 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Representative Corpora from Illiterate Communities: A Review of Challenges and Mitigation Strategies for Developing Countries
Feb 04, 2021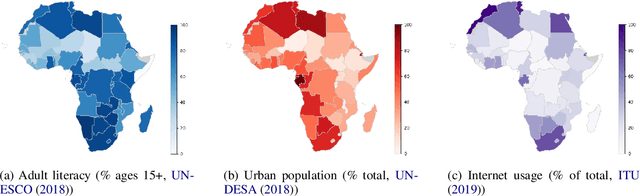


Most well-established data collection methods currently adopted in NLP depend on the assumption of speaker literacy. Consequently, the collected corpora largely fail to represent swathes of the global population, which tend to be some of the most vulnerable and marginalised people in society, and often live in rural developing areas. Such underrepresented groups are thus not only ignored when making modeling and system design decisions, but also prevented from benefiting from development outcomes achieved through data-driven NLP. This paper aims to address the under-representation of illiterate communities in NLP corpora: we identify potential biases and ethical issues that might arise when collecting data from rural communities with high illiteracy rates in Low-Income Countries, and propose a set of practical mitigation strategies to help future work.
Natural language processing for achieving sustainable development: the case of neural labelling to enhance community profiling
Apr 27, 2020
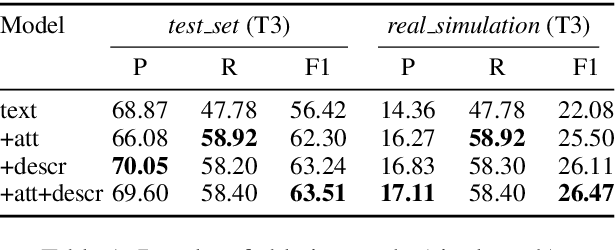

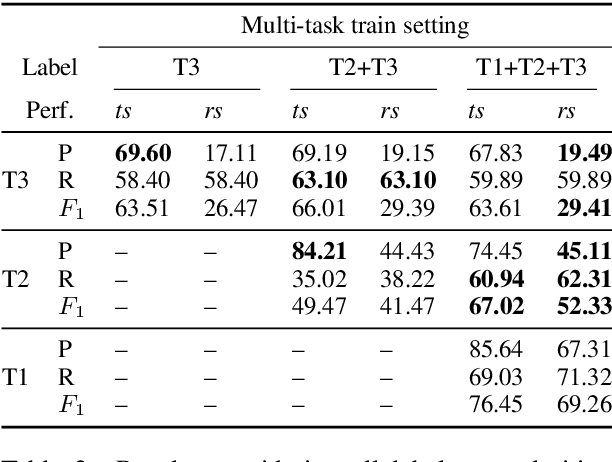
In recent years, there has been an increasing interest in the application of Artificial Intelligence - and especially Machine Learning - to the field of Sustainable Development (SD). However, until now, NLP has not been applied in this context. In this research paper, we show the high potential of NLP applications to enhance the sustainability of projects. In particular, we focus on the case of community profiling in developing countries, where, in contrast to the developed world, a notable data gap exists. In this context, NLP could help to address the cost and time barrier of structuring qualitative data that prohibits its widespread use and associated benefits. We propose the new task of Automatic UPV classification, which is an extreme multi-class multi-label classification problem. We release Stories2Insights, an expert-annotated dataset, provide a detailed corpus analysis, and implement a number of strong neural baselines to address the task. Experimental results show that the problem is challenging, and leave plenty of room for future research at the intersection of NLP and SD.