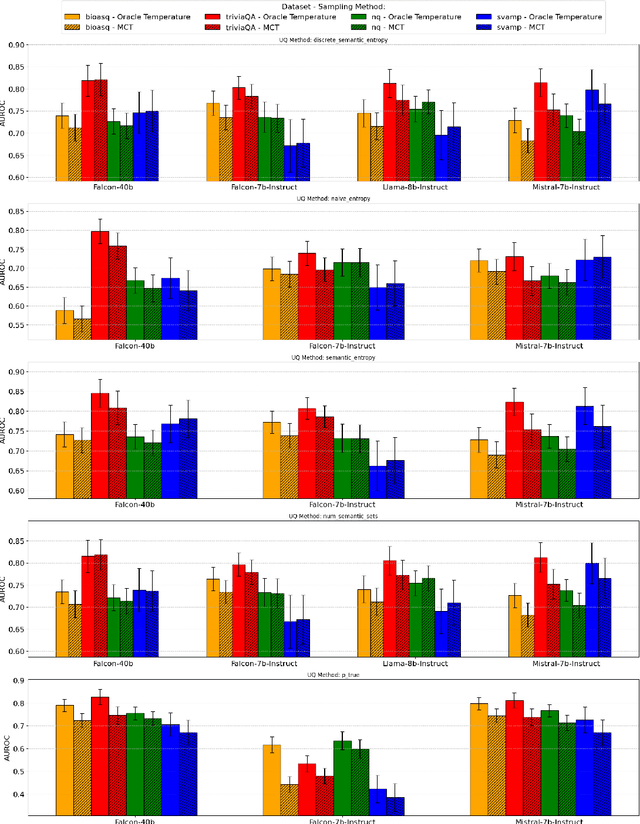
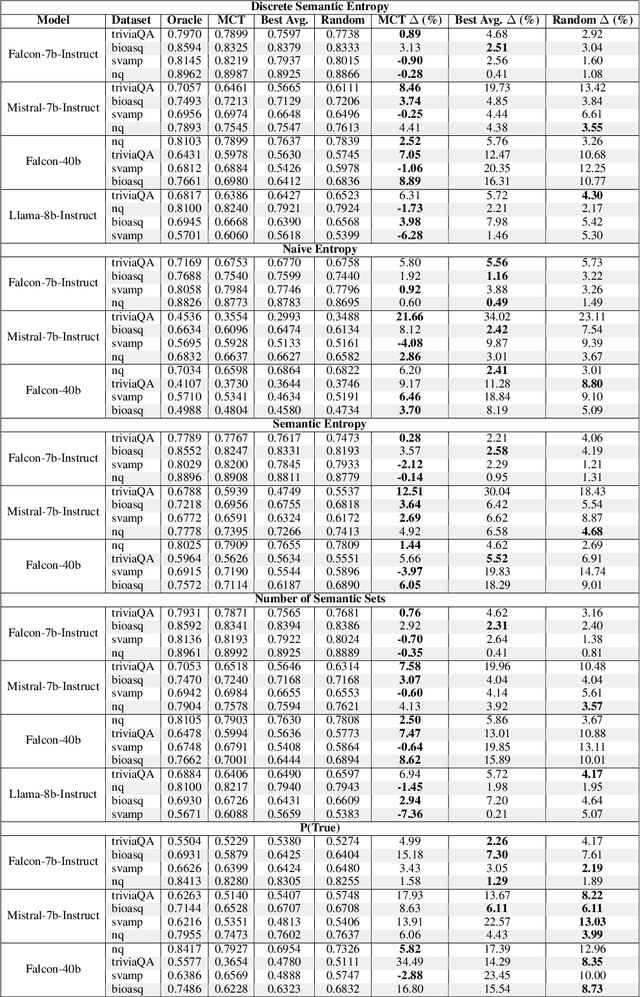
Uncertainty quantification (UQ) in Large Language Models (LLMs) is essential for their safe and reliable deployment, particularly in critical applications where incorrect outputs can have serious consequences. Current UQ methods typically rely on querying the model multiple times using non-zero temperature sampling to generate diverse outputs for uncertainty estimation. However, the impact of selecting a given temperature parameter is understudied, and our analysis reveals that temperature plays a fundamental role in the quality of uncertainty estimates. The conventional approach of identifying optimal temperature values requires expensive hyperparameter optimization (HPO) that must be repeated for each new model-dataset combination. We propose Monte Carlo Temperature (MCT), a robust sampling strategy that eliminates the need for temperature calibration. Our analysis reveals that: 1) MCT provides more robust uncertainty estimates across a wide range of temperatures, 2) MCT improves the performance of UQ methods by replacing fixed-temperature strategies that do not rely on HPO, and 3) MCT achieves statistical parity with oracle temperatures, which represent the ideal outcome of a well-tuned but computationally expensive HPO process. These findings demonstrate that effective UQ can be achieved without the computational burden of temperature parameter calibration.
The Majority Vote Paradigm Shift: When Popular Meets Optimal
Feb 19, 2025



Reliably labelling data typically requires annotations from multiple human workers. However, humans are far from being perfect. Hence, it is a common practice to aggregate labels gathered from multiple annotators to make a more confident estimate of the true label. Among many aggregation methods, the simple and well known Majority Vote (MV) selects the class label polling the highest number of votes. However, despite its importance, the optimality of MV's label aggregation has not been extensively studied. We address this gap in our work by characterising the conditions under which MV achieves the theoretically optimal lower bound on label estimation error. Our results capture the tolerable limits on annotation noise under which MV can optimally recover labels for a given class distribution. This certificate of optimality provides a more principled approach to model selection for label aggregation as an alternative to otherwise inefficient practices that sometimes include higher experts, gold labels, etc., that are all marred by the same human uncertainty despite huge time and monetary costs. Experiments on both synthetic and real world data corroborate our theoretical findings.
STLight: a Fully Convolutional Approach for Efficient Predictive Learning by Spatio-Temporal joint Processing
Nov 15, 2024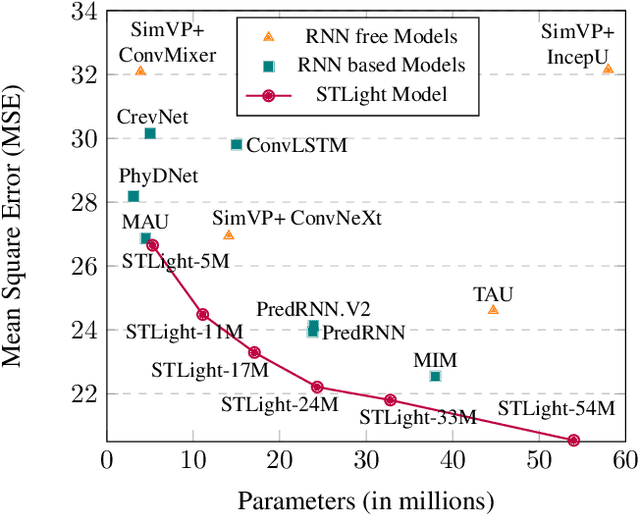

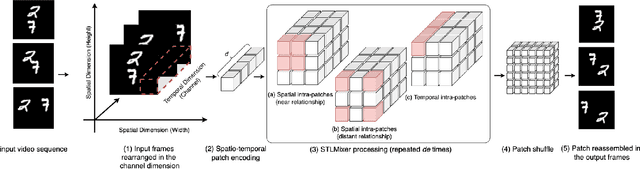

Spatio-Temporal predictive Learning is a self-supervised learning paradigm that enables models to identify spatial and temporal patterns by predicting future frames based on past frames. Traditional methods, which use recurrent neural networks to capture temporal patterns, have proven their effectiveness but come with high system complexity and computational demand. Convolutions could offer a more efficient alternative but are limited by their characteristic of treating all previous frames equally, resulting in poor temporal characterization, and by their local receptive field, limiting the capacity to capture distant correlations among frames. In this paper, we propose STLight, a novel method for spatio-temporal learning that relies solely on channel-wise and depth-wise convolutions as learnable layers. STLight overcomes the limitations of traditional convolutional approaches by rearranging spatial and temporal dimensions together, using a single convolution to mix both types of features into a comprehensive spatio-temporal patch representation. This representation is then processed in a purely convolutional framework, capable of focusing simultaneously on the interaction among near and distant patches, and subsequently allowing for efficient reconstruction of the predicted frames. Our architecture achieves state-of-the-art performance on STL benchmarks across different datasets and settings, while significantly improving computational efficiency in terms of parameters and computational FLOPs. The code is publicly available
A Reproducible Analysis of Sequential Recommender Systems
Aug 07, 2024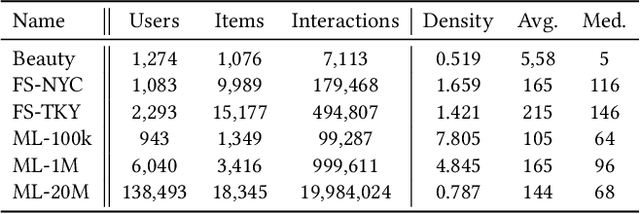
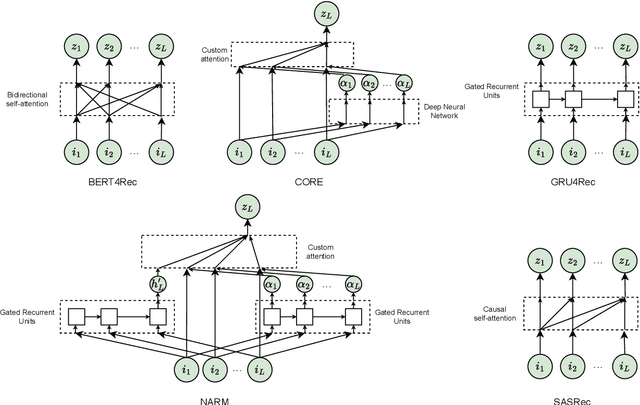

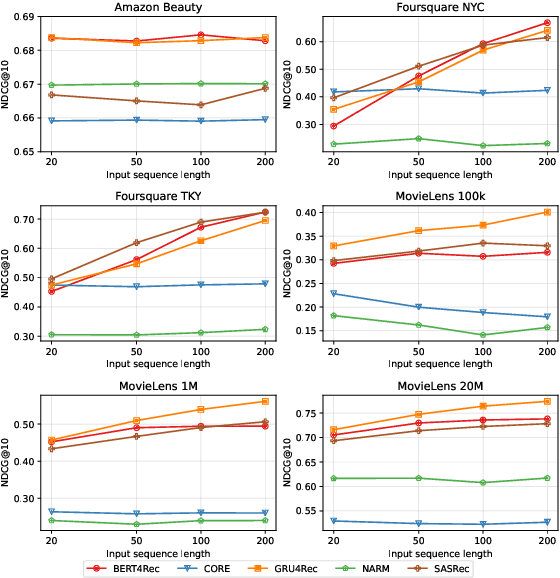
Sequential Recommender Systems (SRSs) have emerged as a highly efficient approach to recommendation systems. By leveraging sequential data, SRSs can identify temporal patterns in user behaviour, significantly improving recommendation accuracy and relevance.Ensuring the reproducibility of these models is paramount for advancing research and facilitating comparisons between them. Existing works exhibit shortcomings in reproducibility and replicability of results, leading to inconsistent statements across papers. Our work fills these gaps by standardising data pre-processing and model implementations, providing a comprehensive code resource, including a framework for developing SRSs and establishing a foundation for consistent and reproducible experimentation. We conduct extensive experiments on several benchmark datasets, comparing various SRSs implemented in our resource. We challenge prevailing performance benchmarks, offering new insights into the SR domain. For instance, SASRec does not consistently outperform GRU4Rec. On the contrary, when the number of model parameters becomes substantial, SASRec starts to clearly dominate all the other SRSs. This discrepancy underscores the significant impact that experimental configuration has on the outcomes and the importance of setting it up to ensure precise and comprehensive results. Failure to do so can lead to significantly flawed conclusions, highlighting the need for rigorous experimental design and analysis in SRS research. Our code is available at https://github.com/antoniopurificato/recsys_repro_conf.
Handling Ontology Gaps in Semantic Parsing
Jun 27, 2024



The majority of Neural Semantic Parsing (NSP) models are developed with the assumption that there are no concepts outside the ones such models can represent with their target symbols (closed-world assumption). This assumption leads to generate hallucinated outputs rather than admitting their lack of knowledge. Hallucinations can lead to wrong or potentially offensive responses to users. Hence, a mechanism to prevent this behavior is crucial to build trusted NSP-based Question Answering agents. To that end, we propose the Hallucination Simulation Framework (HSF), a general setting for stimulating and analyzing NSP model hallucinations. The framework can be applied to any NSP task with a closed-ontology. Using the proposed framework and KQA Pro as the benchmark dataset, we assess state-of-the-art techniques for hallucination detection. We then present a novel hallucination detection strategy that exploits the computational graph of the NSP model to detect the NSP hallucinations in the presence of ontology gaps, out-of-domain utterances, and to recognize NSP errors, improving the F1-Score respectively by ~21, ~24% and ~1%. This is the first work in closed-ontology NSP that addresses the problem of recognizing ontology gaps. We release our code and checkpoints at https://github.com/amazon-science/handling-ontology-gaps-in-semantic-parsing.
Generating Query Recommendations via LLMs
Jun 04, 2024Query recommendation systems are ubiquitous in modern search engines, assisting users in producing effective queries to meet their information needs. However, these systems require a large amount of data to produce good recommendations, such as a large collection of documents to index and query logs. In particular, query logs and user data are not available in cold start scenarios. Query logs are expensive to collect and maintain and require complex and time-consuming cascading pipelines for creating, combining, and ranking recommendations. To address these issues, we frame the query recommendation problem as a generative task, proposing a novel approach called Generative Query Recommendation (GQR). GQR uses an LLM as its foundation and does not require to be trained or fine-tuned to tackle the query recommendation problem. We design a prompt that enables the LLM to understand the specific recommendation task, even using a single example. We then improved our system by proposing a version that exploits query logs called Retriever-Augmented GQR (RA-GQR). RA-GQr dynamically composes its prompt by retrieving similar queries from query logs. GQR approaches reuses a pre-existing neural architecture resulting in a simpler and more ready-to-market approach, even in a cold start scenario. Our proposed GQR obtains state-of-the-art performance in terms of NDCG@10 and clarity score against two commercial search engines and the previous state-of-the-art approach on the Robust04 and ClueWeb09B collections, improving on average the NDCG@10 performance up to ~4% on Robust04 and ClueWeb09B w.r.t the previous best competitor. RA-GQR further improve the NDCG@10 obtaining an increase of ~11%, ~6\% on Robust04 and ClueWeb09B w.r.t the best competitor. Furthermore, our system obtained ~59% of user preferences in a blind user study, proving that our method produces the most engaging queries.
RRAML: Reinforced Retrieval Augmented Machine Learning
Jul 27, 2023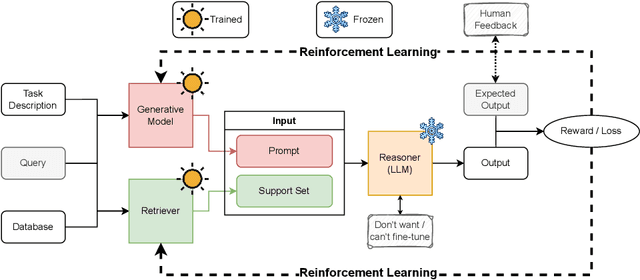
The emergence of large language models (LLMs) has revolutionized machine learning and related fields, showcasing remarkable abilities in comprehending, generating, and manipulating human language. However, their conventional usage through API-based text prompt submissions imposes certain limitations in terms of context constraints and external source availability. To address these challenges, we propose a novel framework called Reinforced Retrieval Augmented Machine Learning (RRAML). RRAML integrates the reasoning capabilities of LLMs with supporting information retrieved by a purpose-built retriever from a vast user-provided database. By leveraging recent advancements in reinforcement learning, our method effectively addresses several critical challenges. Firstly, it circumvents the need for accessing LLM gradients. Secondly, our method alleviates the burden of retraining LLMs for specific tasks, as it is often impractical or impossible due to restricted access to the model and the computational intensity involved. Additionally we seamlessly link the retriever's task with the reasoner, mitigating hallucinations and reducing irrelevant, and potentially damaging retrieved documents. We believe that the research agenda outlined in this paper has the potential to profoundly impact the field of AI, democratizing access to and utilization of LLMs for a wide range of entities.
Fauno: The Italian Large Language Model that will leave you senza parole!
Jun 26, 2023
This paper presents Fauno, the first and largest open-source Italian conversational Large Language Model (LLM). Our goal with Fauno is to democratize the study of LLMs in Italian, demonstrating that obtaining a fine-tuned conversational bot with a single GPU is possible. In addition, we release a collection of datasets for conversational AI in Italian. The datasets on which we fine-tuned Fauno include various topics such as general question answering, computer science, and medical questions. We release our code and datasets on \url{https://github.com/RSTLess-research/Fauno-Italian-LLM}
Renormalized Graph Neural Networks
Jun 01, 2023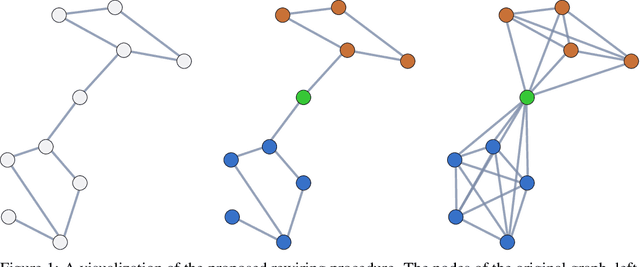
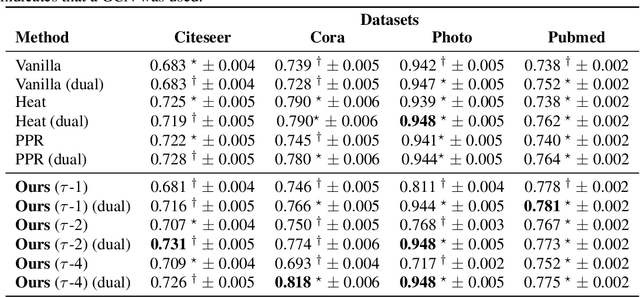
Graph Neural Networks (GNNs) have become essential for studying complex data, particularly when represented as graphs. Their value is underpinned by their ability to reflect the intricacies of numerous areas, ranging from social to biological networks. GNNs can grapple with non-linear behaviors, emerging patterns, and complex connections; these are also typical characteristics of complex systems. The renormalization group (RG) theory has emerged as the language for studying complex systems. It is recognized as the preferred lens through which to study complex systems, offering a framework that can untangle their intricate dynamics. Despite the clear benefits of integrating RG theory with GNNs, no existing methods have ventured into this promising territory. This paper proposes a new approach that applies RG theory to devise a novel graph rewiring to improve GNNs' performance on graph-related tasks. We support our proposal with extensive experiments on standard benchmarks and baselines. The results demonstrate the effectiveness of our method and its potential to remedy the current limitations of GNNs. Finally, this paper marks the beginning of a new research direction. This path combines the theoretical foundations of RG, the magnifying glass of complex systems, with the structural capabilities of GNNs. By doing so, we aim to enhance the potential of GNNs in modeling and unraveling the complexities inherent in diverse systems.