 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Representative Corpora from Illiterate Communities: A Review of Challenges and Mitigation Strategies for Developing Countries
Paper and Code
Feb 04, 2021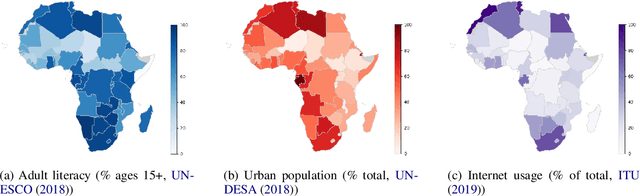


Most well-established data collection methods currently adopted in NLP depend on the assumption of speaker literacy. Consequently, the collected corpora largely fail to represent swathes of the global population, which tend to be some of the most vulnerable and marginalised people in society, and often live in rural developing areas. Such underrepresented groups are thus not only ignored when making modeling and system design decisions, but also prevented from benefiting from development outcomes achieved through data-driven NLP. This paper aims to address the under-representation of illiterate communities in NLP corpora: we identify potential biases and ethical issues that might arise when collecting data from rural communities with high illiteracy rates in Low-Income Countries, and propose a set of practical mitigation strategies to help future work.