 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Drafting Police Reports from Noisy ASR Outputs: A Trust-Centered LLM Approach
Feb 12, 2025Achieving a delicate balance between fostering trust in law en- forcement and protecting the rights of both officers and civilians continues to emerge as a pressing research and product challenge in the world today. In the pursuit of fairness and transparency, this study presents an innovative AI-driven system designed to generate police report drafts from complex, noisy, and multi-role dialogue data. Our approach intelligently extracts key elements of law enforcement interactions and includes them in the draft, producing structured narratives that are not only high in quality but also reinforce accountability and procedural clarity. This frame- work holds the potential to transform the reporting process, ensur- ing greater oversight, consistency, and fairness in future policing practices. A demonstration video of our system can be accessed at https://drive.google.com/file/d/1kBrsGGR8e3B5xPSblrchRGj-Y-kpCHNO/view?usp=sharing
DHP Benchmark: Are LLMs Good NLG Evaluators?
Aug 25, 2024Large Language Models (LLMs) are increasingly serving as evaluators in Natural Language Generation (NLG) tasks. However, the capabilities of LLMs in scoring NLG quality remain inadequately explored. Current studies depend on human assessments and simple metrics that fail to capture the discernment of LLMs across diverse NLG tasks. To address this gap, we propose the Discernment of Hierarchical Perturbation (DHP) benchmarking framework, which provides quantitative discernment scores for LLMs utilizing hierarchically perturbed text data and statistical tests to measure the NLG evaluation capabilities of LLMs systematically. We have re-established six evaluation datasets for this benchmark, covering four NLG tasks: Summarization, Story Completion, Question Answering, and Translation. Our comprehensive benchmarking of five major LLM series provides critical insight into their strengths and limitations as NLG evaluators.
Bilevel Generative Learning for Low-Light Vision
Aug 07, 2023Recently, there has been a growing interest in constructing deep learning schemes for Low-Light Vision (LLV). Existing techniques primarily focus on designing task-specific and data-dependent vision models on the standard RGB domain, which inherently contain latent data associations. In this study, we propose a generic low-light vision solution by introducing a generative block to convert data from the RAW to the RGB domain. This novel approach connects diverse vision problems by explicitly depicting data generation, which is the first in the field. To precisely characterize the latent correspondence between the generative procedure and the vision task, we establish a bilevel model with the parameters of the generative block defined as the upper level and the parameters of the vision task defined as the lower level. We further develop two types of learning strategies targeting different goals, namely low cost and high accuracy, to acquire a new bilevel generative learning paradigm. The generative blocks embrace a strong generalization ability in other low-light vision tasks through the bilevel optimization on enhancement tasks. Extensive experimental evaluations on three representative low-light vision tasks, namely enhancement, detection, and segmentation, fully demonstrate the superiority of our proposed approach. The code will be available at https://github.com/Yingchi1998/BGL.
Rumor Detection on Social Media: Datasets, Methods and Opportunities
Nov 17, 2019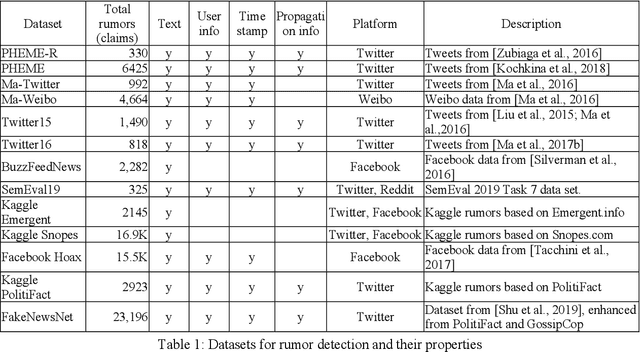
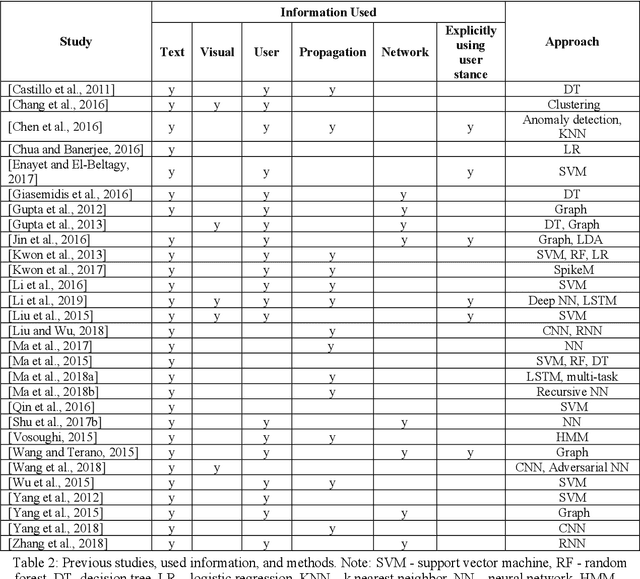
Social media platforms have been used for information and news gathering, and they are very valuable in many applications. However, they also lead to the spreading of rumors and fake news. Many efforts have been taken to detect and debunk rumors on social media by analyzing their content and social context using machine learning techniques. This paper gives an overview of the recent studies in the rumor detection field. It provides a comprehensive list of datasets used for rumor detection, and reviews the important studies based on what types of information they exploit and the approaches they take. And more importantly, we also present several new directions for future research.
* 10 pages
Uncover Sexual Harassment Patterns from Personal Stories by Joint Key Element Extraction and Categorization
Nov 01, 2019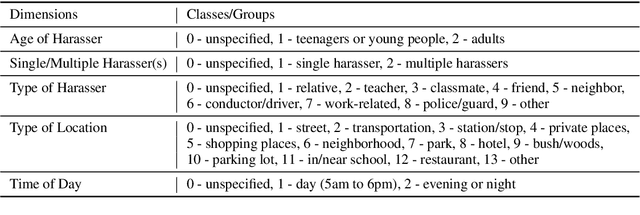
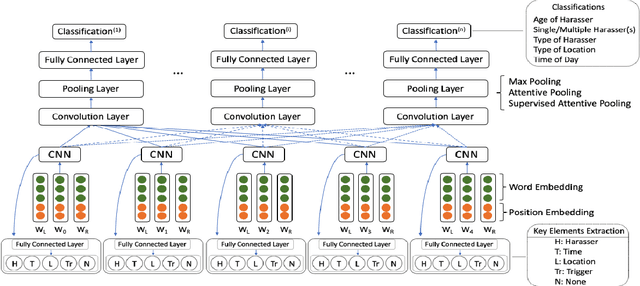
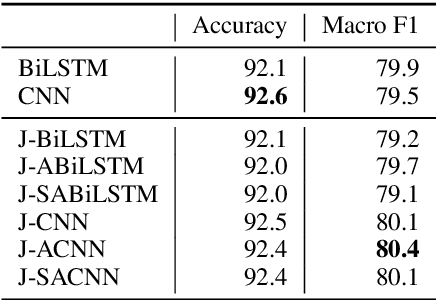

The number of personal stories about sexual harassment shared online has increased exponentially in recent years. This is in part inspired by the \#MeToo and \#TimesUp movements. Safecity is an online forum for people who experienced or witnessed sexual harassment to share their personal experiences. It has collected \textgreater 10,000 stories so far. Sexual harassment occurred in a variety of situations, and categorization of the stories and extraction of their key elements will provide great help for the related parties to understand and address sexual harassment. In this study, we manually annotated those stories with labels in the dimensions of location, time, and harassers' characteristics, and marked the key elements related to these dimensions. Furthermore, we applied natural language processing technologies with joint learning schemes to automatically categorize these stories in those dimensions and extract key elements at the same time. We also uncovered significant patterns from the categorized sexual harassment stories. We believe our annotated data set, proposed algorithms, and analysis will help people who have been harassed, authorities, researchers and other related parties in various ways, such as automatically filling reports, enlightening the public in order to prevent future harassment, and enabling more effective, faster action to be taken.