 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-Zip: Adaptive Visual Token Compression with Intrinsic Image Information
Dec 11, 2024

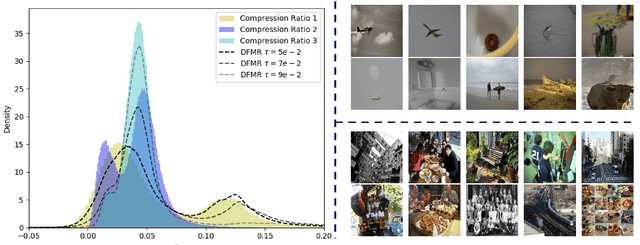
Multi-modal large language models (MLLMs) utilizing instruction-following data, such as LLaVA, have achieved great progress in the industry. A major limitation in these models is that visual tokens consume a substantial portion of the maximum token limit in large language models (LLMs), leading to increased computational demands and decreased performance when prompts include multiple images or videos. Industry solutions often mitigate this issue by increasing computational power, but this approach is less feasible in academic environments with limited resources. In this study, we propose Dynamic Feature Map Reduction (DFMR) based on LLaVA-1.5 to address the challenge of visual token overload. DFMR dynamically compresses the visual tokens, freeing up token capacity. Our experimental results demonstrate that integrating DFMR into LLaVA-1.5 significantly improves the performance of LLaVA in varied visual token lengths, offering a promising solution for extending LLaVA to handle multi-image and video scenarios in resource-constrained academic environments and it can also be applied in industry settings for data augmentation to help mitigate the scarcity of open-domain image-text pair datasets in the continued pretraining stage.
TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
Sep 21, 2023In this paper, we propose a novel cross-modal distillation method, called TinyCLIP, for large-scale language-image pre-trained models. The method introduces two core techniques: affinity mimicking and weight inheritance. Affinity mimicking explores the interaction between modalities during distillation, enabling student models to mimic teachers' behavior of learning cross-modal feature alignment in a visual-linguistic affinity space. Weight inheritance transmits the pre-trained weights from the teacher models to their student counterparts to improve distillation efficiency. Moreover, we extend the method into a multi-stage progressive distillation to mitigate the loss of informative weights during extreme compression. Comprehensive experiments demonstrate the efficacy of TinyCLIP, showing that it can reduce the size of the pre-trained CLIP ViT-B/32 by 50%, while maintaining comparable zero-shot performance. While aiming for comparable performance, distillation with weight inheritance can speed up the training by 1.4 - 7.8 $\times$ compared to training from scratch. Moreover, our TinyCLIP ViT-8M/16, trained on YFCC-15M, achieves an impressive zero-shot top-1 accuracy of 41.1% on ImageNet, surpassing the original CLIP ViT-B/16 by 3.5% while utilizing only 8.9% parameters. Finally, we demonstrate the good transferability of TinyCLIP in various downstream tasks. Code and models will be open-sourced at https://aka.ms/tinyclip.
Dissecting the impact of different loss functions with gradient surgery
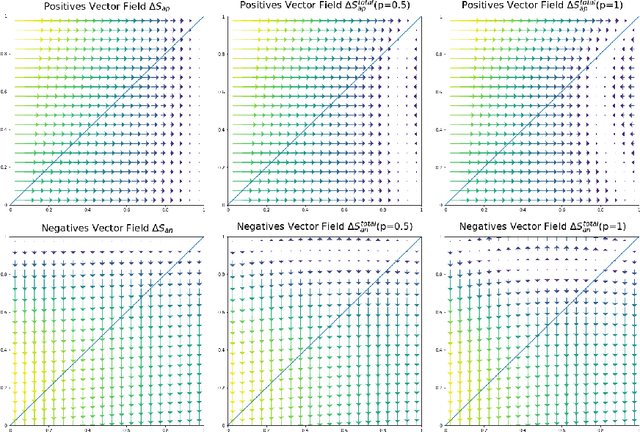
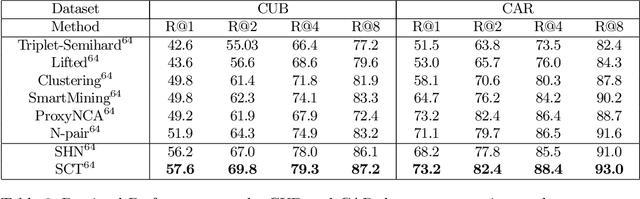
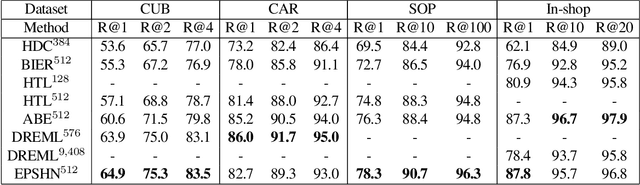
Jan 27, 2022Pair-wise loss is an approach to metric learning that learns a semantic embedding by optimizing a loss function that encourages images from the same semantic class to be mapped closer than images from different classes. The literature reports a large and growing set of variations of the pair-wise loss strategies. Here we decompose the gradient of these loss functions into components that relate to how they push the relative feature positions of the anchor-positive and anchor-negative pairs. This decomposition allows the unification of a large collection of current pair-wise loss functions. Additionally, explicitly constructing pair-wise gradient updates to separate out these effects gives insights into which have the biggest impact, and leads to a simple algorithm that beats the state of the art for image retrieval on the CAR, CUB and Stanford Online products datasets.
Hard negative examples are hard, but useful
Jul 24, 2020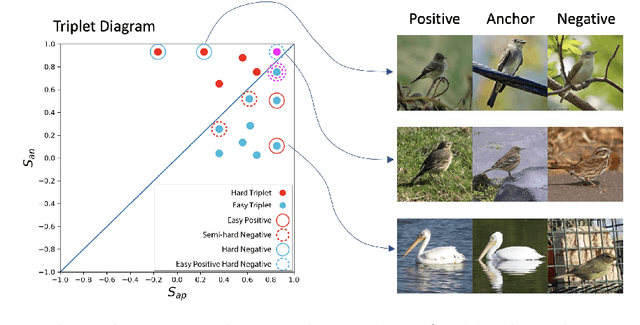
Triplet loss is an extremely common approach to distance metric learning. Representations of images from the same class are optimized to be mapped closer together in an embedding space than representations of images from different classes. Much work on triplet losses focuses on selecting the most useful triplets of images to consider, with strategies that select dissimilar examples from the same class or similar examples from different classes. The consensus of previous research is that optimizing with the \textit{hardest} negative examples leads to bad training behavior. That's a problem -- these hardest negatives are literally the cases where the distance metric fails to capture semantic similarity. In this paper, we characterize the space of triplets and derive why hard negatives make triplet loss training fail. We offer a simple fix to the loss function and show that, with this fix, optimizing with hard negative examples becomes feasible. This leads to more generalizable features, and image retrieval results that outperform state of the art for datasets with high intra-class variance.
Visualizing How Embeddings Generalize
Sep 16, 2019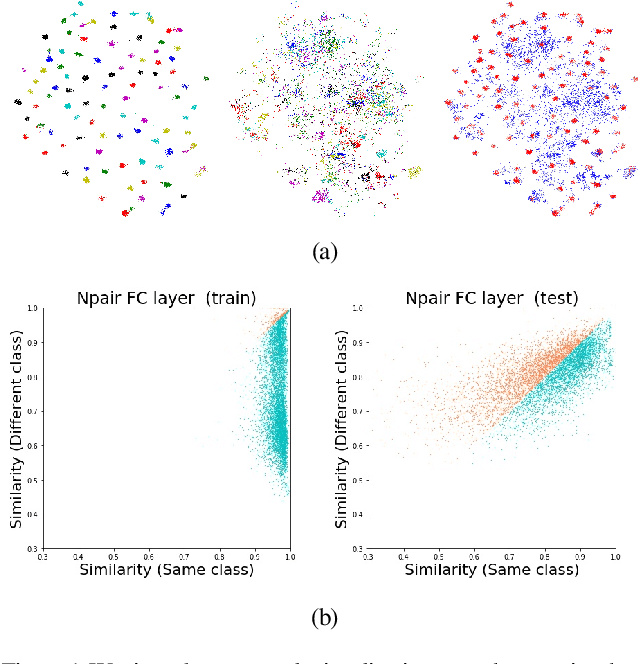
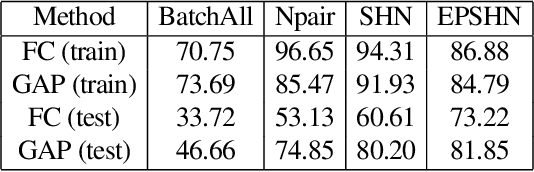
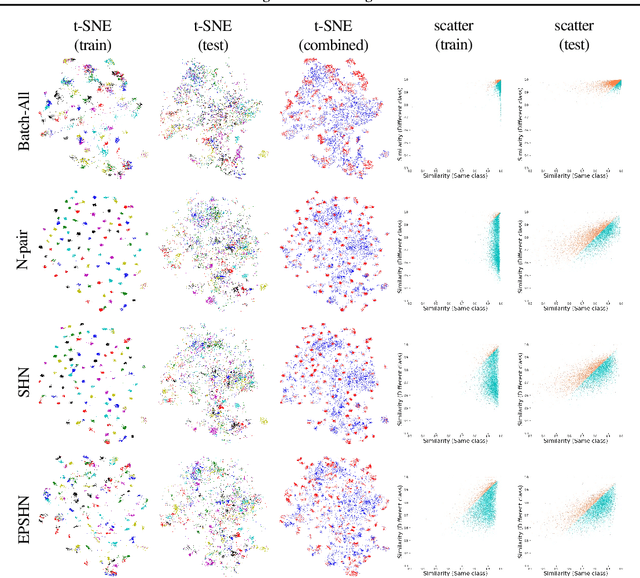
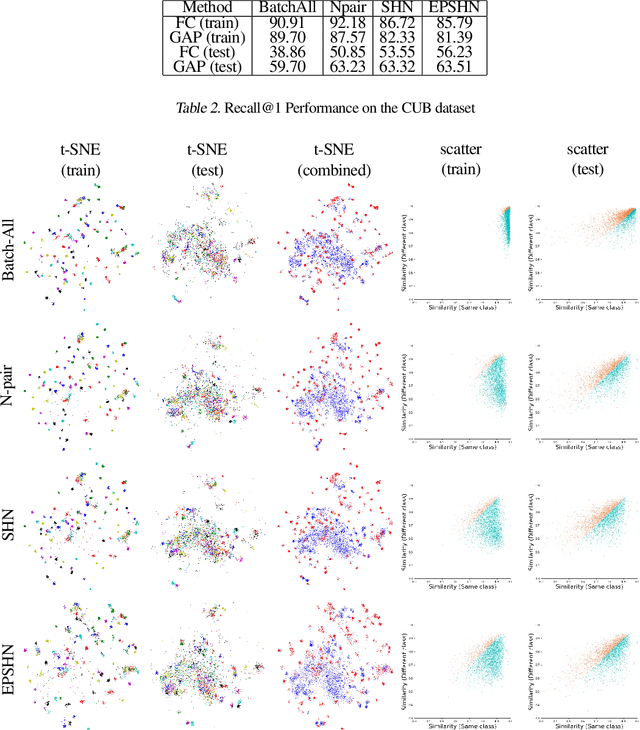
Deep metric learning is often used to learn an embedding function that captures the semantic differences within a dataset. A key factor in many problem domains is how this embedding generalizes to new classes of data. In observing many triplet selection strategies for Metric Learning, we find that the best performance consistently arises from approaches that focus on a few, well selected triplets.We introduce visualization tools to illustrate how an embedding generalizes beyond measuring accuracy on validation data, and we illustrate the behavior of a range of triplet selection strategies.
Improved Embeddings with Easy Positive Triplet Mining
Apr 08, 2019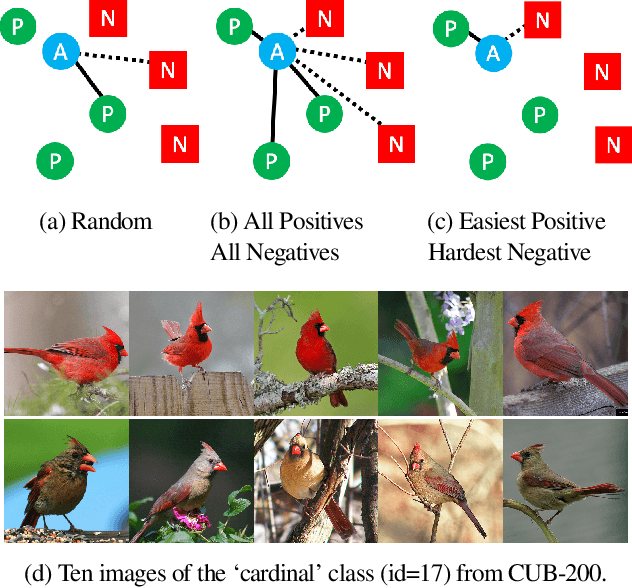
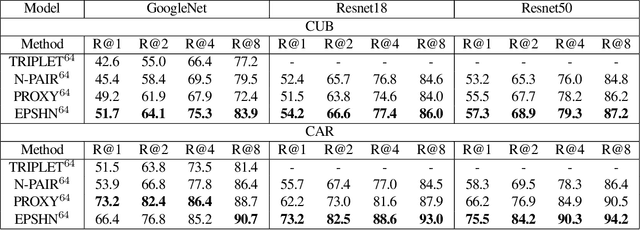
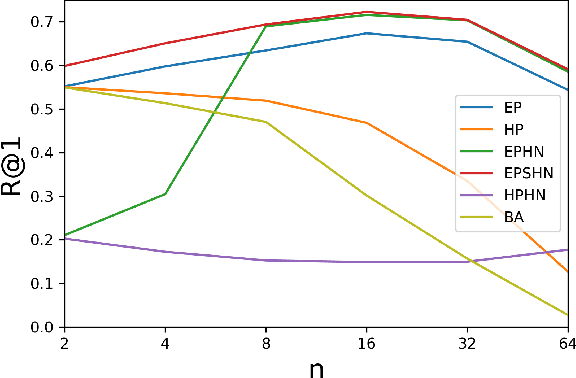
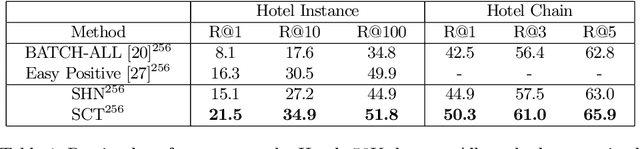
Deep metric learning seeks to define an embedding where semantically similar images are embedded to nearby locations, and semantically dissimilar images are embedded to distant locations. Substantial work has focused on loss functions and strategies to learn these embeddings by pushing images from the same class as close together in the embedding space as possible. In this paper, we propose an alternative, loosened embedding strategy that requires the embedding function only map each training image to the most similar examples from the same class, an approach we call "Easy Positive" mining. We provide a collection of experiments and visualizations that highlight that this Easy Positive mining leads to embeddings that are more flexible and generalize better to new unseen data. This simple mining strategy yields recall performance that exceeds state of the art approaches (including those with complicated loss functions and ensemble methods) on image retrieval datasets including CUB, Stanford Online Products, In-Shop Clothes and Hotels-50K.
Hotels-50K: A Global Hotel Recognition Dataset
Jan 26, 2019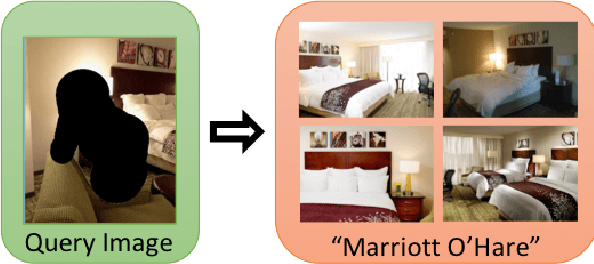
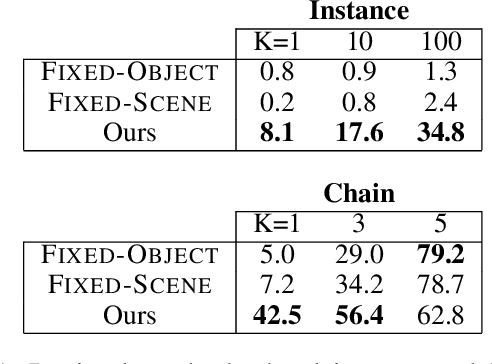


Recognizing a hotel from an image of a hotel room is important for human trafficking investigations. Images directly link victims to places and can help verify where victims have been trafficked, and where their traffickers might move them or others in the future. Recognizing the hotel from images is challenging because of low image quality, uncommon camera perspectives, large occlusions (often the victim), and the similarity of objects (e.g., furniture, art, bedding) across different hotel rooms. To support efforts towards this hotel recognition task, we have curated a dataset of over 1 million annotated hotel room images from 50,000 hotels. These images include professionally captured photographs from travel websites and crowd-sourced images from a mobile application, which are more similar to the types of images analyzed in real-world investigations. We present a baseline approach based on a standard network architecture and a collection of data-augmentation approaches tuned to this problem domain.
Deep Randomized Ensembles for Metric Learning
Sep 04, 2018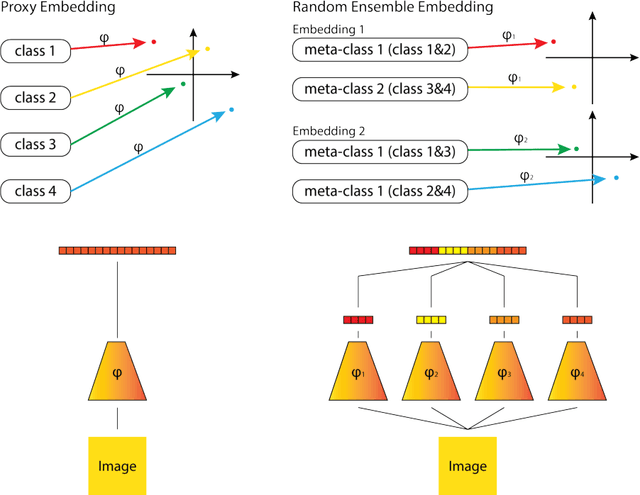


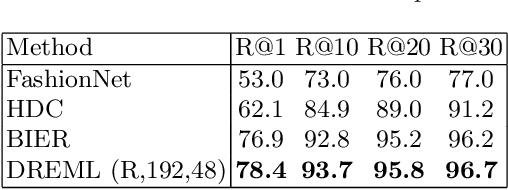
Learning embedding functions, which map semantically related inputs to nearby locations in a feature space supports a variety of classification and information retrieval tasks. In this work, we propose a novel, generalizable and fast method to define a family of embedding functions that can be used as an ensemble to give improved results. Each embedding function is learned by randomly bagging the training labels into small subsets. We show experimentally that these embedding ensembles create effective embedding functions. The ensemble output defines a metric space that improves state of the art performance for image retrieval on CUB-200-2011, Cars-196, In-Shop Clothes Retrieval and VehicleID.