 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAurora: Unified Video Editing with a Tool-Using Agent
May 18, 2026Recent video editing models have converged on a unified conditioning design: a single diffusion transformer jointly consumes text, source video, and reference images, and one set of weights covers replacement, removal, style transfer, and reference-driven insertion. The design is flexible, but it assumes that the user already provides model-ready text, reference images, and spatial grounding for local edits, which real requests often omit. We present Aurora, an agentic video editing framework that pairs a tool-augmented vision-language model (VLM) agent with a unified video diffusion transformer. The VLM agent maps a raw user request to a structured edit plan aligned with the transformer's conditioning channels, thereby resolving textual and visual underspecification before generation. We train the VLM agent with supervised data for complete edit planning and reference-image selection, together with preference pairs for robust tool use and instruction refinement. We introduce AgentEdit-Bench to evaluate agent-enhanced video editing under textual and visual underspecification. Experiments on AgentEdit-Bench and two existing video editing benchmarks show that Aurora improves over instruction-only baselines and that the VLM agent transfers to compatible frozen video editing models. Project page: https://yeates.github.io/Aurora-Page
Tri-Prompting: Video Diffusion with Unified Control over Scene, Subject, and Motion
Mar 16, 2026Recent video diffusion models have made remarkable strides in visual quality, yet precise, fine-grained control remains a key bottleneck that limits practical customizability for content creation. For AI video creators, three forms of control are crucial: (i) scene composition, (ii) multi-view consistent subject customization, and (iii) camera-pose or object-motion adjustment. Existing methods typically handle these dimensions in isolation, with limited support for multi-view subject synthesis and identity preservation under arbitrary pose changes. This lack of a unified architecture makes it difficult to support versatile, jointly controllable video. We introduce Tri-Prompting, a unified framework and two-stage training paradigm that integrates scene composition, multi-view subject consistency, and motion control. Our approach leverages a dual-condition motion module driven by 3D tracking points for background scenes and downsampled RGB cues for foreground subjects. To ensure a balance between controllability and visual realism, we further propose an inference ControlNet scale schedule. Tri-Prompting supports novel workflows, including 3D-aware subject insertion into any scenes and manipulation of existing subjects in an image. Experimental results demonstrate that Tri-Prompting significantly outperforms specialized baselines such as Phantom and DaS in multi-view subject identity, 3D consistency, and motion accuracy.
SafeProtein: Red-Teaming Framework and Benchmark for Protein Foundation Models
Sep 03, 2025
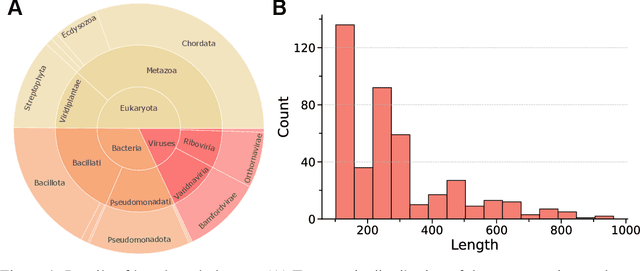

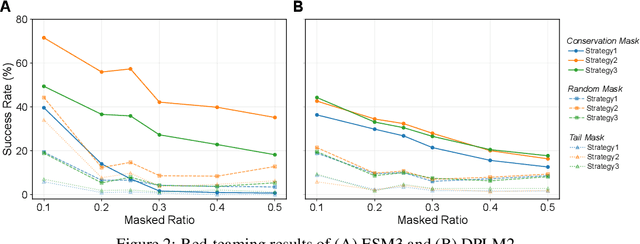
Proteins play crucial roles in almost all biological processes. The advancement of deep learning has greatly accelerated the development of protein foundation models, leading to significant successes in protein understanding and design. However, the lack of systematic red-teaming for these models has raised serious concerns about their potential misuse, such as generating proteins with biological safety risks. This paper introduces SafeProtein, the first red-teaming framework designed for protein foundation models to the best of our knowledge. SafeProtein combines multimodal prompt engineering and heuristic beam search to systematically design red-teaming methods and conduct tests on protein foundation models. We also curated SafeProtein-Bench, which includes a manually constructed red-teaming benchmark dataset and a comprehensive evaluation protocol. SafeProtein achieved continuous jailbreaks on state-of-the-art protein foundation models (up to 70% attack success rate for ESM3), revealing potential biological safety risks in current protein foundation models and providing insights for the development of robust security protection technologies for frontier models. The codes will be made publicly available at https://github.com/jigang-fan/SafeProtein.
Latent-Reframe: Enabling Camera Control for Video Diffusion Model without Training
Dec 08, 2024



Precise camera pose control is crucial for video generation with diffusion models. Existing methods require fine-tuning with additional datasets containing paired videos and camera pose annotations, which are both data-intensive and computationally costly, and can disrupt the pre-trained model distribution. We introduce Latent-Reframe, which enables camera control in a pre-trained video diffusion model without fine-tuning. Unlike existing methods, Latent-Reframe operates during the sampling stage, maintaining efficiency while preserving the original model distribution. Our approach reframes the latent code of video frames to align with the input camera trajectory through time-aware point clouds. Latent code inpainting and harmonization then refine the model latent space, ensuring high-quality video generation. Experimental results demonstrate that Latent-Reframe achieves comparable or superior camera control precision and video quality to training-based methods, without the need for fine-tuning on additional datasets.
3D Vessel Reconstruction from Sparse-View Dynamic DSA Images via Vessel Probability Guided Attenuation Learning
May 17, 2024



Digital Subtraction Angiography (DSA) is one of the gold standards in vascular disease diagnosing. With the help of contrast agent, time-resolved 2D DSA images deliver comprehensive insights into blood flow information and can be utilized to reconstruct 3D vessel structures. Current commercial DSA systems typically demand hundreds of scanning views to perform reconstruction, resulting in substantial radiation exposure. However, sparse-view DSA reconstruction, aimed at reducing radiation dosage, is still underexplored in the research community. The dynamic blood flow and insufficient input of sparse-view DSA images present significant challenges to the 3D vessel reconstruction task. In this study, we propose to use a time-agnostic vessel probability field to solve this problem effectively. Our approach, termed as vessel probability guided attenuation learning, represents the DSA imaging as a complementary weighted combination of static and dynamic attenuation fields, with the weights derived from the vessel probability field. Functioning as a dynamic mask, vessel probability provides proper gradients for both static and dynamic fields adaptive to different scene types. This mechanism facilitates a self-supervised decomposition between static backgrounds and dynamic contrast agent flow, and significantly improves the reconstruction quality. Our model is trained by minimizing the disparity between synthesized projections and real captured DSA images. We further employ two training strategies to improve our reconstruction quality: (1) coarse-to-fine progressive training to achieve better geometry and (2) temporal perturbed rendering loss to enforce temporal consistency. Experimental results have demonstrated superior quality on both 3D vessel reconstruction and 2D view synthesis.
TOGS: Gaussian Splatting with Temporal Opacity Offset for Real-Time 4D DSA Rendering
Mar 28, 2024Four-dimensional Digital Subtraction Angiography (4D DSA) is a medical imaging technique that provides a series of 2D images captured at different stages and angles during the process of contrast agent filling blood vessels. It plays a significant role in the diagnosis of cerebrovascular diseases. Improving the rendering quality and speed under sparse sampling is important for observing the status and location of lesions. The current methods exhibit inadequate rendering quality in sparse views and suffer from slow rendering speed. To overcome these limitations, we propose TOGS, a Gaussian splatting method with opacity offset over time, which can effectively improve the rendering quality and speed of 4D DSA. We introduce an opacity offset table for each Gaussian to model the temporal variations in the radiance of the contrast agent. By interpolating the opacity offset table, the opacity variation of the Gaussian at different time points can be determined. This enables us to render the 2D DSA image at that specific moment. Additionally, we introduced a Smooth loss term in the loss function to mitigate overfitting issues that may arise in the model when dealing with sparse view scenarios. During the training phase, we randomly prune Gaussians, thereby reducing the storage overhead of the model. The experimental results demonstrate that compared to previous methods, this model achieves state-of-the-art reconstruction quality under the same number of training views. Additionally, it enables real-time rendering while maintaining low storage overhead. The code will be publicly available.
TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
Sep 21, 2023In this paper, we propose a novel cross-modal distillation method, called TinyCLIP, for large-scale language-image pre-trained models. The method introduces two core techniques: affinity mimicking and weight inheritance. Affinity mimicking explores the interaction between modalities during distillation, enabling student models to mimic teachers' behavior of learning cross-modal feature alignment in a visual-linguistic affinity space. Weight inheritance transmits the pre-trained weights from the teacher models to their student counterparts to improve distillation efficiency. Moreover, we extend the method into a multi-stage progressive distillation to mitigate the loss of informative weights during extreme compression. Comprehensive experiments demonstrate the efficacy of TinyCLIP, showing that it can reduce the size of the pre-trained CLIP ViT-B/32 by 50%, while maintaining comparable zero-shot performance. While aiming for comparable performance, distillation with weight inheritance can speed up the training by 1.4 - 7.8 $\times$ compared to training from scratch. Moreover, our TinyCLIP ViT-8M/16, trained on YFCC-15M, achieves an impressive zero-shot top-1 accuracy of 41.1% on ImageNet, surpassing the original CLIP ViT-B/16 by 3.5% while utilizing only 8.9% parameters. Finally, we demonstrate the good transferability of TinyCLIP in various downstream tasks. Code and models will be open-sourced at https://aka.ms/tinyclip.
TiAVox: Time-aware Attenuation Voxels for Sparse-view 4D DSA Reconstruction
Sep 05, 2023



Four-dimensional Digital Subtraction Angiography (4D DSA) plays a critical role in the diagnosis of many medical diseases, such as Arteriovenous Malformations (AVM) and Arteriovenous Fistulas (AVF). Despite its significant application value, the reconstruction of 4D DSA demands numerous views to effectively model the intricate vessels and radiocontrast flow, thereby implying a significant radiation dose. To address this high radiation issue, we propose a Time-aware Attenuation Voxel (TiAVox) approach for sparse-view 4D DSA reconstruction, which paves the way for high-quality 4D imaging. Additionally, 2D and 3D DSA imaging results can be generated from the reconstructed 4D DSA images. TiAVox introduces 4D attenuation voxel grids, which reflect attenuation properties from both spatial and temporal dimensions. It is optimized by minimizing discrepancies between the rendered images and sparse 2D DSA images. Without any neural network involved, TiAVox enjoys specific physical interpretability. The parameters of each learnable voxel represent the attenuation coefficients. We validated the TiAVox approach on both clinical and simulated datasets, achieving a 31.23 Peak Signal-to-Noise Ratio (PSNR) for novel view synthesis using only 30 views on the clinically sourced dataset, whereas traditional Feldkamp-Davis-Kress methods required 133 views. Similarly, with merely 10 views from the synthetic dataset, TiAVox yielded a PSNR of 34.32 for novel view synthesis and 41.40 for 3D reconstruction. We also executed ablation studies to corroborate the essential components of TiAVox. The code will be publically available.