 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Guided Knowledge Distillation for Efficient Point Cloud Processing
May 12, 2025Point cloud processing has gained significant attention due to its critical role in applications such as autonomous driving and 3D object recognition. However, deploying high-performance models like Point Transformer V3 in resource-constrained environments remains challenging due to their high computational and memory demands. This work introduces a novel distillation framework that leverages topology-aware representations and gradient-guided knowledge distillation to effectively transfer knowledge from a high-capacity teacher to a lightweight student model. Our approach captures the underlying geometric structures of point clouds while selectively guiding the student model's learning process through gradient-based feature alignment. Experimental results in the Nuscenes, SemanticKITTI, and Waymo datasets demonstrate that the proposed method achieves competitive performance, with an approximately 16x reduction in model size and a nearly 1.9x decrease in inference time compared to its teacher model. Notably, on NuScenes, our method achieves state-of-the-art performance among knowledge distillation techniques trained solely on LiDAR data, surpassing prior knowledge distillation baselines in segmentation performance. Our implementation is available publicly at: https://github.com/HySonLab/PointDistill
Data Augmentation Through Random Style Replacement
Apr 14, 2025In this paper, we introduce a novel data augmentation technique that combines the advantages of style augmentation and random erasing by selectively replacing image subregions with style-transferred patches. Our approach first applies a random style transfer to training images, then randomly substitutes selected areas of these images with patches derived from the style-transferred versions. This method is able to seamlessly accommodate a wide range of existing style transfer algorithms and can be readily integrated into diverse data augmentation pipelines. By incorporating our strategy, the training process becomes more robust and less prone to overfitting. Comparative experiments demonstrate that, relative to previous style augmentation methods, our technique achieves superior performance and faster convergence.
MMREC: LLM Based Multi-Modal Recommender System
Aug 08, 2024The importance of recommender systems is growing rapidly due to the exponential increase in the volume of content generated daily. This surge in content presents unique challenges for designing effective recommender systems. Key among these challenges is the need to effectively leverage the vast amounts of natural language data and images that represent user preferences. This paper presents a novel approach to enhancing recommender systems by leveraging Large Language Models (LLMs) and deep learning techniques. The proposed framework aims to improve the accuracy and relevance of recommendations by incorporating multi-modal information processing and by the use of unified latent space representation. The study explores the potential of LLMs to better understand and utilize natural language data in recommendation contexts, addressing the limitations of previous methods. The framework efficiently extracts and integrates text and image information through LLMs, unifying diverse modalities in a latent space to simplify the learning process for the ranking model. Experimental results demonstrate the enhanced discriminative power of the model when utilizing multi-modal information. This research contributes to the evolving field of recommender systems by showcasing the potential of LLMs and multi-modal data integration to create more personalized and contextually relevant recommendations.
Semantic Understanding and Data Imputation using Large Language Model to Accelerate Recommendation System
Jul 14, 2024This paper aims to address the challenge of sparse and missing data in recommendation systems, a significant hurdle in the age of big data. Traditional imputation methods struggle to capture complex relationships within the data. We propose a novel approach that fine-tune Large Language Model (LLM) and use it impute missing data for recommendation systems. LLM which is trained on vast amounts of text, is able to understand complex relationship among data and intelligently fill in missing information. This enriched data is then used by the recommendation system to generate more accurate and personalized suggestions, ultimately enhancing the user experience. We evaluate our LLM-based imputation method across various tasks within the recommendation system domain, including single classification, multi-classification, and regression compared to traditional data imputation methods. By demonstrating the superiority of LLM imputation over traditional methods, we establish its potential for improving recommendation system performance.
Advancing Prompt Recovery in NLP: A Deep Dive into the Integration of Gemma-2b-it and Phi2 Models
Jul 07, 2024Prompt recovery, a crucial task in natural language processing, entails the reconstruction of prompts or instructions that language models use to convert input text into a specific output. Although pivotal, the design and effectiveness of prompts represent a challenging and relatively untapped field within NLP research. This paper delves into an exhaustive investigation of prompt recovery methodologies, employing a spectrum of pre-trained language models and strategies. Our study is a comparative analysis aimed at gauging the efficacy of various models on a benchmark dataset, with the goal of pinpointing the most proficient approach for prompt recovery. Through meticulous experimentation and detailed analysis, we elucidate the outstanding performance of the Gemma-2b-it + Phi2 model + Pretrain. This model surpasses its counterparts, showcasing its exceptional capability in accurately reconstructing prompts for text transformation tasks. Our findings offer a significant contribution to the existing knowledge on prompt recovery, shedding light on the intricacies of prompt design and offering insightful perspectives for future innovations in text rewriting and the broader field of natural language processing.
Enhance Image-to-Image Generation with LLaVA Prompt and Negative Prompt
Jun 04, 2024This paper presents a novel approach to enhance image-to-image generation by leveraging the multimodal capabilities of the Large Language and Vision Assistant (LLaVA). We propose a framework where LLaVA analyzes input images and generates textual descriptions, hereinafter LLaVA-generated prompts. These prompts, along with the original image, are fed into the image-to-image generation pipeline. This enriched representation guides the generation process towards outputs that exhibit a stronger resemblance to the input image. Extensive experiments demonstrate the effectiveness of LLaVA-generated prompts in promoting image similarity. We observe a significant improvement in the visual coherence between the generated and input images compared to traditional methods. Future work will explore fine-tuning LLaVA prompts for increased control over the creative process. By providing more specific details within the prompts, we aim to achieve a delicate balance between faithfulness to the original image and artistic expression in the generated outputs.
Improved AdaBoost for Virtual Reality Experience Prediction Based on Long Short-Term Memory Network
May 17, 2024
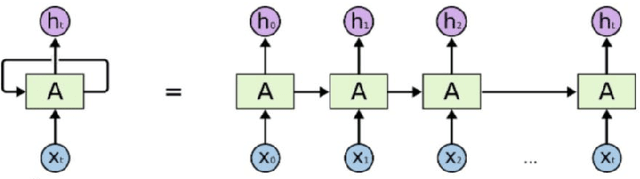
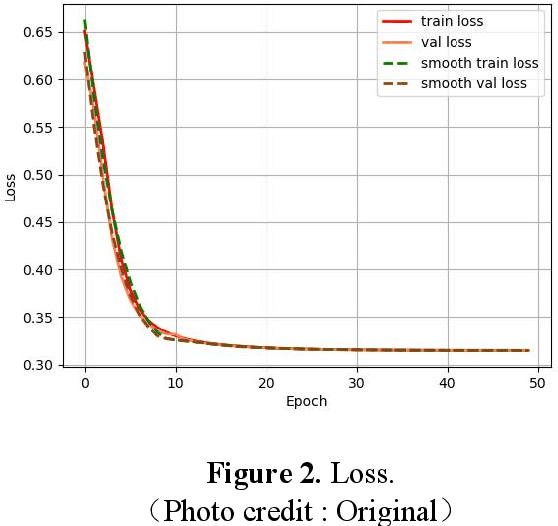
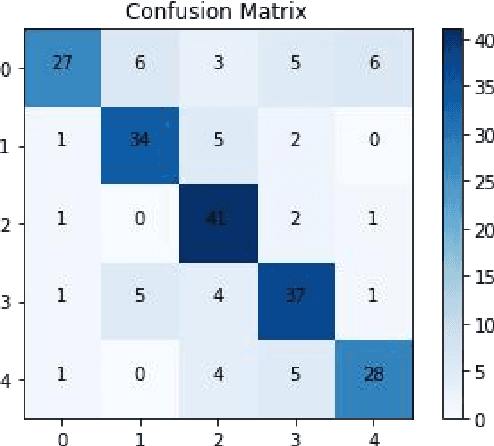
A classification prediction algorithm based on Long Short-Term Memory Network (LSTM) improved AdaBoost is used to predict virtual reality (VR) user experience. The dataset is randomly divided into training and test sets in the ratio of 7:3.During the training process, the model's loss value decreases from 0.65 to 0.31, which shows that the model gradually reduces the discrepancy between the prediction results and the actual labels, and improves the accuracy and generalisation ability.The final loss value of 0.31 indicates that the model fits the training data well, and is able to make predictions and classifications more accurately. The confusion matrix for the training set shows a total of 177 correct predictions and 52 incorrect predictions, with an accuracy of 77%, precision of 88%, recall of 77% and f1 score of 82%. The confusion matrix for the test set shows a total of 167 correct and 53 incorrect predictions with 75% accuracy, 87% precision, 57% recall and 69% f1 score. In summary, the classification prediction algorithm based on LSTM with improved AdaBoost shows good prediction ability for virtual reality user experience. This study is of great significance to enhance the application of virtual reality technology in user experience. By combining LSTM and AdaBoost algorithms, significant progress has been made in user experience prediction, which not only improves the accuracy and generalisation ability of the model, but also provides useful insights for related research in the field of virtual reality. This approach can help developers better understand user requirements, optimise virtual reality product design, and enhance user satisfaction, promoting the wide application of virtual reality technology in various fields.
A Comparative Study on Enhancing Prediction in Social Network Advertisement through Data Augmentation
Apr 28, 2024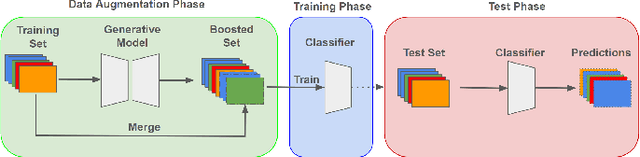
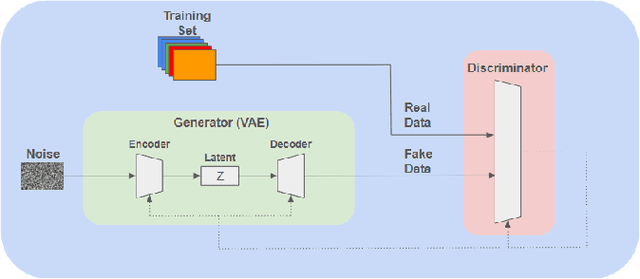
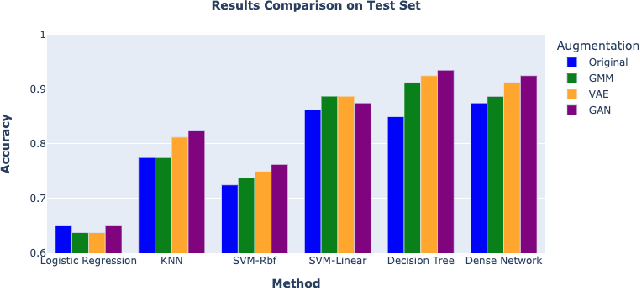
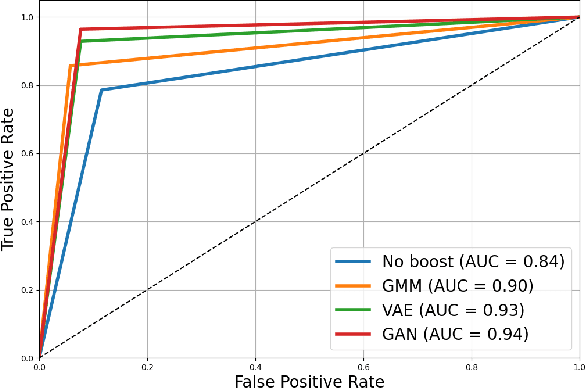
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.
Text Sentiment Analysis and Classification Based on Bidirectional Gated Recurrent Units (GRUs) Model
Apr 26, 2024This paper explores the importance of text sentiment analysis and classification in the field of natural language processing, and proposes a new approach to sentiment analysis and classification based on the bidirectional gated recurrent units (GRUs) model. The study firstly analyses the word cloud model of the text with six sentiment labels, and then carries out data preprocessing, including the steps of removing special symbols, punctuation marks, numbers, stop words and non-alphabetic parts. Subsequently, the data set is divided into training set and test set, and through model training and testing, it is found that the accuracy of the validation set is increased from 85% to 93% with training, which is an increase of 8%; at the same time, the loss value of the validation set decreases from 0.7 to 0.1 and tends to be stable, and the model is gradually close to the actual value, which can effectively classify the text emotions. The confusion matrix shows that the accuracy of the model on the test set reaches 94.8%, the precision is 95.9%, the recall is 99.1%, and the F1 score is 97.4%, which proves that the model has good generalisation ability and classification effect. Overall, the study demonstrated an effective method for text sentiment analysis and classification with satisfactory results.
Regional Style and Color Transfer
Apr 24, 2024This paper presents a novel contribution to the field of regional style transfer. Existing methods often suffer from the drawback of applying style homogeneously across the entire image, leading to stylistic inconsistencies or foreground object twisted when applied to image with foreground elements such as person figures. To address this limitation, we propose a new approach that leverages a segmentation network to precisely isolate foreground objects within the input image. Subsequently, style transfer is applied exclusively to the background region. The isolated foreground objects are then carefully reintegrated into the style-transferred background. To enhance the visual coherence between foreground and background, a color transfer step is employed on the foreground elements prior to their rein-corporation. Finally, we utilize feathering techniques to achieve a seamless amalgamation of foreground and background, resulting in a visually unified and aesthetically pleasing final composition. Extensive evaluations demonstrate that our proposed approach yields significantly more natural stylistic transformations compared to conventional methods.