 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Detection from Social Media Stream: Methods, Datasets and Opportunities
Jun 28, 2023Social media streams contain large and diverse amount of information, ranging from daily-life stories to the latest global and local events and news. Twitter, especially, allows a fast spread of events happening real time, and enables individuals and organizations to stay informed of the events happening now. Event detection from social media data poses different challenges from traditional text and is a research area that has attracted much attention in recent years. In this paper, we survey a wide range of event detection methods for Twitter data stream, helping readers understand the recent development in this area. We present the datasets available to the public. Furthermore, a few research opportunities
Rumor Detection on Social Media: Datasets, Methods and Opportunities
Nov 17, 2019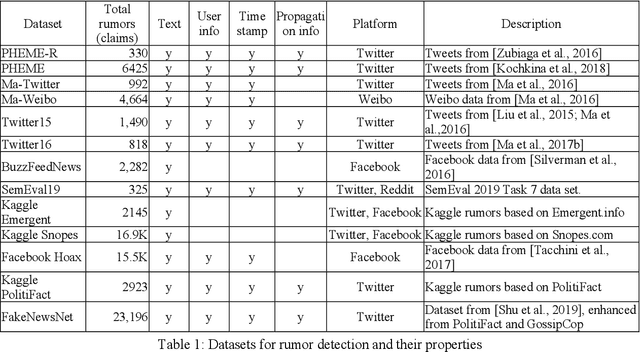
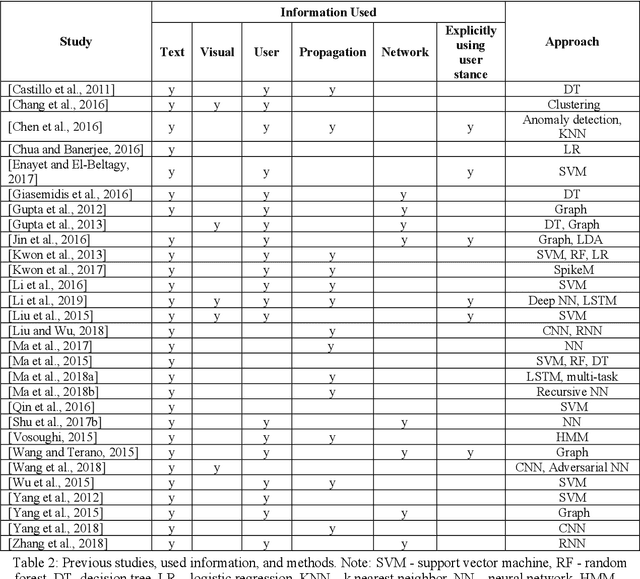
Social media platforms have been used for information and news gathering, and they are very valuable in many applications. However, they also lead to the spreading of rumors and fake news. Many efforts have been taken to detect and debunk rumors on social media by analyzing their content and social context using machine learning techniques. This paper gives an overview of the recent studies in the rumor detection field. It provides a comprehensive list of datasets used for rumor detection, and reviews the important studies based on what types of information they exploit and the approaches they take. And more importantly, we also present several new directions for future research.
* 10 pages
Uncover Sexual Harassment Patterns from Personal Stories by Joint Key Element Extraction and Categorization
Nov 01, 2019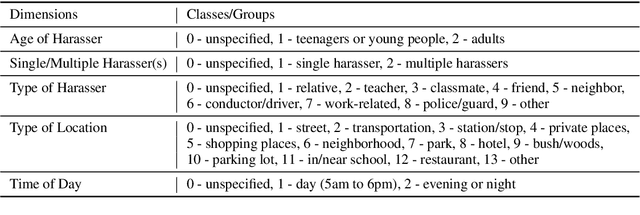
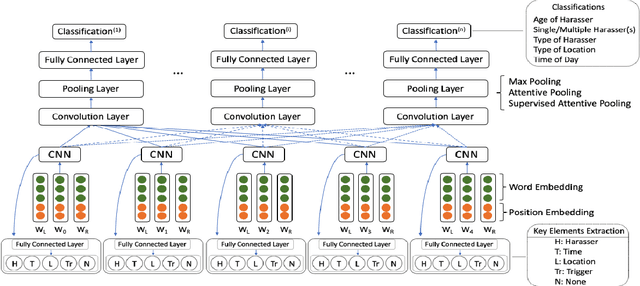
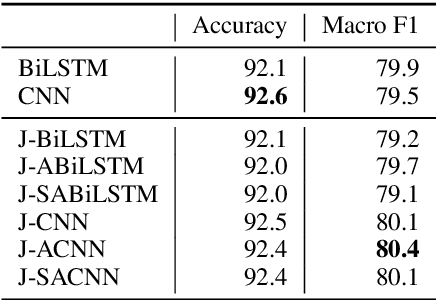

The number of personal stories about sexual harassment shared online has increased exponentially in recent years. This is in part inspired by the \#MeToo and \#TimesUp movements. Safecity is an online forum for people who experienced or witnessed sexual harassment to share their personal experiences. It has collected \textgreater 10,000 stories so far. Sexual harassment occurred in a variety of situations, and categorization of the stories and extraction of their key elements will provide great help for the related parties to understand and address sexual harassment. In this study, we manually annotated those stories with labels in the dimensions of location, time, and harassers' characteristics, and marked the key elements related to these dimensions. Furthermore, we applied natural language processing technologies with joint learning schemes to automatically categorize these stories in those dimensions and extract key elements at the same time. We also uncovered significant patterns from the categorized sexual harassment stories. We believe our annotated data set, proposed algorithms, and analysis will help people who have been harassed, authorities, researchers and other related parties in various ways, such as automatically filling reports, enlightening the public in order to prevent future harassment, and enabling more effective, faster action to be taken.
Data Sets: Word Embeddings Learned from Tweets and General Data
Aug 14, 2017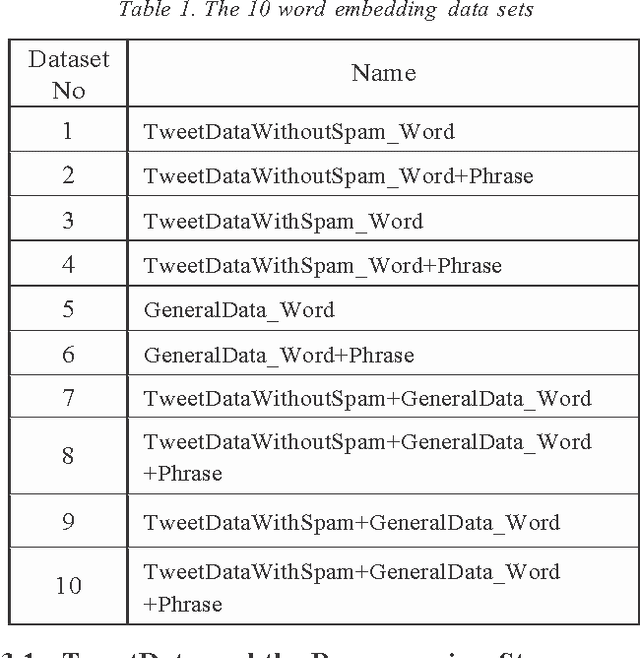
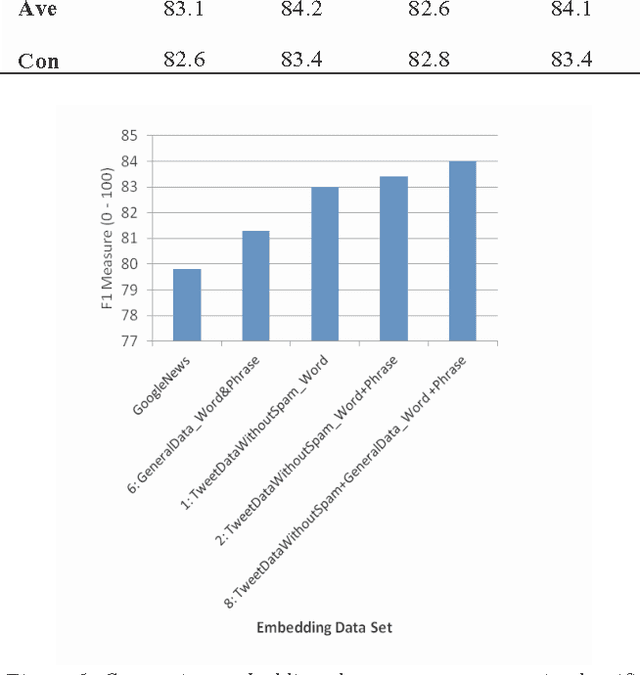
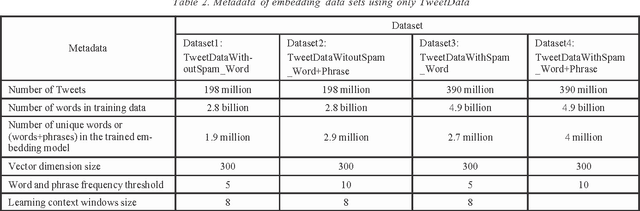
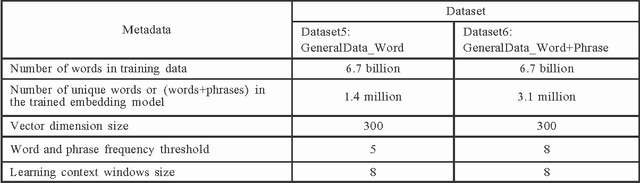
A word embedding is a low-dimensional, dense and real- valued vector representation of a word. Word embeddings have been used in many NLP tasks. They are usually gener- ated from a large text corpus. The embedding of a word cap- tures both its syntactic and semantic aspects. Tweets are short, noisy and have unique lexical and semantic features that are different from other types of text. Therefore, it is necessary to have word embeddings learned specifically from tweets. In this paper, we present ten word embedding data sets. In addition to the data sets learned from just tweet data, we also built embedding sets from the general data and the combination of tweets with the general data. The general data consist of news articles, Wikipedia data and other web data. These ten embedding models were learned from about 400 million tweets and 7 billion words from the general text. In this paper, we also present two experiments demonstrating how to use the data sets in some NLP tasks, such as tweet sentiment analysis and tweet topic classification tasks.