 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
An effective software risk prediction management analysis of data using machine learning and data mining method
Jun 13, 2024For one to guarantee higher-quality software development processes, risk management is essential. Furthermore, risks are those that could negatively impact an organization's operations or a project's progress. The appropriate prioritisation of software project risks is a crucial factor in ascertaining the software project's performance features and eventual success. They can be used harmoniously with the same training samples and have good complement and compatibility. We carried out in-depth tests on four benchmark datasets to confirm the efficacy of our CIA approach in closed-world and open-world scenarios, with and without defence. We also present a sequential augmentation parameter optimisation technique that captures the interdependencies of the latest deep learning state-of-the-art WF attack models. To achieve precise software risk assessment, the enhanced crow search algorithm (ECSA) is used to modify the ANFIS settings. Solutions that very slightly alter the local optimum and stay inside it are extracted using the ECSA. ANFIS variable when utilising the ANFIS technique. An experimental validation with NASA 93 dataset and 93 software project values was performed. This method's output presents a clear image of the software risk elements that are essential to achieving project performance. The results of our experiments show that, when compared to other current methods, our integrative fuzzy techniques may perform more accurately and effectively in the evaluation of software project risks.
A K-means Algorithm for Financial Market Risk Forecasting
May 21, 2024Financial market risk forecasting involves applying mathematical models, historical data analysis and statistical methods to estimate the impact of future market movements on investments. This process is crucial for investors to develop strategies, financial institutions to manage assets and regulators to formulate policy. In today's society, there are problems of high error rate and low precision in financial market risk prediction, which greatly affect the accuracy of financial market risk prediction. K-means algorithm in machine learning is an effective risk prediction technique for financial market. This study uses K-means algorithm to develop a financial market risk prediction system, which significantly improves the accuracy and efficiency of financial market risk prediction. Ultimately, the outcomes of the experiments confirm that the K-means algorithm operates with user-friendly simplicity and achieves a 94.61% accuracy rate
Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
Apr 07, 2024



The rapid advancement of Large Language Models (LLMs) has inaugurated a transformative epoch in natural language processing, fostering unprecedented proficiency in text generation, comprehension, and contextual scrutiny. Nevertheless, effectively handling extensive contexts, crucial for myriad applications, poses a formidable obstacle owing to the intrinsic constraints of the models' context window sizes and the computational burdens entailed by their operations. This investigation presents an innovative framework that strategically tailors LLMs for streamlined context processing by harnessing the synergies among natural language summarization, soft prompt compression, and augmented utility preservation mechanisms. Our methodology, dubbed SoftPromptComp, amalgamates natural language prompts extracted from summarization methodologies with dynamically generated soft prompts to forge a concise yet semantically robust depiction of protracted contexts. This depiction undergoes further refinement via a weighting mechanism optimizing information retention and utility for subsequent tasks. We substantiate that our framework markedly diminishes computational overhead and enhances LLMs' efficacy across various benchmarks, while upholding or even augmenting the caliber of the produced content. By amalgamating soft prompt compression with sophisticated summarization, SoftPromptComp confronts the dual challenges of managing lengthy contexts and ensuring model scalability. Our findings point towards a propitious trajectory for augmenting LLMs' applicability and efficiency, rendering them more versatile and pragmatic for real-world applications. This research enriches the ongoing discourse on optimizing language models, providing insights into the potency of soft prompts and summarization techniques as pivotal instruments for the forthcoming generation of NLP solutions.
DAC: Deep Autoencoder-based Clustering, a General Deep Learning Framework of Representation Learning
Feb 15, 2021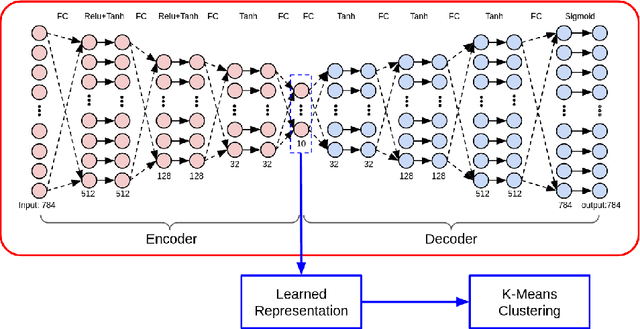



Clustering performs an essential role in many real world applications, such as market research, pattern recognition, data analysis, and image processing. However, due to the high dimensionality of the input feature values, the data being fed to clustering algorithms usually contains noise and thus could lead to in-accurate clustering results. While traditional dimension reduction and feature selection algorithms could be used to address this problem, the simple heuristic rules used in those algorithms are based on some particular assumptions. When those assumptions does not hold, these algorithms then might not work. In this paper, we propose DAC, Deep Autoencoder-based Clustering, a generalized data-driven framework to learn clustering representations using deep neuron networks. Experiment results show that our approach could effectively boost performance of the K-Means clustering algorithm on a variety types of datasets.