 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident Rankings with Fewer Items: Adaptive LLM Evaluation with Continuous Scores
Jan 20, 2026Computerized Adaptive Testing (CAT) has proven effective for efficient LLM evaluation on multiple-choice benchmarks, but modern LLM evaluation increasingly relies on generation tasks where outputs are scored continuously rather than marked correct/incorrect. We present a principled extension of IRT-based adaptive testing to continuous bounded scores (ROUGE, BLEU, LLM-as-a-Judge) by replacing the Bernoulli response distribution with a heteroskedastic normal distribution. Building on this, we introduce an uncertainty aware ranker with adaptive stopping criteria that achieves reliable model ranking while testing as few items and as cheaply as possible. We validate our method on five benchmarks spanning n-gram-based, embedding-based, and LLM-as-judge metrics. Our method uses 2% of the items while improving ranking correlation by 0.12 τ over random sampling, with 95% accuracy on confident predictions.
Handling Ontology Gaps in Semantic Parsing
Jun 27, 2024



The majority of Neural Semantic Parsing (NSP) models are developed with the assumption that there are no concepts outside the ones such models can represent with their target symbols (closed-world assumption). This assumption leads to generate hallucinated outputs rather than admitting their lack of knowledge. Hallucinations can lead to wrong or potentially offensive responses to users. Hence, a mechanism to prevent this behavior is crucial to build trusted NSP-based Question Answering agents. To that end, we propose the Hallucination Simulation Framework (HSF), a general setting for stimulating and analyzing NSP model hallucinations. The framework can be applied to any NSP task with a closed-ontology. Using the proposed framework and KQA Pro as the benchmark dataset, we assess state-of-the-art techniques for hallucination detection. We then present a novel hallucination detection strategy that exploits the computational graph of the NSP model to detect the NSP hallucinations in the presence of ontology gaps, out-of-domain utterances, and to recognize NSP errors, improving the F1-Score respectively by ~21, ~24% and ~1%. This is the first work in closed-ontology NSP that addresses the problem of recognizing ontology gaps. We release our code and checkpoints at https://github.com/amazon-science/handling-ontology-gaps-in-semantic-parsing.
LUQ: Long-text Uncertainty Quantification for LLMs
Mar 29, 2024Large Language Models (LLMs) have demonstrated remarkable capability in a variety of NLP tasks. Despite their effectiveness, these models are prone to generate nonfactual content. Uncertainty Quantification (UQ) is pivotal in enhancing our understanding of a model's confidence in its generated content, thereby aiding in the mitigation of nonfactual outputs. Existing research on UQ predominantly targets short text generation, typically yielding brief, word-limited responses. However, real-world applications frequently necessitate much longer responses. Our study first highlights the limitations of current UQ methods in handling long text generation. We then introduce \textsc{Luq}, a novel sampling-based UQ approach specifically designed for long text. Our findings reveal that \textsc{Luq} outperforms existing baseline methods in correlating with the model's factuality scores (negative coefficient of -0.85 observed for Gemini Pro). With \textsc{Luq} as the tool for UQ, we investigate behavior patterns of several popular LLMs' response confidence spectrum and how that interplays with the response' factuality. We identify that LLMs lack confidence in generating long text for rare facts and a factually strong model (i.e. GPT-4) tends to reject questions it is not sure about. To further improve the factual accuracy of LLM responses, we propose a method called \textsc{Luq-Ensemble} that ensembles responses from multiple models and selects the response with the least uncertainty. The ensembling method greatly improves the response factuality upon the best standalone LLM.
Self-alignment Pre-training for Biomedical Entity Representations
Oct 22, 2020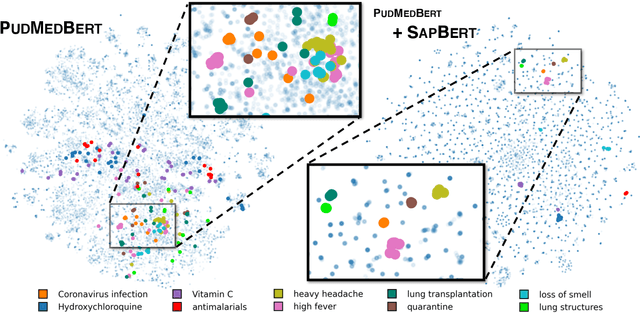

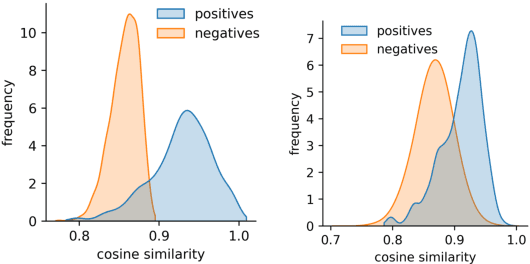
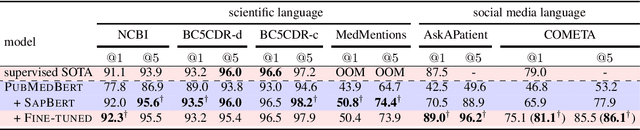
Despite the widespread success of self-supervised learning via masked language models, learning representations directly from text to accurately capture complex and fine-grained semantic relationships in the biomedical domain remains as a challenge. Addressing this is of paramount importance for tasks such as entity linking where complex relational knowledge is pivotal. We propose SapBERT, a pre-training scheme based on BERT. It self-aligns the representation space of biomedical entities with a metric learning objective function leveraging UMLS, a collection of biomedical ontologies with >4M concepts. Our experimental results on six medical entity linking benchmarking datasets demonstrate that SapBERT outperforms many domain-specific BERT-based variants such as BioBERT, BlueBERT and PubMedBERT, achieving the state-of-the-art (SOTA) performances.
COMETA: A Corpus for Medical Entity Linking in the Social Media
Oct 08, 2020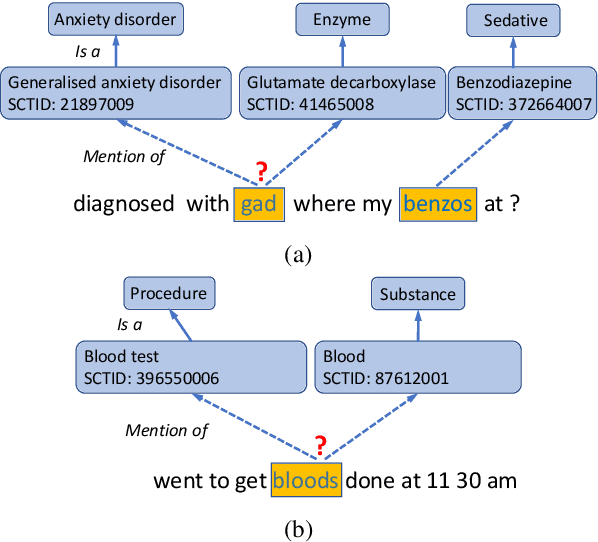

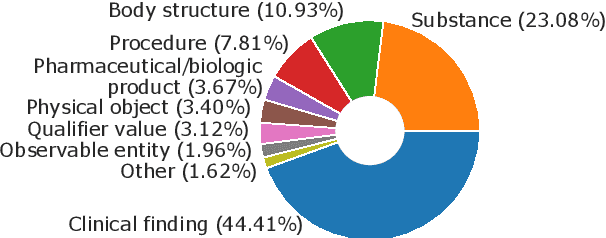
Whilst there has been growing progress in Entity Linking (EL) for general language, existing datasets fail to address the complex nature of health terminology in layman's language. Meanwhile, there is a growing need for applications that can understand the public's voice in the health domain. To address this we introduce a new corpus called COMETA, consisting of 20k English biomedical entity mentions from Reddit expert-annotated with links to SNOMED CT, a widely-used medical knowledge graph. Our corpus satisfies a combination of desirable properties, from scale and coverage to diversity and quality, that to the best of our knowledge has not been met by any of the existing resources in the field. Through benchmark experiments on 20 EL baselines from string- to neural-based models we shed light on the ability of these systems to perform complex inference on entities and concepts under 2 challenging evaluation scenarios. Our experimental results on COMETA illustrate that no golden bullet exists and even the best mainstream techniques still have a significant performance gap to fill, while the best solution relies on combining different views of data.
Natural language processing for achieving sustainable development: the case of neural labelling to enhance community profiling
Apr 27, 2020
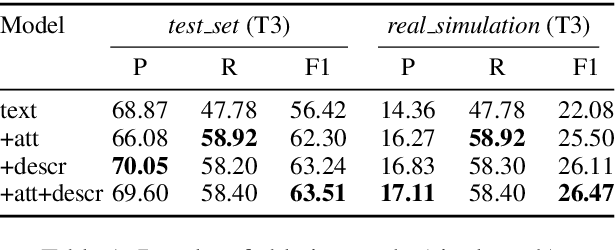

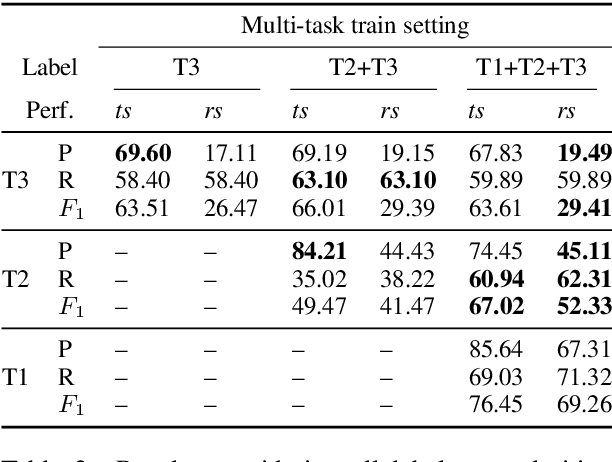
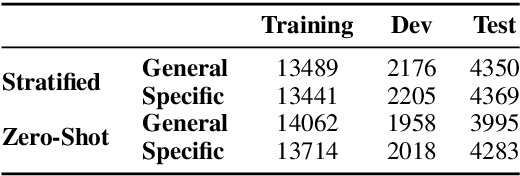
In recent years, there has been an increasing interest in the application of Artificial Intelligence - and especially Machine Learning - to the field of Sustainable Development (SD). However, until now, NLP has not been applied in this context. In this research paper, we show the high potential of NLP applications to enhance the sustainability of projects. In particular, we focus on the case of community profiling in developing countries, where, in contrast to the developed world, a notable data gap exists. In this context, NLP could help to address the cost and time barrier of structuring qualitative data that prohibits its widespread use and associated benefits. We propose the new task of Automatic UPV classification, which is an extreme multi-class multi-label classification problem. We release Stories2Insights, an expert-annotated dataset, provide a detailed corpus analysis, and implement a number of strong neural baselines to address the task. Experimental results show that the problem is challenging, and leave plenty of room for future research at the intersection of NLP and SD.