 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-Zip: Adaptive Visual Token Compression with Intrinsic Image Information
Paper and Code
Dec 11, 2024

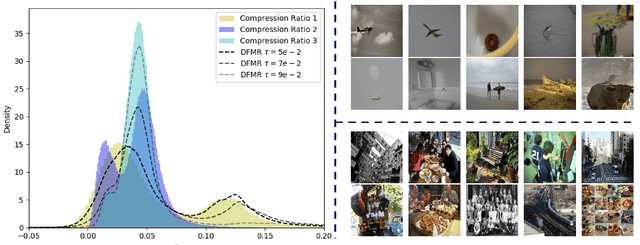
Multi-modal large language models (MLLMs) utilizing instruction-following data, such as LLaVA, have achieved great progress in the industry. A major limitation in these models is that visual tokens consume a substantial portion of the maximum token limit in large language models (LLMs), leading to increased computational demands and decreased performance when prompts include multiple images or videos. Industry solutions often mitigate this issue by increasing computational power, but this approach is less feasible in academic environments with limited resources. In this study, we propose Dynamic Feature Map Reduction (DFMR) based on LLaVA-1.5 to address the challenge of visual token overload. DFMR dynamically compresses the visual tokens, freeing up token capacity. Our experimental results demonstrate that integrating DFMR into LLaVA-1.5 significantly improves the performance of LLaVA in varied visual token lengths, offering a promising solution for extending LLaVA to handle multi-image and video scenarios in resource-constrained academic environments and it can also be applied in industry settings for data augmentation to help mitigate the scarcity of open-domain image-text pair datasets in the continued pretraining stage.