 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
Advancing Prompt Recovery in NLP: A Deep Dive into the Integration of Gemma-2b-it and Phi2 Models
Jul 07, 2024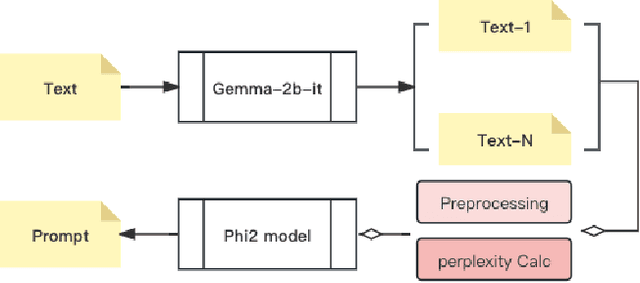
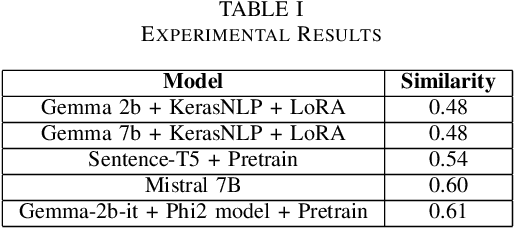
Prompt recovery, a crucial task in natural language processing, entails the reconstruction of prompts or instructions that language models use to convert input text into a specific output. Although pivotal, the design and effectiveness of prompts represent a challenging and relatively untapped field within NLP research. This paper delves into an exhaustive investigation of prompt recovery methodologies, employing a spectrum of pre-trained language models and strategies. Our study is a comparative analysis aimed at gauging the efficacy of various models on a benchmark dataset, with the goal of pinpointing the most proficient approach for prompt recovery. Through meticulous experimentation and detailed analysis, we elucidate the outstanding performance of the Gemma-2b-it + Phi2 model + Pretrain. This model surpasses its counterparts, showcasing its exceptional capability in accurately reconstructing prompts for text transformation tasks. Our findings offer a significant contribution to the existing knowledge on prompt recovery, shedding light on the intricacies of prompt design and offering insightful perspectives for future innovations in text rewriting and the broader field of natural language processing.
An effective software risk prediction management analysis of data using machine learning and data mining method
Jun 13, 2024For one to guarantee higher-quality software development processes, risk management is essential. Furthermore, risks are those that could negatively impact an organization's operations or a project's progress. The appropriate prioritisation of software project risks is a crucial factor in ascertaining the software project's performance features and eventual success. They can be used harmoniously with the same training samples and have good complement and compatibility. We carried out in-depth tests on four benchmark datasets to confirm the efficacy of our CIA approach in closed-world and open-world scenarios, with and without defence. We also present a sequential augmentation parameter optimisation technique that captures the interdependencies of the latest deep learning state-of-the-art WF attack models. To achieve precise software risk assessment, the enhanced crow search algorithm (ECSA) is used to modify the ANFIS settings. Solutions that very slightly alter the local optimum and stay inside it are extracted using the ECSA. ANFIS variable when utilising the ANFIS technique. An experimental validation with NASA 93 dataset and 93 software project values was performed. This method's output presents a clear image of the software risk elements that are essential to achieving project performance. The results of our experiments show that, when compared to other current methods, our integrative fuzzy techniques may perform more accurately and effectively in the evaluation of software project risks.
A K-means Algorithm for Financial Market Risk Forecasting
May 21, 2024Financial market risk forecasting involves applying mathematical models, historical data analysis and statistical methods to estimate the impact of future market movements on investments. This process is crucial for investors to develop strategies, financial institutions to manage assets and regulators to formulate policy. In today's society, there are problems of high error rate and low precision in financial market risk prediction, which greatly affect the accuracy of financial market risk prediction. K-means algorithm in machine learning is an effective risk prediction technique for financial market. This study uses K-means algorithm to develop a financial market risk prediction system, which significantly improves the accuracy and efficiency of financial market risk prediction. Ultimately, the outcomes of the experiments confirm that the K-means algorithm operates with user-friendly simplicity and achieves a 94.61% accuracy rate
Optimization of Worker Scheduling at Logistics Depots Using Genetic Algorithms and Simulated Annealing
May 20, 2024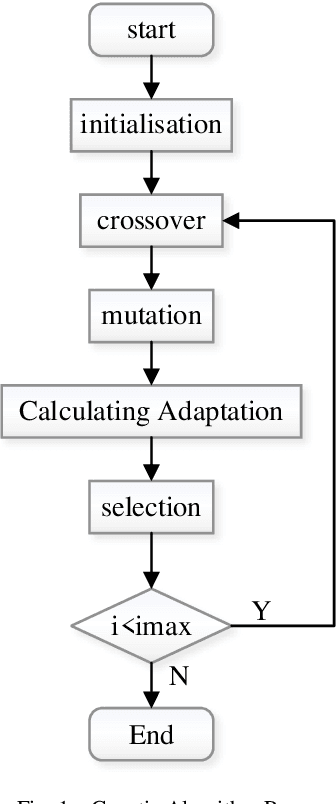
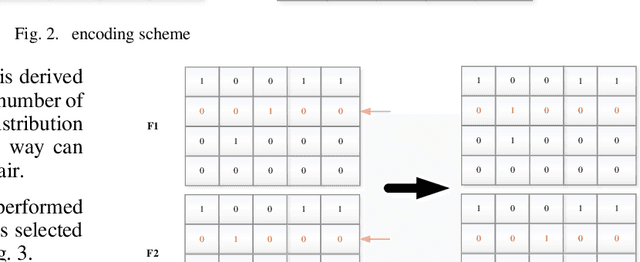
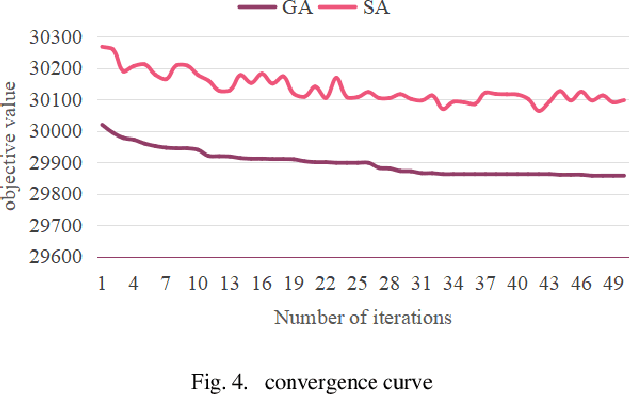
This paper addresses the optimization of scheduling for workers at a logistics depot using a combination of genetic algorithm and simulated annealing algorithm. The efficient scheduling of permanent and temporary workers is crucial for optimizing the efficiency of the logistics depot while minimizing labor usage. The study begins by establishing a 0-1 integer linear programming model, with decision variables determining the scheduling of permanent and temporary workers for each time slot on a given day. The objective function aims to minimize person-days, while constraints ensure fulfillment of hourly labor requirements, limit workers to one time slot per day, cap consecutive working days for permanent workers, and maintain non-negativity and integer constraints. The model is then solved using genetic algorithms and simulated annealing. Results indicate that, for this problem, genetic algorithms outperform simulated annealing in terms of solution quality. The optimal solution reveals a minimum of 29857 person-days.
Mapping New Realities: Ground Truth Image Creation with Pix2Pix Image-to-Image Translation
May 01, 2024


Generative Adversarial Networks (GANs) have significantly advanced image processing, with Pix2Pix being a notable framework for image-to-image translation. This paper explores a novel application of Pix2Pix to transform abstract map images into realistic ground truth images, addressing the scarcity of such images crucial for domains like urban planning and autonomous vehicle training. We detail the Pix2Pix model's utilization for generating high-fidelity datasets, supported by a dataset of paired map and aerial images, and enhanced by a tailored training regimen. The results demonstrate the model's capability to accurately render complex urban features, establishing its efficacy and potential for broad real-world applications.
Vision-based Robotic Arm Imitation by Human Gesture
Oct 04, 2018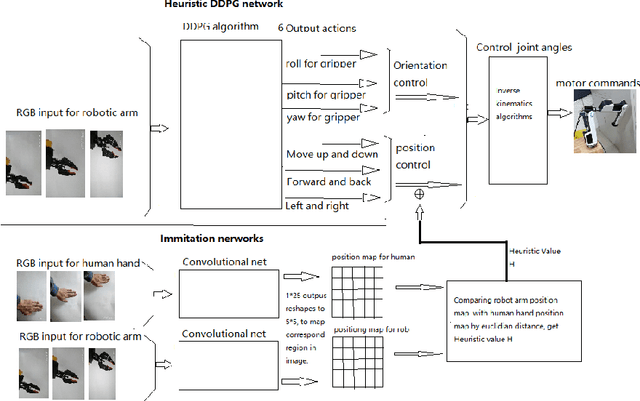
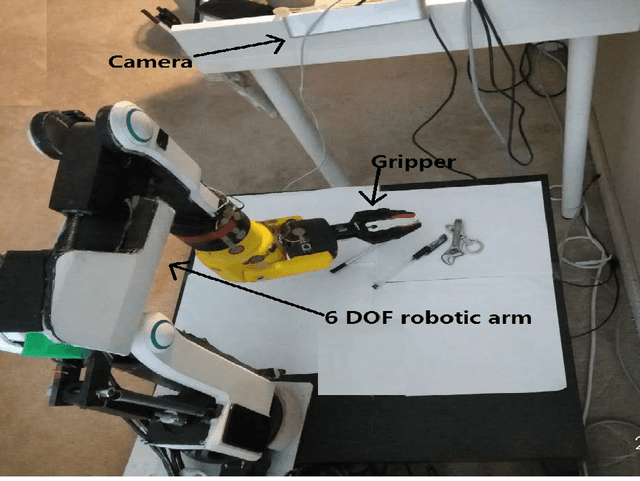
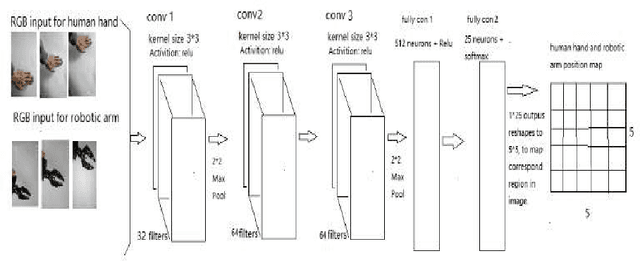

One of the most efficient ways for a learning-based robotic arm to learn to process complex tasks as human, is to directly learn from observing how human complete those tasks, and then imitate. Our idea is based on success of Deep Q-Learning (DQN) algorithm according to reinforcement learning, and then extend to Deep Deterministic Policy Gradient (DDPG) algorithm. We developed a learning-based method, combining modified DDPG and visual imitation network. Our approach acquires frames only from a monocular camera, and no need to either construct a 3D environment or generate actual points. The result we expected during training, was that robot would be able to move as almost the same as how human hands did.